JSFinder
JSFinder is a tool for quickly extracting URLs and subdomains from JS files on a website.
JSFinder是一款用作快速在网站的js文件中提取URL,子域名的工具。
提取URL的正则部分使用的是LinkFinder
JSFinder获取URL和子域名的方式:
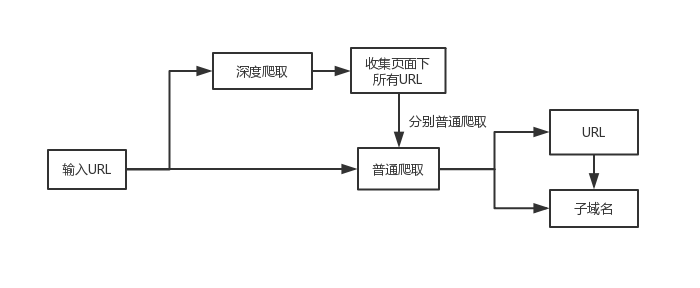
Blog: https://threezh1.com/
更新说明
- 增加油猴脚本用于在浏览器上访问页面时获取域名与接口,具体可见:https://github.com/Threezh1/Deconstruct/tree/main/DevTools_JSFinder
用法
- 简单爬取
python JSFinder.py -u http://www.mi.com
这个命令会爬取 http://www.mi.com 这单个页面的所有的js链接,并在其中发现url和子域名
返回示例:
url:http://www.mi.com
Find 50 URL:
http://api-order.test.mi.com
http://api.order.mi.com
http://userid.xiaomi.com/userId
http://order.mi.com/site/login?redirectUrl=
...已省略
Find 26 Subdomain:
api-order.test.mi.com
api.order.mi.com
userid.xiaomi.com
order.mi.com
...已省略
- 深度爬取
python JSFinder.py -u http://www.mi.com -d
深入一层页面爬取JS,时间会消耗的更长。
建议使用-ou 和 -os来指定保存URL和子域名的文件名。 例如:
python JSFinder.py -u http://www.mi.com -d -ou mi_url.txt -os mi_subdomain.txt
- 批量指定URL/指定JS
指定URL:
python JSFinder.py -f text.txt
指定JS:
python JSFinder.py -f text.txt -j
可以用brupsuite爬取网站后提取出URL或者JS链接,保存到txt文件中,一行一个。
指定URL或JS就不需要加深度爬取,单个页面即可。
- 其他
-c 指定cookie来爬取页面 例:
python JSFinder.py -u http://www.mi.com -c "session=xxx"
-ou 指定文件名保存URL链接 例:
python JSFinder.py -u http://www.mi.com -ou mi_url.txt
-os 指定文件名保存子域名 例:
python JSFinder.py -u http://www.mi.com -os mi_subdomain.txt
- 注意
url 不用加引号
url 需要http:// 或 https://
指定JS文件爬取时,返回的URL为相对URL
指定URL文件爬取时,返回的相对URL都会以指定的第一个链接的域名作为其域名来转化为绝对URL。
- 截图
实测简单爬取:
python3 JSFinder.py -u https://www.jd.com/
URL:
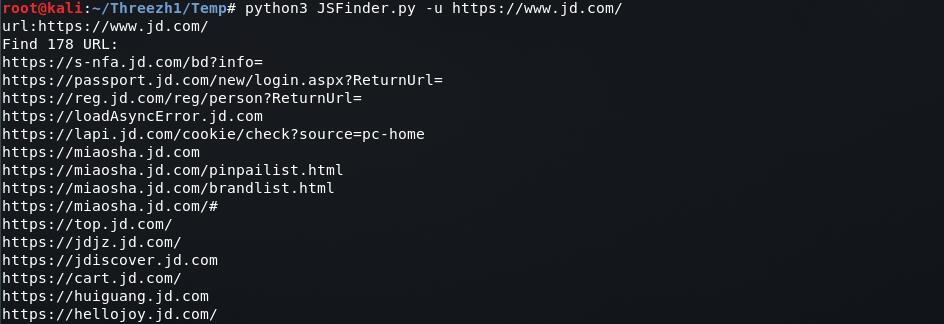
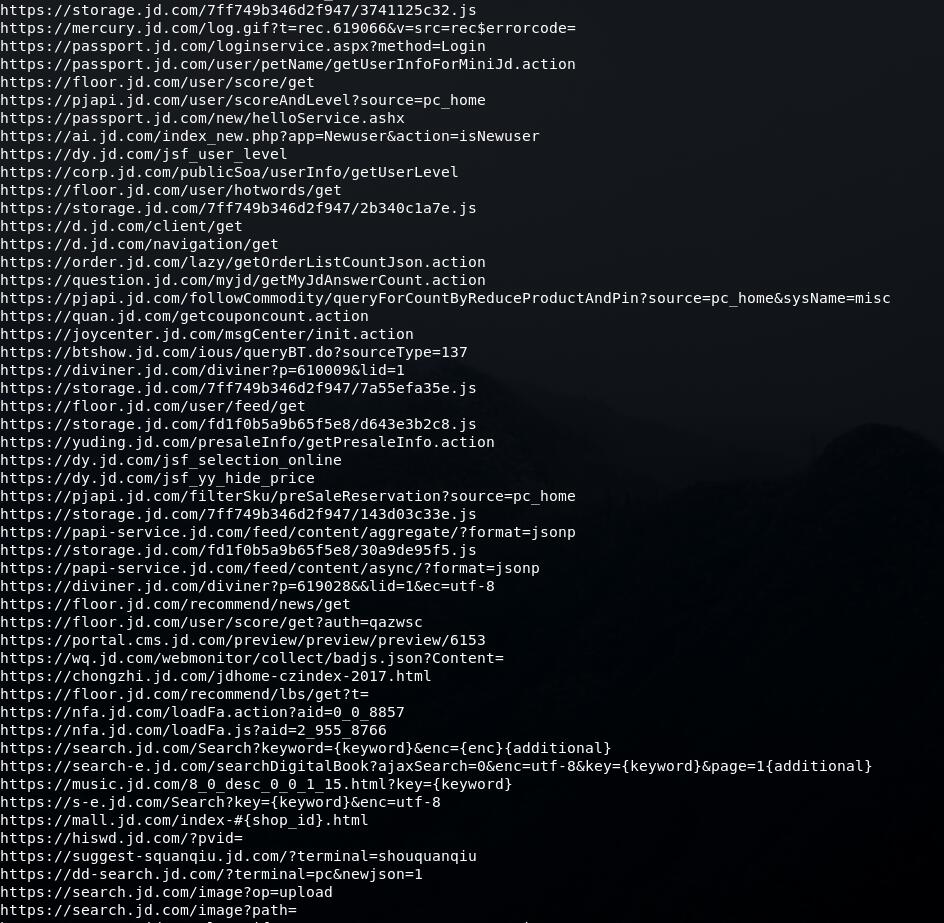
Subdomain:

实测深度爬取:
python3 JSFinder.py -u https://www.jd.com/ -d -ou jd_url.txt -os jd_domain.txt
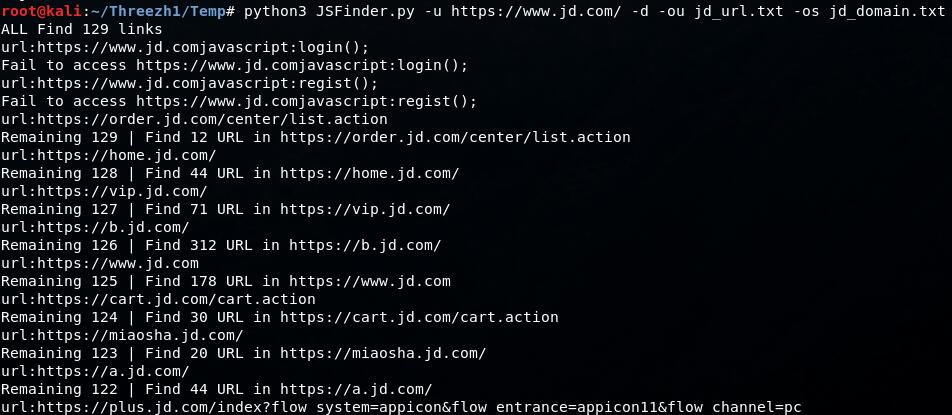

实际测试:
http://www.oppo.com
URL:4426 个
子域名:24 个
http://www.mi.com
URL:1043 个
子域名:111 个
http://www.jd.com
URL:3627 个
子域名:306 个