- Introduction
- Features
- Installation
- Model Quantization
- Performance Evaluation
- Acknowledgements
- License
This project demonstrates how to deploy YOLOv5s on an iOS device with FP16 quantization to achieve efficient inference while maintaining high accuracy.

- Efficient object detection on iOS devices
- FP16 quantization for optimized performance
- Real-time inference capability
- Easy-to-follow installation and usage instructions
First, download the official YOLOv5s weights from the YOLOv5 repository:
wget https://github.com/ultralytics/yolov5/releases/download/v6.0/yolov5s.ptUse the YOLOv5 official GitHub export script to convert the model to CoreML with FP16 quantization:
git clone https://github.com/ultralytics/yolov5.git
cd yolov5
pip install -r requirements.txt
# Export to CoreML with FP16 quantization
python export.py --weights yolov5s.pt --img 640 --batch 1 --device 0 --include coreml --halfThis will generate a .mlpackage file.
- Open Xcode and create a new project or open an existing one.
- Drag and drop the
.mlpackagefile into your Xcode project. - Ensure the model is added to the target.
The model was exported using the YOLOv5 official export script with FP16 quantization enabled. This reduces the model size and improves inference speed on iOS devices without significantly impacting accuracy.
- The model achieves real-time inference on iPhone 12 mini with an average speed of 37.8 FPS.
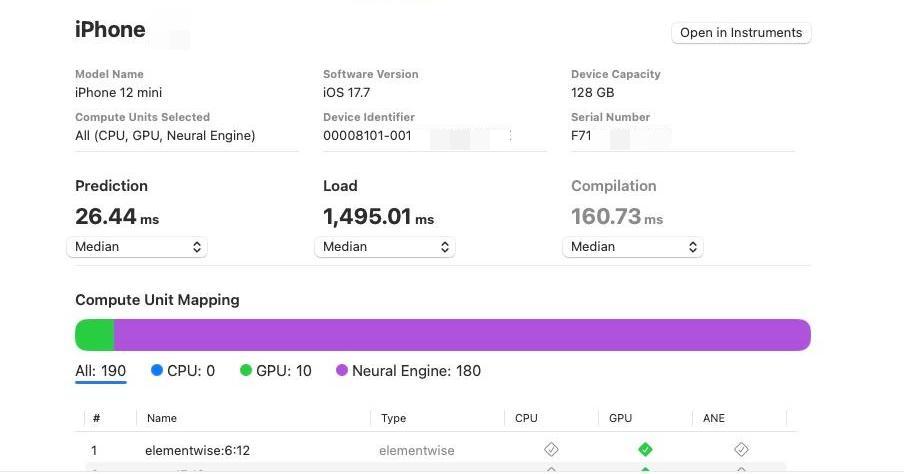

- The FP16 quantized model maintains high accuracy with minimal loss compared to the original FP32 model.
This project is based on the excellent work by the YOLOv5 team. Special thanks to the contributors and the open-source community. Additionally, this project was inspired by and references the blog post by Julius Hietala on YOLOv5 CoreML.
This project is licensed under the MIT License - see the LICENSE file for details.