Domain yang dipilih untuk proyek machine learning ini adalah Kesehatan, dengan judul Predictive Analytics : Diagnosa Kanker Pankreas Berdasarkan Biomarker Urin
- Latar Belakang
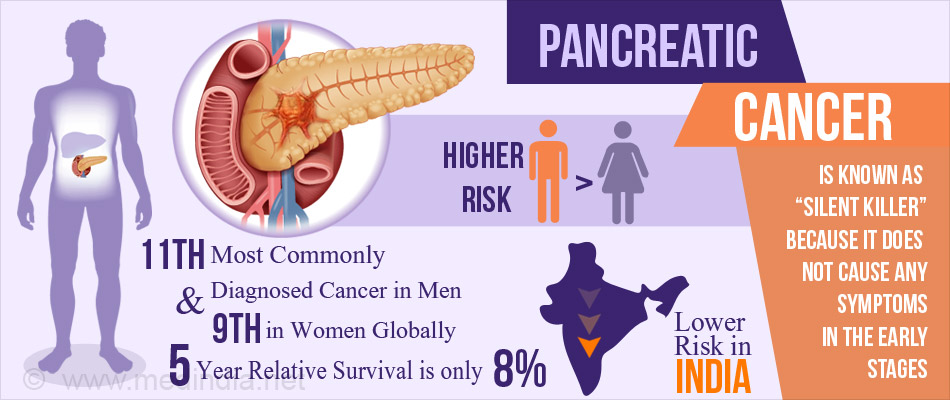
Kanker pankreas adalah jenis kanker yang sangat mematikan. Setelah didiagnosis, tingkat kelangsungan hidup lima tahun kurang dari 10% [1]. Namun, jika kanker pankreas terdeteksi lebih awal, kemungkinan bertahan hidup jauh lebih baik. Sayangnya, banyak kasus kanker pankreas tidak menunjukkan gejala hingga kanker menyebar ke seluruh tubuh. Tes diagnostik untuk mengidentifikasi orang dengan kanker pankreas bisa sangat membantu.
Berdasarkan latar belakang di atas, berikut ini merupakan rincian masalah yang dapat diselesaikan pada proyek ini:
- Bagaimana membuat model machine learning yang dapat memprediksi atau mendiagnosis kanker pankreas pada pasien berdasarkan data biomarker urin?
- Model yang seperti apa yang memiliki akurasi paling baik?
Tujuan dari proyek ini adalah:
- Membuat model machine learning yang dapat memprediksikan pasien apakah terdiagnosis kanker pankreas atau tidak, berdasarkan biomarker urin.
- Membandingkan beberapa algoritma model sehingga ditemukan akurasi yang paling baik untuk memprediksikan diagnosis kanker pankreas berdasarkan biomarker urin.
Untuk mencapai tujuan tersebut, dalam proyek ini akan dibuat beberapa model yang berbeda untuk dibandingkan, diantaranya adalah menggunakan:
- K-Nearest Neighbor (KNN) adalah algoritma sederhana yang mengklasifikasikan data atau kasus baru berdasarkan ukuran kesamaan. Hal ini sebagian besar digunakan untuk mengklasifikasikan titik data berdasarkan tetangga terdekatnya sebagai acuan [2].
- Random Forest adalah algoritma machine learning yang kuat yang dapat digunakan untuk berbagai tugas termasuk regresi dan klasifikasi. Ini adalah metode ensemble, yang berarti bahwa model random forest terdiri dari banyak decision tree kecil, yang disebut estimator, yang masing-masing menghasilkan prediksi mereka sendiri. Random forest menggabungkan prediksi estimator untuk menghasilkan prediksi yang lebih akurat [3].
- Support Vector Machine (SVM) adalah algoritma yang digunakan untuk menemukan hyperplane dalam ruang N-dimensi (N - jumlah fitur) yang secara jelas mengklasifikasikan titik data. SVM dapat digunakan untuk menyelesaikan permasalahan klasifikasi, regresi, dan pendeteksian outlier [4].
- Naive Bayes adalah model machine learning probabilistik yang digunakan untuk tugas klasifikasi. Inti dari classifier ini didasarkan pada teorema Bayes [5].
Dataset yang digunakan dalam proyek ini adalah data hasil sampel tes urin yaitu sebanyak 590 sampel. Data ini dapat diunduh melalui Kaggle. Pada dataset ini terdapat 14 kolom, diantaranya:
sample_id: merupakan string unik yang mengidentifikasi setiap subjekpatient_cohort: menyatakan kelompok pasien, memiliki 2 nilai, yaitu Cohort 1, sampel yang sebelumnya digunakan; Cohort 2, sampel yang baru ditambahkansample_origin: menyatakan sumber sampel dataage: menyatakan usia pasien dalam tahunsex: menyatakan jenis kelamin pasien (M=Pria, F=Wanita)diagnosis: menyatakan diagnosis (1=sehat, 2=benign hepatobiliary disease/bukan kanker, 3=kanker pankreas)stage: menyatakan tingkat kanker pankreas yang diderita pasien (IA, IB, IIA, IIIB, III, IV)benign_sample_diagnosis: diagnosis untuk mereka penderita benign hepatobiliary disease / non-kankerplasma_CA19_9: Kadar plasma darah dari antibodi monoklonal CA 19-9 yang sering meningkat pada pasien dengan kanker pankreas.creatinine: Biomarker urin dari fungsi ginjalLYVE1: Tingkat urin reseptor Lymphatic vessel endothelial hyaluronan 1, protein yang mungkin berperan dalam metastasis tumorREG1B: Kadar protein urin yang mungkin terkait dengan regenerasi pankreasTFF1: Tingkat urin Trefoil Factor 1, yang mungkin terkait dengan regenerasi dan perbaikan saluran kemih.REG1A: Kadar protein urin yang mungkin berhubungan dengan regenerasi pankreas.

Informasi Dataset:
| Jenis | Keterangan |
|---|---|
| Title | Urinary biomarkers for pancreatic cancer |
| Source | Kaggle |
| Maintainer | John Davis |
| License | Data files © Original Authors |
| Visibility | Public |
| Tags | biology, cancer, health conditions, beginner, binary classification, medicine |
| Usability | 10.0 |
Teknik yang digunakan dalam penyiapan data (Data Preparation) yaitu:
- Penanganan Missing Values. Pada kasus dataset ini ada beberapa kolom dengan missing values yang tidak sedikit dan akan berisiko besar jika sampelnya dihapus. Salah satu teknik yang dapat diterapkan yaitu dengan melakukan imputasi atau nilai pengganti [6]. Pada proyek ini nilai pengganti yang digunakan adalah nilai mean atau rata-rata.
- One-Hot Encoding merupakan teknik untuk merepresentasikan variabel atau fitur kategorikan ke dalam vektor biner [7].
- Mendeteksi outliers. Outliers adalah titik data yang berbeda secara signifikan dari pengamatan lainnya sehingga dapat berakibat buruk pada model prediksi. Pada proyek ini menggunakan IQR (InterQuartile Range) untuk mendeteksi outliers [8]. IQR dapat menentukan data outliers yang kondisinya di luar batas bawah atau batas atas dari dataset [9]. IQR dapat divisualkan menggunakan boxplot.
- Split Data atau pembagian dataset menjadi data latih dan data uji menggunakan bantuan train_test_split. Pembagian dataset ini bertujuan agar nantinya dapat digunakan untuk melatih dan mengevaluasi kinerja model. Pada proyek ini, 80% dataset digunakan untuk melatih model, dan 20% sisanya digunakan untuk mengevaluasi model.
- Normalisasi. Pada proyek ini menggunakan MinMaxScaler, yaitu teknik normalisasi yang mentransformasikan nilai fitur atau variabel ke dalam rentang [0,1] yang berarti bahwa nilai minimum dan maksimum dari fitur/variabel masing-masing adalah 0 dan 1 [10].
Pada tahap modeling ini dibuat beberapa model dengan algoritma yang berbeda-beda. Pada proyek ini akan dibuat 4 model, diantaranya yaitu menggunakan KNN, Random Forest, SVM, dan Naive Bayes. Setelah melatih keempat model tersebut, didapatkan metriks akurasi sebagai berikut seperti pada diagram di bawah ini.

Dari hasil tersebut dapat diketahui bahwa model dengan algoritma Random Forest memiliki kinerja yang lebih baik. Untuk itu model tersebut yang akan dipilih untuk digunakan.
Pada proyek ini, model yang dibuat merupakan kasus klasifikasi dan menggunakan metriks akurasi.
Akurasi merupakan kalkulasi presentase jumlah ketepatan prediksi dari jumlah seluruh data yang diprediksi. Nilai akurasi dapat dihitung dengan rumus berikut.

[1] Debernardi S, O’Brien H, Algahmdi AS, Malats N, Stewart GD, Plješa-Ercegovac M, et al. (2020). A combination of urinary biomarker panel and PancRISK score for earlier detection of pancreatic cancer: A case–control study. PLoS Med 17(12): e1003489. https://doi.org/10.1371/journal.pmed.1003489
[2] Subramanian, D. (2019). A Simple Introduction to K-Nearest Neighbors Algorithm. Towards Data Science. https://towardsdatascience.com/a-simple-introduction-to-k-nearest-neighbors-algorithm-b3519ed98e
[3] Wood, T. -.What is a Random Forest?. DeepAI. https://deepai.org/machine-learning-glossary-and-terms/random-forest
[4] Gandhi, R. (2018). Support Vector Machine — Introduction to Machine Learning Algorithms: SVM model from scratch. Towards Data Science. https://towardsdatascience.com/support-vector-machine-introduction-to-machine-learning-algorithms-934a444fca47
[5] Gandhi, R. (2018). Naive Bayes Classifier. Towards Data Science. https://towardsdatascience.com/naive-bayes-classifier-81d512f50a7c
[6] Gifari, J. (2020). Teknik Pengolahan Data : Mengenal Missing Values dan Cara-Cara Menanganinya. DQLab. https://dqlab.id/digital-transformation-pahami-teknik-pengolahan-ini-dalam-industri-data
[7] Luna, Z. (2021). One-Hot Encoding Categorical Variables — What is it? Why is it? How is it?. Medium. https://medium.com/analytics-vidhya/one-hot-encoding-categorical-variables-what-is-it-why-is-it-how-is-it-6fd9ed3a161
[8] Setiawan, S. (2020). Mendeteksi Univariate Outliers dengan Metode IQR (Python). Medium. https://stevkarta.medium.com/mendeteksi-univariate-outliers-dengan-metode-iqr-python-3adfad87de82
[9] Setiawan, S. (2020). Statistik Deskriptif dengan Python. Medium. https://stevkarta.medium.com/statistik-deskriptif-dengan-python-5cac5c752627
[10] Loukas, S. (2020). Everything you need to know about Min-Max normalization: A Python tutorial. Towards Data Science. https://towardsdatascience.com/everything-you-need-to-know-about-min-max-normalization-in-python-b79592732b79