
지은 |

재연 |

영준 |

다혜 |

윤진 |
토큰 단위 분석을 넘어 문장 단위, 그리고 문서 단위에서의 분석은 자연어 처리에서의 주요한 작업입니다. 이러한 과정들의 가장 기본이 되는 문장간의 관계 분석은 필수적이고, 이번 대회는 문장 간의 유사도를 분석하는 우수한 성능의 모델을 제작하는 것을 목적으로 합니다. Slack, 네이버 영화 리뷰, 국민청원에서 수집한 문장쌍 약 9천개가 대회 진행을 위한 데이터셋으로 제공됩니다.

(팀 구성 및 컴퓨팅 환경) 5인 1팀, 인당 V100 서버를 VScode 또는 JupyterLab에서 사용
(협업 환경) Notion, Github
(의사소통) 카카오톡, Zoom, Slack
- 권지은 - 영어 토큰 전처리 실험, 하이퍼파라미터 탐색 시도
- 김재연 - 특수문자 관련 전처리 실험, 모델 리서치, 모델 성능 실험, 모델 앙상블 구현
- 박영준 - 하이퍼파라미터 탐색 시도, 모델 리서치, 앙상블 모델 튜닝
- 정다혜 - 데이터 불균형 해소 실험, 데이터 증강 실험, 불용어 처리
- 최윤진 - 데이터 증강 실험, 하이퍼파라미터 탐색 시도, 맞춤범 검사 실험
(4/10 ~ 4/13) 강의 다 듣기. 프로젝트 베이스라인 코드 분석
(4/14 ~ 4/17) 데이터셋 분석, 전처리
(4/18 ~ 4/20) 모델 개선

- 데일리스크럼과 피어 세션 때 각자의 진행 상황과 다음 실험 계획을 공유한다.
- 공유할 내용은 바로 슬랙에 올리고, 이모지로 읽음 표시를 한다.
- Github Issue에 가설, 실험 코드, 실험 결과 및 오류를 공유한다.
- Github에 각자 작업한 코드를 새로운 브랜치, 자신의 이름 폴더에 올린다
- 노션에 해야 할 일, 결과를 정리한다.
- KLUE의 Semantic Textual Similarity(STS) 데이터셋
- 입력 : 두 문장
- 출력 : 두 문장의 유사도
- 학습 데이터 : 11,668개
- 검증 데이터 : 519개(평가 데이터가 비공개이므로 학습에서 평가데이터로 활용)
- 평가 데이터 : 1,037개(비공개)
- License : Creative Commons Attribution-ShareAlike 4.0 International License.
프로젝트 목표 - Semantic Text Similarity (STS)
- STS란 두 텍스트가 얼마나 유사한지 판단하는 NLP Task를 말한다.
- 여기서, 두 문장이 서로 동등한 양방향성을 가짐을 가정하고 진행
- 문맥적 유사도를 0과 5사이로 측정한 데이터에 대하여 유사도 점수를 예측하는 것을 목적으로 한다.
데이터 예시
train.csv
| index | id | source | sentence_1 | sentence_2 | label | binary-label |
|---|---|---|---|---|---|---|
| 0 | boostcamp-sts-v1-train-000 | nsmc-sampled | 스릴도있고 반전도 있고 여느 한국영화 쓰레기들하고는 차원이 다르네요~ | 반전도 있고,사랑도 있고재미도있네요. | 2.2 | 0.0 |
| 1 | boostcamp-sts-v1-train-001 | slack-rtt | 앗 제가 접근권한이 없다고 뜹니다;; | 오, 액세스 권한이 없다고 합니다. | 4.2 | 1.0 |
| ... | ... | ... | ... | ... | ... | ... |
| 9323 | boostcamp-sts-v1-train-9323 | petition-sampled | 법정공휴일 휴무관련 (근로자) | 법정공휴일의 유급휴무화를 막아야 합니다. | 1.4 | 0.0 |
9324 rows × 6 columns
-
target 데이터인 ‘label’ 분포 확인
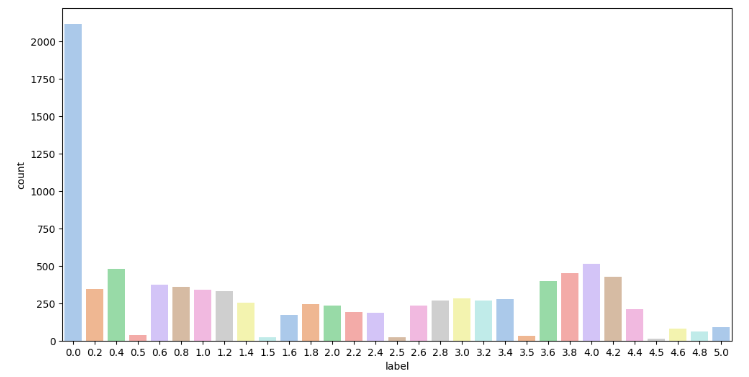
유사도가 0인 데이터가 상당 비율을 차지하며 , n.5인 label이 상대적으로 적게 분포되어있다.


-
영어 토큰 처리 (1) 번역기: googletrans, facebook/mbart-large-50-one-to-many-mmt (2) 문장 번역, 단어 번역을 실험했다. googletrans로 단어를 번역한 결과와 아무것도 하지 않은 결과가 가장 좋았다. 또한, (3) 영어 단어 번역, 삭제 (4) 맞춤법 검사 유무를 실험했다. 맞춤법 검사 후 영어 단어를 번역한 결과가 가장 좋았다.
-
불용어 처리
문장의 의미에 큰 영향을 주지 않는 불용어처리를 통해 모델의 성능을 개선할 수 있다는 가설을 세워 불용어 처리를 두 사전을 정의하여 진행하였다.
-
직접정의
모든 문장을 토큰화하여 200번 이상 등장한 토큰에 대하여 불용어로 판단되는 토큰을 회의를 통해 불용어 사전에 정의하였다. 이를 전처리에 적용하여 모델의 성능을 평가한 결과 성능향상에 큰 기여를 하지 못하였다.
직접 정의한 사전 : ['도', '들', '이', '~', '가', '해주세요', '.', '으로', '!!', '..', '은', '요', '입니다', '!', '그', '의', '너무', '만', '에', '로', '는', '에서', '을', '?', '이런', '정말', '것', '와', '진짜', '게', 'ㅎㅎ', '하는', '를', '에게', '하고', '주세요’, …………]
-
인터넷에서 불용어 사전 찾기
인터넷에서 적절한 불용어 사전을 찾아 불용어 사전에 정의하였다. 두개의 사전을 전처리에 적용하여 모델의 성능을 평가한 결과 오히려 성능을 떨어뜨린다(약 0.06🔻)는 결과를 도출하였다.
이를 통해 한국어 전처리에서 모델의 특성, 데이터의 특성을 파악하여 불용어를 정의해야한다는 점을 알게되었고, 오히려 성능을 저하할 수 있다고 판단하여 따로 불용어 처리를 진행하지 않기로 결정하였다.
-
-
데이터 불균형 해소
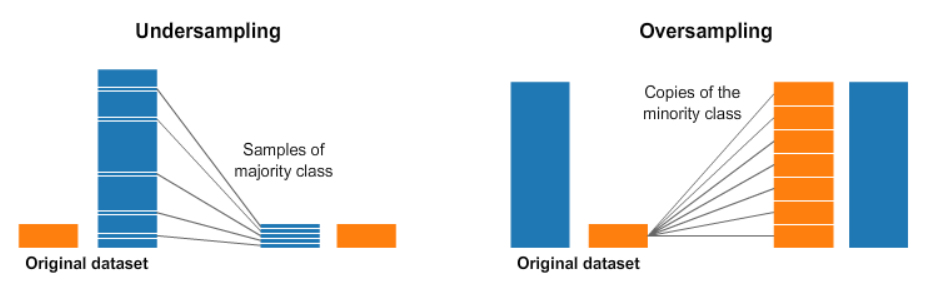
앞서 언급한 EDA결과로 데이터 불균형 해소를 위해 oversampling과 undersampling을 시도하였다.
-
oversampling - smote sampling
smote sampling은 라벨링 문제로 실패하였다. over sampling을 하려면 기존 데이터를 통해 새로운 데이터를 만들어내야하기 때문에 인코딩이 필요한데, 데이터가 문장인 점에서 불가능하기 때문이다. 추후에 해당 내용을 공유하여 조언을 얻었는데, 임베딩 후 smote sampling을 적용할 수 있다는 점을 알았고 다음 프로젝트때 도전하고싶다.
-
undersampling - RandomUnderSampler
RandomUnderSampler을 적용하여 모델성능을 확인해 본 결과 데이터 손실로 인해 성능이 떨어진다는 점을 알게되었다.
따라서 불균형해소 없이 진행하기로 결정하였다.
-
-
역번역을 통한 데이터 증강
‘역변역을 통한 데이터 증강으로 모델 성능을 개선시킬 수 있다’는 가설을 세워 데이터 증강 실험을 진행하였다. 데이터 증강을 위해 한국어-영어-한국어 역번역 시행 도중 크롤링과정에서 접근거부 이슈로 직접 역번역을 통한 증강을 결정하였다. 1000개의 데이터에 대하여 증강하였고, 증강 전후 모델 성능을 비교한 결과 증강 전 모델의 성능이 약 0.88인 반면 증강 후 약0.86의 성능을 보이며 가설과는 반대 결과를 도출하였다. 따라서 데이터 증강을 하지 않기로 결정하였다.
-
특수문자 처리
re-space: 특수 문자 공백 처리, raw-text: 기존 텍스트, re-none: 특수 문자 제거
re-fix-1: 특수 문자 개수 1개로 고정, re-fix-2: 연속된 특수 문자 개수 2개로 고정
re-space raw-text re-none re-fix-1 re-fix-2 top val pearson 0.8758 0.8739 0.8674 0.8626 0.8507 min val loss 0.5272 0.5631 0.5571 0.5540 0.5759 KLUE의 데이터셋에 특수 문자가 거의 포함되어 있지 않아서, 특수 문자의 의미를 파악하지 못한 것으로 분석하였다.
그렇기 때문에, 특수 문자를 모두 공백 처리하는 것이 토큰화 및 학습에 좋을 것이라는 결론을 도출하였다.
-
라벨 정규화(0
5 ⇒ -11)학습의 안정적인 진행을 위해 도입 시도
실험 결과
모델 lr batch size epoch public score private score 정규화 전 ys7yoo/sentence-roberta-large-kor-sts 1e-5 16 23 0.9068 0.9292 정규화 후 ys7yoo/sentence-roberta-large-kor-sts 1e-5 16 24 0.9012 0.9311 라벨 정규화를 적용한 데이터로 학습한 모델이 새로운 데이터에 대한 추론 성능이 좋다고 판단
-
koeda 라이브러리를 이용한 데이터 증강 koeda 라이브러리의 EDA 클래스를 이용하여 기존 데이터 셋의 일부를 유의어 교체, 일부 단어 삭제, 신규 단어 추가 등의 데이터 증강을 실시하였다. 유의어 교체, 무작위 삽입, 유의어 삽입, 유의어 삭제의 비율을 바꿔가며 실험하였지만 유의미한 결과는 얻지 못했다.
-
맞춤법 검사 맞춤법이 맞지 않는 문장들을 hanspell 라이브러리를 이용하여 맞춤법 전처리를 하여 fine-tuning 하면 학습이 더 잘 될것이라는 가설을 세웠다. roberta-small 모델을 이용하여 batch-size:16, epoch:10, lr:1e-5 로 수행한 결과 성능이 떨어짐을 확인하였다.
-
어순 바꿔서 데이터 증강 처리 단어의 순서가 학습에 영향을 줄거라는 가설을 세우고 데이터 어순을 바꿔 데이터셋을 2배로 증강 시켜 fine-tuning 을 했으나 성능 향상은 없었다.

-
최종 모델
klue/roberta-large ys7yoo/sentence-roberta-large-kor-sts jhgan/ko-sbert-sts sentence-transformers/xlm-r-large-en-ko-nli-ststb
모델들 모두 문장 단위로 기학습 되었고, 문장 유사도 분석을 위한 문장 쌍으로 기학습된 모델을 사용했습니다.
앙상블 기법을 적용할 때, 앙상블의 효과를 크게 만들기 위해 위와 같은 기학습 모델을 사용하였고,
사용된 베이스라인 모델 종류는 Roberta, Bert, XlmRoberta입니다.
-
Sweep 을 통한 하이퍼 파라메터 결과 분석
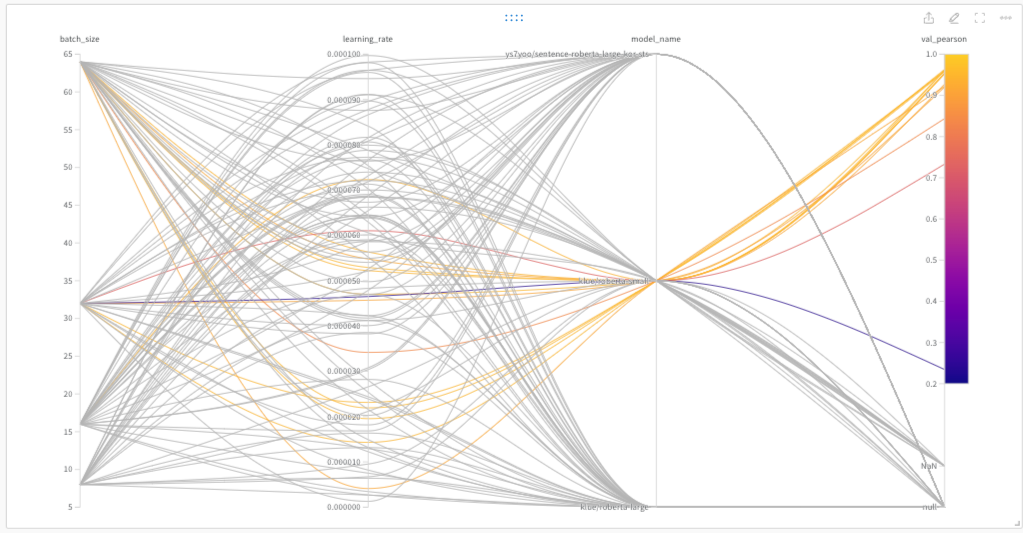
klue/roberta-small,klue/roberta-large, ys7yoo/sentence-roberta-large-kor-sts모델에 대하여 batch-size는 8, 16, 32, 64 의 범위로, learning_rate 는 0.0001 ~ 0.00001 균등 분포로 sweep 을 적용한 것. cuda memory 에러와 val_pearson = NAN 해결을 하지 못해klue/roberta-large,ys7yoo/sentence-roberta-large-kor-sts의 경우는 모두 NAN과 null 의 결과가 나왔다.jhgan/ko-sbert-sts,sentence-transformers/xlm-r-large-en-ko-nli-ststb도 위 하이퍼파라미터 범위와 학습률 [1e-6, 1e-4]와 [5e-6, 5e-5]에 대해 sweep 했지만 모두 NAN의 결과가 나왔다.]

-
앙상블
- 배깅 기법 사용
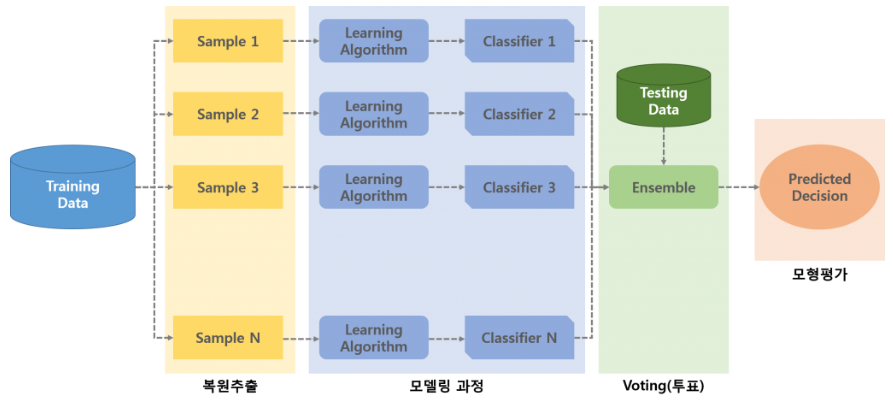
boostrap 샘플링을 통해 10개의 샘플을 만들어 10개의 klue/roberta-large 모델을 불러와 각각의 샘플에 대해서 fine-tuning을 진행하였다. 각각의 모델에서 output을 만들고 평균을 내어(soft-voting) 최종 유사도를 도출했다.
모델 lr batch size epoch public score private score 배깅 기법 전 klue/roberta-large 1e-5 16 23 0.9068 0.9264 배깅 기법 후 klue/roberta-large 1e-5 16 24 0.9106 0.9284

- 전처리: 특수문자 공백 처리 + 라벨 정규화
- 모델: 4개 앙상블 - klue/roberta-large, ys7yoo/sentence-roberta-large-kor-sts, jhgan/ko-sbert-sts, sentence-transformers/xlm-r-large-en-ko-nli-ststb
- 하이퍼파라미터: batch size 16, lr 1e-5
- pearson 점수: 0.9196 (public) → 0.9339 (private)

- 각자 EDA를 진행한 후 데이터셋에 대한 각자의 시각을 공유했다.
- 전처리 가설을 브레인스토밍하고 바로 역할 분담을 했다.
- 어떤 실험을 진행할 지 회의하며 담당할 실험을 정한 후 기한에 맞춰 실험 내용을 공유했다.
- 각자 실험한 내용에 대해서 서로 토의해보며 추후 모델 발전 방안을 모색했다.
- 깃허브 이슈로 가설, 실험 결과, 문제 등을 관리했다.
- 성능에 집착한게 아니라 가설을 세우고 작업했다는 측면에서 성장에 초점에 맞춰서 진행했다.
- 에러가 생겼을 때 해결법을 최대한 구하려고 같의 토의했다.
- 대회 마지막까지 최선을 다했다.
- 맞춤법 교정, 영어 단어 번역과 같은 전처리 과정이 성능에 생각보다 도움이 되지 못했다.
- 불용어 처리가 생각보다 성능에 도움이 되지 않았다.
- 역번역 과정에서 오류가 많이 나서 제대로 반영하지 못했다.
- val_pearson 이 NAN으로 나오는 문제를 해결 못했다.
- 가설들이 더 잘 맞았더라면 성능이 더 좋았을 것이라는 아쉬운 점이 있다.
- 깃허브와 노션으로 협업을 진행했는데 우리 팀에 더 맞는 방식이 있을 것 같다.
- 아직 대회 진행과 관련된 깃허브 관리가 익숙하지 않았다.
- 노션에 실험한 하이퍼파라미터를 적는 표가 있었지만 잘 활용하지 못 한 것 같다.
- Wandb Sweep 을 더 빨리 적용했다면 좋았을 거 같다.
- Wandb Sweep으로 다양한 파라미터 튜닝을 시도했지만 결과가 다 NAN으로 나왔다.
- 앙상블 모델을 많이 시도해보지 못해봤다.
- Pytorch Lightning 라이브러리 사용이 더 익숙해졌다.
- 실험을 통해 가설을 증명하고, 증명이 실패했다면 그 이유를 분석하는 과정을 통해 이론적으로 더 배울 수 있었다.
- 실험에 적절한 모델을 찾아보는 안목을 기를 수 있었다.
- 에러가 나면 이를 분석하고 디버깅하는 과정을 공유하며 코드 작성에 익숙해질 수 있었다.
- 프로젝트의 전반적인 프로세스를 경험할 수 있어서 좋았다.
- Wandb을 통해 실험 결과를 기록할 수 있는 방법을 배웠다.
- Sweep 을 통한 하이퍼 파라메터 튜닝 방법을 배웠다.
- 딥러닝 코드에서는 매우 사소한 부분이 생각보다 많은 걸 바꾼 다는 걸 알았다.