인공지능 기술이 빠르게 발전하면서 이미지 처리 분야에서의 경쟁도 치열해지고 있습니다. 특히, 최신 AI 모델들은 객체 탐지, 광학 문자 인식(OCR), 이미지 추론 등 다양한 작업을 통해 일상생활과 산업 전반에 혁신을 가져오고 있습니다. 이러한 기술 진보의 흐름 속에서, 최근 공개된 Claude 3 API는 특히 주목할 만한 기능을 제공합니다. 2024년 3월 4일에 발표된 Claude 3는 Vision 기능을 포함하고 있어, 이미지 처리 분야에서 기존의 GPT-4와 같은 모델과의 성능 비교가 가능합니다. 이번 글에서는 Claude 3의 Vision 기능을 활용한 이미지 처리 작업의 효율성과 성능을 직접 알아보도록 하겠습니다.
Claude Python 라이브러리를 설치할 차례입니다. 설치를 위해 다음 명령어를 실행하세요. 필요한 모든 의존성과 함께 라이브러리의 최신 버전을 설치합니다.
pip install anthropicimport anthropic
import os
import httpx
import base64
import imghdr
import io
from PIL import Image as PILImage
import matplotlib.pyplot as plt
from pathlib import Path만약 API 키 생성 및 설정 방법에 대해 자세히 알고 싶으시다면, 이전 글에서 제공된 안내를 참고하시기 바랍니다. 이전 글에서는 Claude API 접근을 위한 계정 생성부터 API 키 발급 및 환경 변수 설정에 이르기까지의 과정을 자세히 설명하고 있습니다.
api_key = os.environ.get("ANTHROPIC_API_KEY")
client = anthropic.Anthropic(api_key=api_key)def load_and_encode_images(paths):
encoded_images = []
for path in paths:
media_type = None # 초기값은 None으로 설정
# URL인 경우
if path.startswith('http'):
response = httpx.get(path)
image_data = response.content
# URL에서 파일 확장자 추출
file_extension = Path(path).suffix.lower()
if file_extension in ['.jpg', '.jpeg']:
media_type = "image/jpeg"
elif file_extension in ['.png']:
media_type = "image/png"
else:
print(f"Unsupported media type for URL: {path}")
continue # 지원하지 않는 파일 형식인 경우, 건너뛰기
response.close()
# 로컬 파일 경로인 경우
else:
with open(path, "rb") as image_file:
image_data = image_file.read()
img_type = imghdr.what(None, h=image_data)
if img_type == "jpeg":
media_type = "image/jpeg"
elif img_type == "png":
media_type = "image/png"
else:
print(f"Unsupported file format: {path}")
continue # 지원하지 않는 파일 형식인 경우, 건너뛰기
if media_type:
# Base64 인코딩 후 저장
encoded_image = base64.b64encode(image_data).decode("utf-8")
encoded_images.append({
"type": "image",
"media_type": media_type,
"data": encoded_image,
})
return encoded_images
def create_prompt_with_images(encoded_images, text):
content = []
for image in encoded_images:
# 이미지 객체 구조를 API 요구사항에 맞게 조정
content.append({
"type": "image",
"source": {
"type": "base64", # 'type' 키를 'base64'로 명시
"media_type": image["media_type"], # 이미지의 미디어 타입
"data": image["data"], # Base64 인코딩된 이미지 데이터
},
})
content.append({
"type": "text",
"text": text, # 질문 또는 설명 텍스트
})
prompts = [{
"role": "user",
"content": content,
}]
return prompts
def display_response(images, text):
for image in images:
img_data = base64.b64decode(image["data"])
img = PILImage.open(io.BytesIO(img_data))
plt.imshow(img)
plt.axis('off')
plt.show()
print("Response:", text)
# 예시 사용
def chat_with_images_and_text(image_urls, text_question):
# 이미지 인코딩
encoded_images = load_and_encode_images(image_urls)
# 질문 생성
prompts = create_prompt_with_images(encoded_images, text_question)
# Anthropics API를 통해 답변 받기 (가상의 함수, 실제 API 호출 구현 필요)
response = client.messages.create(model="claude-3-opus-20240229", max_tokens=1024, messages=prompts)
# 응답에서 텍스트 내용만 추출
result_text = ""
for content_block in response.content:
if content_block.type == "text":
result_text += content_block.text + "\n"
# 답변 표시
display_response(encoded_images, result_text)
return response이 예제는 이미지 목록과 텍스트 질문을 Claude API에 전송하여, 주어진 이미지에 대한 설명을 요청하는 간단한 질문입니다. 사용자는 이미지 URL 리스트를 제공하고, 이 이미지들에 대한 설명을 요구하는 텍스트 질문을 포함하여 API에 요청을 보냅니다. Claude API는 제공된 이미지들을 분석하고, 이에 대한 자세한 설명을 생성하여 응답합니다.
# 이미지 URL 리스트
image_paths = [
"https://upload.wikimedia.org/wikipedia/commons/a/a7/Camponotus_flavomarginatus_ant.jpg",
"https://upload.wikimedia.org/wikipedia/commons/b/b5/Iridescent.green.sweat.bee1.jpg"
]
# 질문
text_question = "Describe these images."
# 함수 실행
response = chat_with_images_and_text(image_paths, text_question)
Response: The first image shows an extreme close-up of an ant against a plain brown background. The ant appears to be standing on its hind legs with its front legs raised, likely in a defensive or aggressive posture. The details of the ant's exoskeleton, including its segmented body, antennae, and mandibles, are clearly visible due to the high magnification and sharp focus of the photograph.
The second image depicts a green metallic sweat bee covered in tiny water droplets, likely from morning dew or rain. The bee's iridescent exoskeleton shimmers with hues of green, blue and gold against the orange background, creating a striking color contrast. The water droplets on its fuzzy body and wings add an interesting texture and catch the light, further enhancing the visual appeal of the photograph. The image showcases the intricate beauty and detail of this small insect.
이 예제는 Claude API를 사용하여 주어진 이미지들에서 차량 모델을 분류하고 설명하는 과정을 보여줍니다. 사용자는 차량 이미지 경로를 리스트 형태로 API에 제공하고, 각 차량의 모델을 분석하여 반환하도록 요청하는 텍스트 질문을 함께 전송합니다.
image_paths = ["asset/images/test_1.png", "asset/images/test_2.png"]
text_question = "주어진 두 이미지를 분석하여 각각 차량의 모델을 반환합니다."
response = chat_with_images_and_text(image_paths, text_question)
Response: 첫번째 이미지는 Mercedes-Benz GLC 클래스 SUV 모델이고, 두번째 이미지는 Hyundai Palisade SUV 모델입니다.
두 차량 모두 고급스러운 외관 디자인을 가지고 있으며, 가족용 대형 SUV 차량의 특징을 잘 보여주고 있습니다. Mercedes-Benz GLC는 프리미엄 브랜드의 고급스러움을 강조한 반면, Hyundai Palisade는 보다 대중적인 디자인을 추구한 것으로 보입니다.
이 예제는 Claude API를 사용하여 주어진 이미지(여기서는 방정식이 포함된 이미지)를 분석하고, 해당 방정식의 용도와 사용 방법에 대해 설명하는 요청을 보내는 과정을 보여줍니다. 사용자는 방정식이 담긴 이미지의 경로와 "이 방정식은 무엇을 위한 것인가요? 사용방법을 설명해 주세요"라는 텍스트 질문을 API에 전송합니다.
API의 응답은 방정식이 표현하는 수학적 개념이나 과학적 원리를 해석하고, 그것이 어떻게 사용될 수 있는지에 대한 설명을 포함할 것입니다. 예를 들어, 방정식이 특정 물리 법칙을 나타내는 경우, 해당 법칙의 의미와 실제 적용 예를 제공할 수 있습니다.
image_paths = ["asset/images/test_3.png"]
text_question = "이 방정식은 무엇을 위한 것인가요? 사용방법을 설명해주세요"
response = chat_with_images_and_text(image_paths, text_question)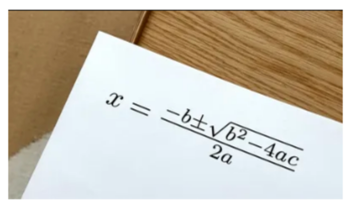
Response: 이 방정식은 2차 방정식의 일반적인 형태입니다. 2차 방정식은 ax^2 + bx + c = 0의 형태로 표현되며, 여기서 a, b, c는 실수이고 a는 0이 아닙니다.
2차 방정식을 풀기 위해서는 다음과 같은 방법을 사용할 수 있습니다:
1. 인수분해 (factoring): 방정식을 인수분해하여 (ax + m)(bx + n) = 0의 형태로 만들고, 각 인수를 0으로 만드는 x값을 찾습니다.
2. 근의 공식 (quadratic formula): 근의 공식 x = (-b ± √(b^2 - 4ac)) / 2a 를 사용하여 x의 값을 직접 계산합니다.
3. 완전제곱 (completing the square): x^2 + (b/a)x 형태가 되도록 방정식을 변형한 후, 제곱식을 완성하여 x에 대해 풉니다.
2차 방정식은 그래프로 나타내면 포물선 모양이 됩니다. 이 포물선이 x축과 만나는 점의 x좌표가 바로 2차 방정식의 해, 즉 근이 됩니다. 근의 개수는 판별식 b^2 - 4ac의 값에 따라 달라집니다.
2차 방정식은 물리학, 공학, 경제학 등 다양한 분야에서 활용되며, 최적화 문제나 운동 방정식 등을 해결하는 데 사용됩니다.
한 가지 예제를 더 살펴보겠습니다. 두 개의 이미지를 비교하고, 첫 번째 이미지에 있는 사람이 두 번째 이미지에서 몇 번 위치에 해당하는지 찾아내는 작업을 요청합니다. 하지만 아래처럼 잘못된 답변이 제공될 수 있습니다. AI 모델이 항상 100% 정확한 결과를 보장하지 않으며, 이미지의 품질, 복잡성, 주어진 질문의 명확성 등 여러 요소에 따라 성능이 달라질 수 있기 때문입니다.
image_paths = ["asset/images/test_4.png", "asset/images/test_5.png"]
text_question = "첫 번째 이미지의 사람이 두 번째 이미지에 몇 번에 해당하는지 찾아서 번호만 알려주세요."
response = chat_with_images_and_text(image_paths, text_question)
Response: The man in the first image is wearing a shirt with bears on it, which matches portrait number 2 in the second image grid.