In memory of Kobe Bryant
"What can I say, Mamba out." — Kobe Bryant, NBA farewell speech, 2016

Image credit: https://www.ebay.ca/itm/264973452480
This is a PyTorch implementation of MambaOut proposed by our paper "MambaOut: Do We Really Need Mamba for Vision?".
-
20 May 2024: As suggested by Issue #5, we release MambaOut-Kobe model version with 24 Gated CNN blocks, achieving 80.0% accuracy on ImageNet. MambaOut-Kobe outperforms ViT-S by 0.2% accuracy with only 41% parameters and 33% FLOPs. See Models.
-
18 May 2024: Add a tutorial on counting Transformer FLOPs (Equation 6 in the paper).
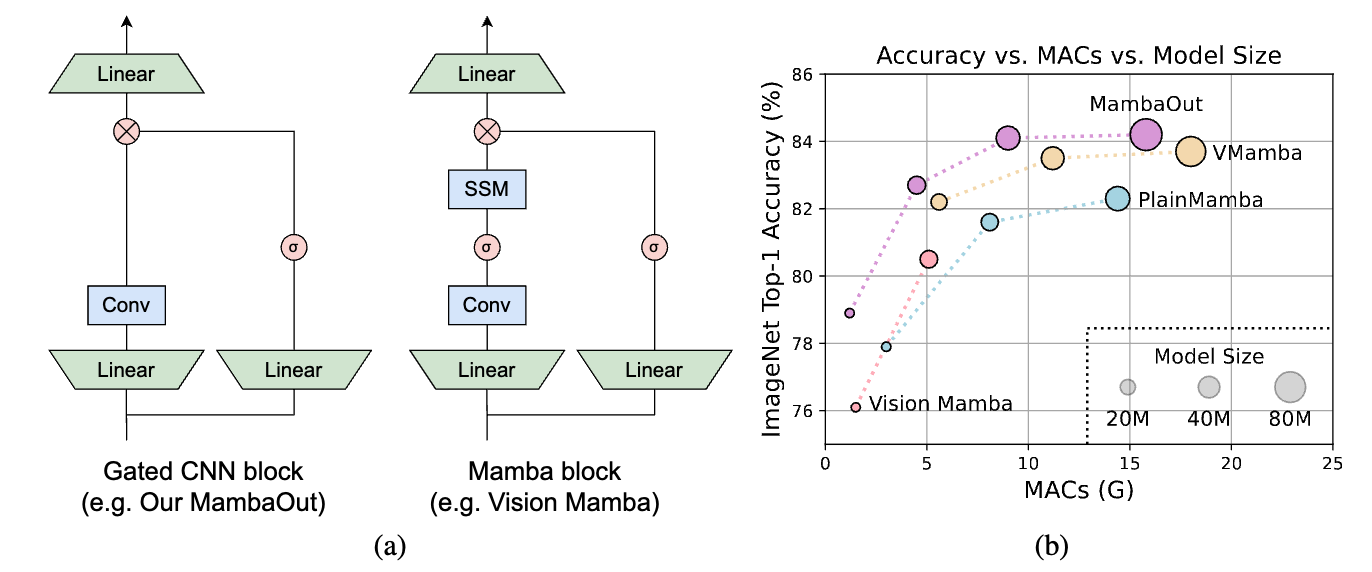 Figure 1: (a) Architecture of Gated CNN and Mamba blocks (omitting Normalization and shortcut). The Mamba block extends the Gated CNN with an additional state space model (SSM). As will be conceptually discussed in Section 3, SSM is not necessary for image classification on ImageNet. To empirically verify this claim, we stack Gated CNN blocks to build a series of models named MambaOut.(b) MambaOut outperforms visual Mamba models, e.g., Vision Mamhba, VMamba and PlainMamba, on ImageNet image classification.
Figure 1: (a) Architecture of Gated CNN and Mamba blocks (omitting Normalization and shortcut). The Mamba block extends the Gated CNN with an additional state space model (SSM). As will be conceptually discussed in Section 3, SSM is not necessary for image classification on ImageNet. To empirically verify this claim, we stack Gated CNN blocks to build a series of models named MambaOut.(b) MambaOut outperforms visual Mamba models, e.g., Vision Mamhba, VMamba and PlainMamba, on ImageNet image classification.
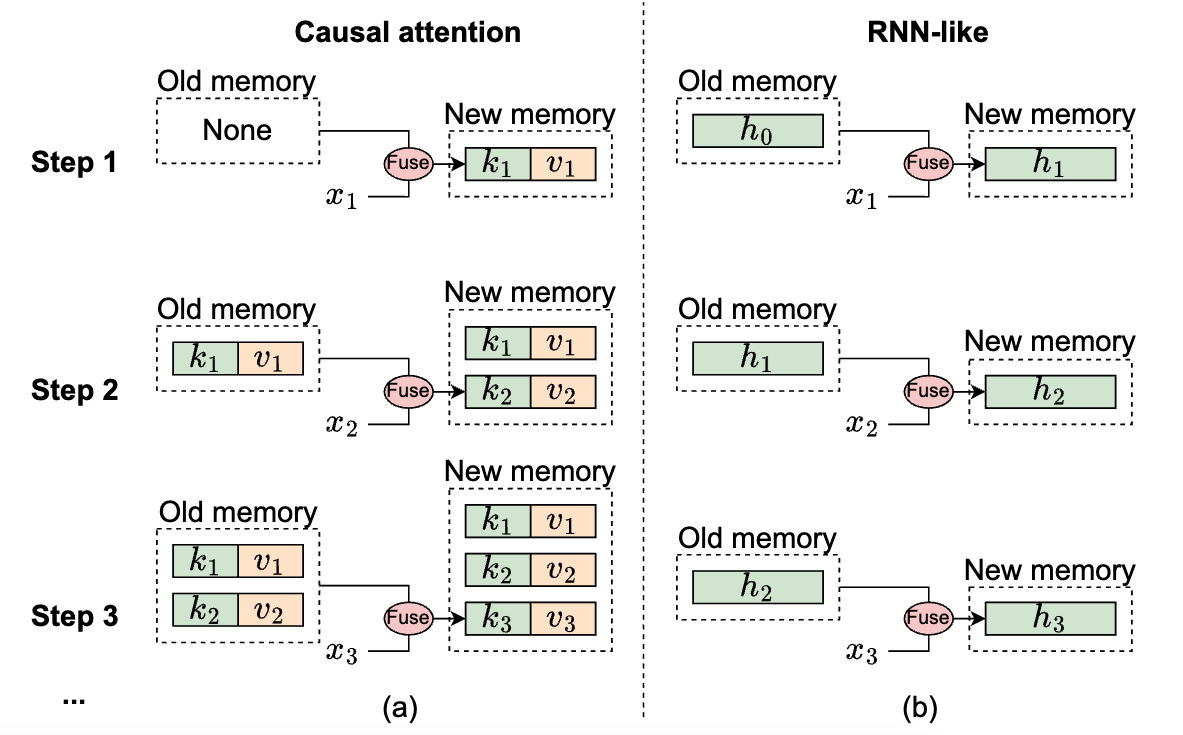 Figure 2: The mechanism illustration of causal attention and RNN-like models from memory perspective, where
Figure 2: The mechanism illustration of causal attention and RNN-like models from memory perspective, where
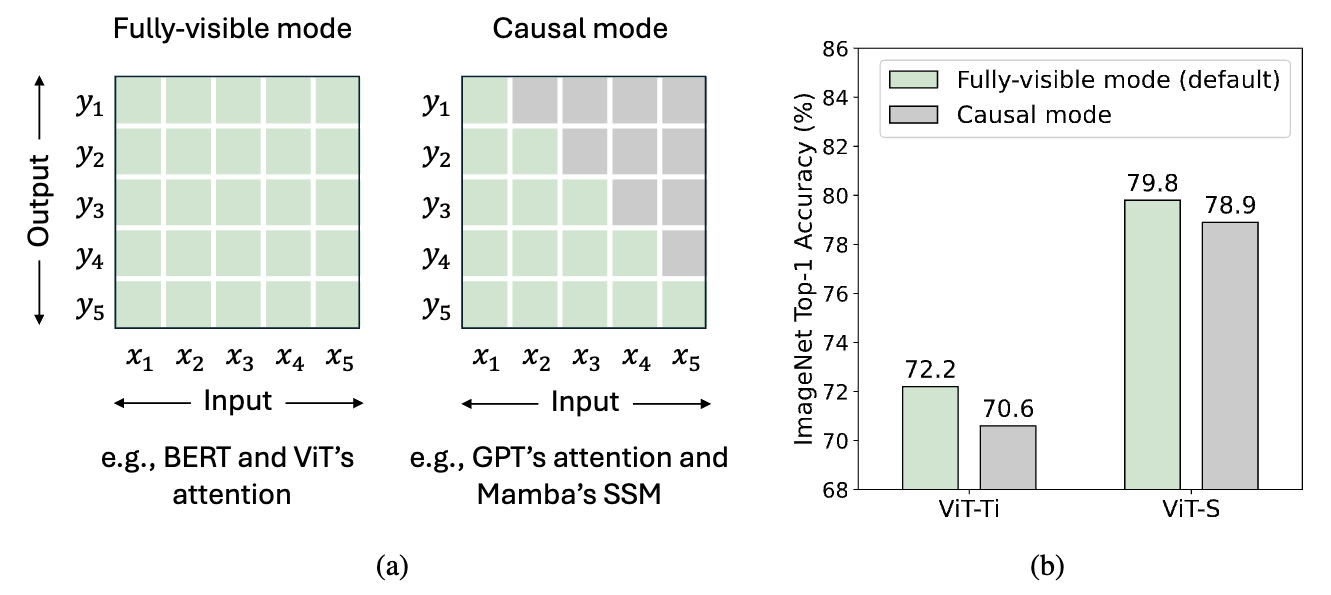 Figure 3: (a) Two modes of token mixing. For a total of
Figure 3: (a) Two modes of token mixing. For a total of
PyTorch and timm 0.6.11 (pip install timm==0.6.11).
Data preparation: ImageNet with the following folder structure, you can extract ImageNet by this script.
│imagenet/
├──train/
│ ├── n01440764
│ │ ├── n01440764_10026.JPEG
│ │ ├── n01440764_10027.JPEG
│ │ ├── ......
│ ├── ......
├──val/
│ ├── n01440764
│ │ ├── ILSVRC2012_val_00000293.JPEG
│ │ ├── ILSVRC2012_val_00002138.JPEG
│ │ ├── ......
│ ├── ......
| Model | Resolution | Params | MACs | Top1 Acc | Log |
|---|---|---|---|---|---|
| mambaout_femto | 224 | 7.3M | 1.2G | 78.9 | log |
| mambaout_kobe* | 224 | 9.1M | 1.5G | 80.0 | log |
| mambaout_tiny | 224 | 26.5M | 4.5G | 82.7 | log |
| mambaout_small | 224 | 48.5M | 9.0G | 84.1 | log |
| mambaout_base | 224 | 84.8M | 15.8G | 84.2 | log |
* Kobe Memorial Version with 24 Gated CNN blocks.
We also provide a Colab notebook which runs the steps to perform inference with MambaOut: .
A web demo is shown at . You can also easily run gradio demo locally. Besides PyTorch and timm==0.6.11, please install gradio by
pip install gradio, then run
python gradio_demo/app.pyTo evaluate models, run:
MODEL=mambaout_tiny
python3 validate.py /path/to/imagenet --model $MODEL -b 128 \
--pretrainedWe use batch size of 4096 by default and we show how to train models with 8 GPUs. For multi-node training, adjust --grad-accum-steps according to your situations.
DATA_PATH=/path/to/imagenet
CODE_PATH=/path/to/code/MambaOut # modify code path here
ALL_BATCH_SIZE=4096
NUM_GPU=8
GRAD_ACCUM_STEPS=4 # Adjust according to your GPU numbers and memory size.
let BATCH_SIZE=ALL_BATCH_SIZE/NUM_GPU/GRAD_ACCUM_STEPS
MODEL=mambaout_tiny
DROP_PATH=0.2
cd $CODE_PATH && sh distributed_train.sh $NUM_GPU $DATA_PATH \
--model $MODEL --opt adamw --lr 4e-3 --warmup-epochs 20 \
-b $BATCH_SIZE --grad-accum-steps $GRAD_ACCUM_STEPS \
--drop-path $DROP_PATH # --native-amp # can also use --native-amp or --amp to acclerate trainingTraining scripts of other models are shown in scripts.
This tutorial shows how to count Transformer FLOPs (Equation 6 in the paper). Welcome feedback, and I will continually improve it.
@article{yu2024mambaout,
title={MambaOut: Do We Really Need Mamba for Vision?},
author={Yu, Weihao and Wang, Xinchao},
journal={arXiv preprint arXiv:2405.07992},
year={2024}
}
Weihao was partly supported by Snap Research Fellowship, Google TPU Research Cloud (TRC), and Google Cloud Research Credits program. We thank Dongze Lian, Qiuhong Shen, Xingyi Yang, and Gongfan Fang for valuable discussions.
Our implementation is based on pytorch-image-models, poolformer, ConvNeXt, metaformer and inceptionnext.