DataHarvest 是一个用于数据搜索🔍、爬取🕷、清洗🧽的工具。
AI时代,数据是一切的基石,DataHarvest 能够帮助快速获取干净有效的数据,开箱即用,灵活配置。
除了工具本身之外,我们还会搜集整理一些技术方案,整理成wiki。

| 搜索引擎 | 官网 | 支持 |
|---|---|---|
| tavily | https://docs.tavily.com/ | ✅ |
| 天工搜索 | https://www.tiangong.cn/ | ✅ |
| 网站 | 内容 | url pattern | 爬取 | 清洗 |
|---|---|---|---|---|
| 百度百科 | 词条 | baike.baidu.com/item/ | ✅ | ✅ |
| 百度百家号 | 文章 | baijiahao.baidu.com/s/ | ✅ | ✅ |
| B站 | 文章 | www.bilibili.com/read/ | ✅ | ✅ |
| 腾讯网 | 文章 | new.qq.com/rain/a/ | ✅ | ✅ |
| 360个人图书馆 | 文章 | www.360doc.com/content/ | ✅ | ✅ |
| 360百科 | 词条 | baike.so.com/doc/ | ✅ | ✅ |
| 搜狗百科 | 词条 | baike.sogou.com/v/ | ✅ | ✅ |
| 搜狐 | 文章 | www.sohu.com/a/ | ✅ | ✅ |
| 头条 | 文章 | www.toutiao.com/article/ | ✅ | ✅ |
| 网易 | 文章 | www.163.com/\w+/article/.+ | ✅ | ✅ |
| 微信公众号 | 文章 | weixin.qq.com/s/ | ✅ | ✅ |
| 马蜂窝 | 文章 | www.mafengwo.cn/i/ | ✅ | |
| 小红书 | 超链帖子 | /xhslink.com/ | ✅ | ✅ |
其他情况使用基础playwright数据爬取和html2text数据清洗,但并未做特殊适配。
pip install dataharvest
playwright install==注意使用时最好使用虚拟环境,以免不必要的麻烦==
分为搜索、爬虫、数据清洗三个主要模块,互相独立,您可以按需使用对应模块。
爬取和清洗做了根据URL的自动策略匹配,您只需要使用AutoSpider和AutoPurifier即可。
搜索+自动爬取+自动清洗
import asyncio
from dataharvest.base import DataHarvest
from dataharvest.searcher import TavilySearcher
searcher = TavilySearcher()
dh = DataHarvest()
r = searcher.search("战国水晶杯")
tasks = [dh.a_crawl_and_purify(item.url) for item in r.items]
loop = asyncio.get_event_loop()
docs = loop.run_until_complete(asyncio.gather(*tasks))from dataharvest.searcher import TavilySearcher
api_key = "xxx" # 或者设置环境变量 TAVILY_API_KEY
searcher = TavilySearcher(api_key)
searcher.search("战国水晶杯")SearchResult(keyword='战国水晶杯', answer=None, images=None, items=[
SearchResultItem(title='战国水晶杯_百度百科', url='https://baike.baidu.com/item/战国水晶杯/7041521', score=0.98661,
description='战国水晶杯为战国晚期水晶器皿,于1990年出土于浙江省杭州市半山镇石塘村,现藏于杭州博物馆。战国水晶杯高15.4厘米、口径7.8厘米、底径5.4厘米,整器略带淡琥珀色,局部可见絮状包裹体;器身为敞口,平唇,斜直壁,圆底,圈足外撇;光素无纹,造型简洁。',
content='')])
from dataharvest.spider import AutoSpider
url = "https://baike.so.com/doc/5579340-5792710.html?src=index#entry_concern"
auto_spider = AutoSpider()
doc = auto_spider.crawl(url)
print(doc)很多情况下我们需要配置代理,比如小红书和马蜂窝。 我们需要实现 一个代理生成类,并实现他的__call__方法。
可以在爬虫初始化时,将配置添加进去,也可以在调用时传入。
from dataharvest.proxy.base import BaseProxy, Proxy
from dataharvest.spider import AutoSpider
from dataharvest.spider.base import SpiderConfig
class MyProxy(BaseProxy):
def __call__(self) -> Proxy:
return Proxy(protocol="http", host="127.0.0.1", port="53380", username="username", password="password")
def test_proxy_constructor():
proxy_gene_func = MyProxy()
auto_spider = AutoSpider(config=SpiderConfig(proxy_gene_func=proxy_gene_func))
url = "https://baike.baidu.com/item/%E6%98%8E%E5%94%90%E5%AF%85%E3%80%8A%E7%81%8C%E6%9C%A8%E4%B8%9B%E7%AF%A0%E5%9B%BE%E8%BD%B4%E3%80%8B?fromModule=lemma_search-box"
doc = auto_spider.crawl(url)
print(doc)
def test_proxy_call():
proxy_gene_func = MyProxy()
auto_spider = AutoSpider()
config = SpiderConfig(proxy_gene_func=proxy_gene_func)
url = "https://baike.baidu.com/item/%E6%98%8E%E5%94%90%E5%AF%85%E3%80%8A%E7%81%8C%E6%9C%A8%E4%B8%9B%E7%AF%A0%E5%9B%BE%E8%BD%B4%E3%80%8B?fromModule=lemma_search-box"
doc = auto_spider.crawl(url, config=config)
print(doc)
from dataharvest.purifier import AutoPurifier
from dataharvest.spider import AutoSpider
url = "https://baike.so.com/doc/5579340-5792710.html?src=index#entry_concern"
auto_spider = AutoSpider()
doc = auto_spider.crawl(url)
print(doc)
auto_purifier = AutoPurifier()
doc = auto_purifier.purify(doc)
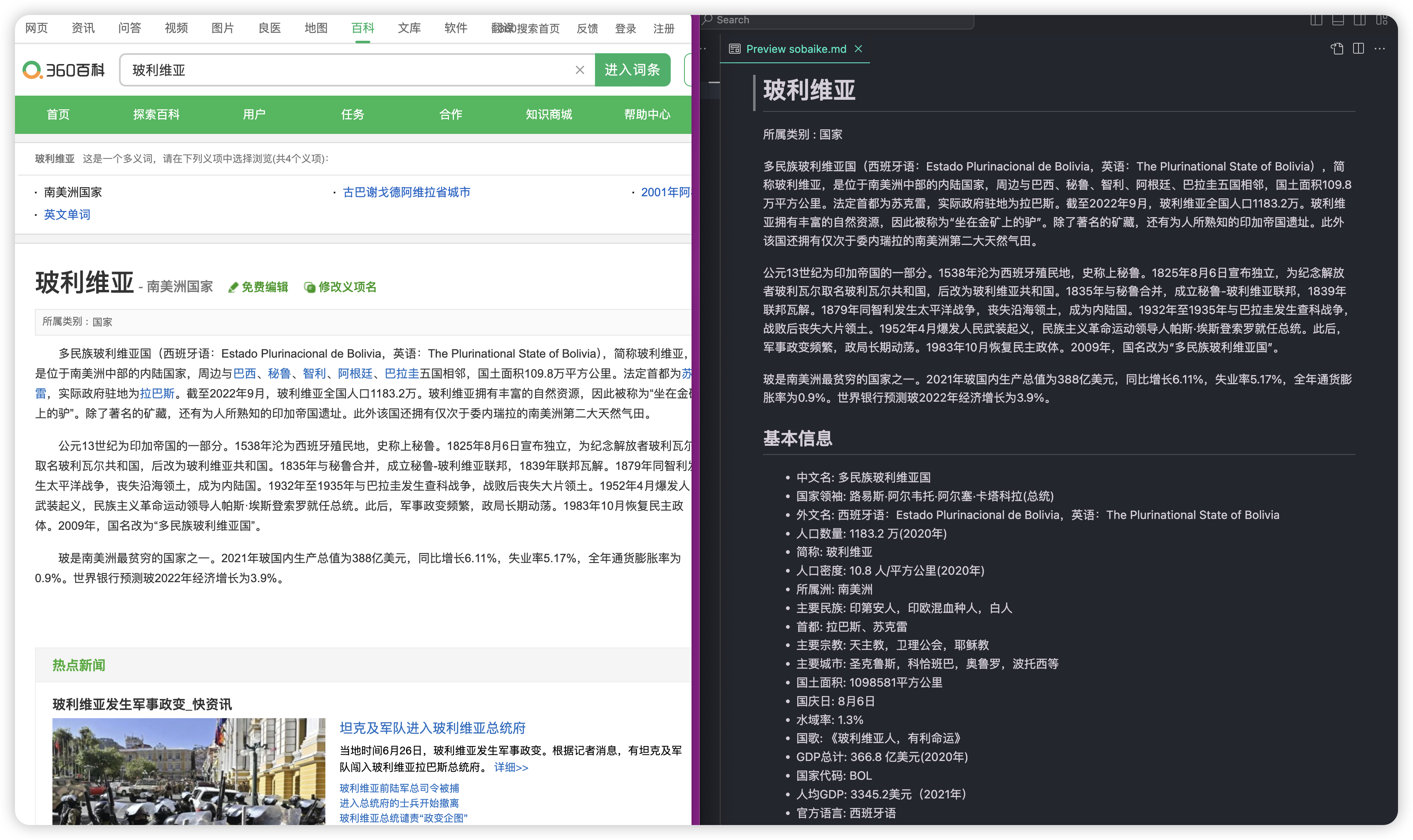
print(doc)效果:
伙伴们如果觉着这个项目对你有帮助,那么请帮助点一个star✨。如果觉着存在问题或者有其他需求,那么欢迎在issue提出。当然,我们非常欢迎您加入帮忙完善。