dataworks基础知识介绍+实操培训

-
- 20+种数据源
- 关系型数据库、大型数据存储、非结构化存储、NoSql数据库等,涵盖了90%以上的常用数据源
- 支持经典专有、混合等网络环境
- 集团外或者集团内
- 阿里云数据库实例或本地部署
- 公网可访问或不可访问
- 可视化配置与监控
- 向导模式
- shell+DataX
- 支持多种同步方式
- 实时或者批量
- 全量或者增量
- 同步速度视资源组而定,可横向扩展
- 20+种数据源
-
- 通过对以下数据抽取转换
- 关系型数据库 - SQL Server/PostergreSQL/梦达/DRDS/MYSQL/oracle/rds for ppas/db2
- MPP - HybridDB for Mysql/HybridDB for PostgreSQL
- 大数据存储
- Maxcompute/HDFS
- 非结构化存储
- OSS/FTP/多媒体文件
- NoSql
- HBASE/OTS/MongoDB
- 可跨公网,实时/离线导入
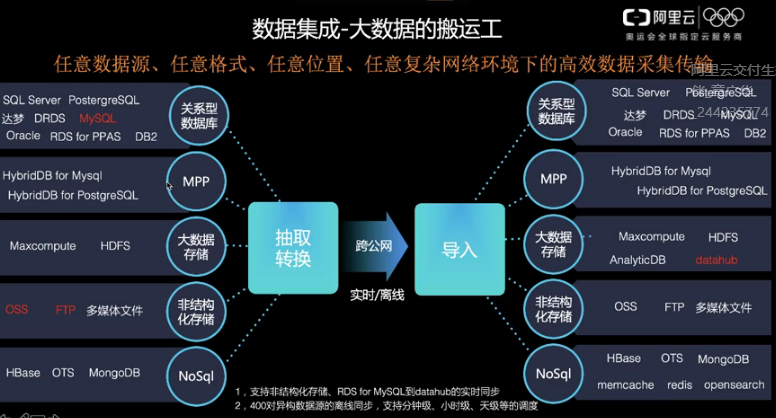
- 通过对以下数据抽取转换
-
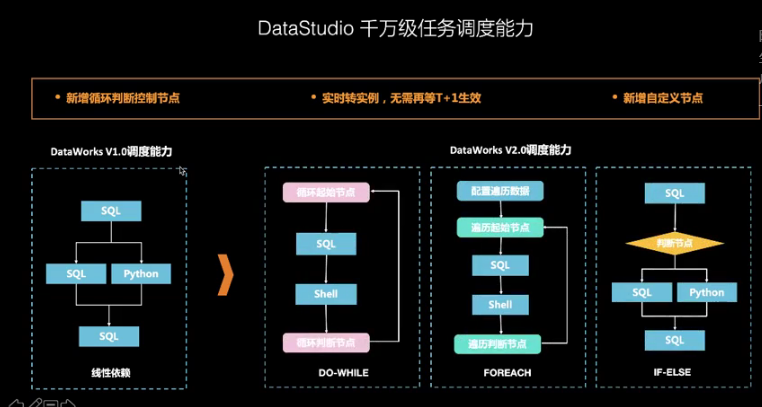
- DataStudio(DataWorks大数据综合数据开发工作室XStudio的核心-DataStudio:支持流批一体、AI、交互式查询和自定义引擎节点等跨赢取混编工作流可视化开发运维环境,可提供妙计可传参条件判断分支循环依赖大规模强保障周期调度能力的大数据综合开发工作平台,包括:大规模调度Alisa,智能运维,统一元数据等)
- 更友好、更高效、更智能的IDE
- 产品交互升级,全新炫酷皮肤,更易用
- 编辑器SQL输入智能提示,代码格式化和折叠
- SQL结构可视化展示和定位
- 拖拽式可视化DAG开发模式
- 基于DAG模式,提供可视化组件拖拽式流计算
- 任务“零代码”开发
- 新增循环判断控制节点
- 实时转实例,无需再等T+1生效
- 新增自定义节点
-
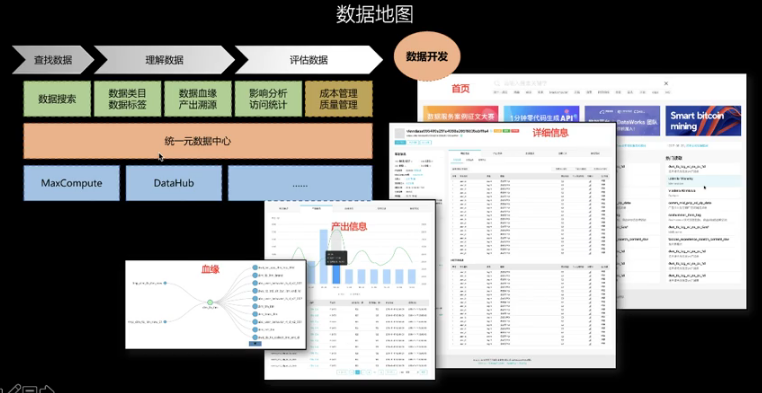
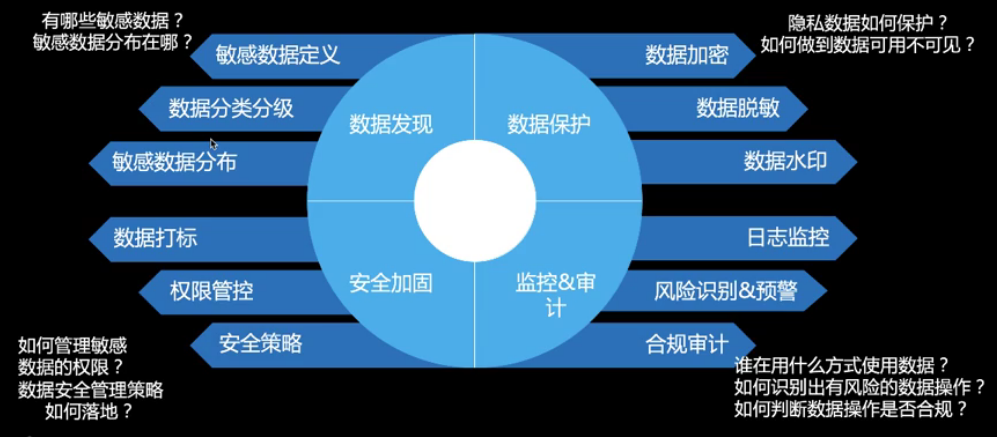
- 数据信息分散 - 业务系统不清晰,数据资产不明晰
- 元数据不全 - 需要有业务接口人,能维护补全业务信息
- 数据质量差 - 上传来的是一张空表,或者无效字段,总靠人肉来判别
- 维护困难 - 数据有问题,总是事后才知道,该由谁去维护预防
- 审计信息
- 用数据的人那么多,如何保障数据访问是可靠安全的
-
- 痛点:

- 智能监控能力升级
- 智能识别关键路径,合理设定报警阀值
- 任务异常产生事件,自动评估事件影响范围,通知相应人员
- 灵活报警方式配置,支持钉钉群机器人
- 运维中心:智能监控
- 痛点:
-
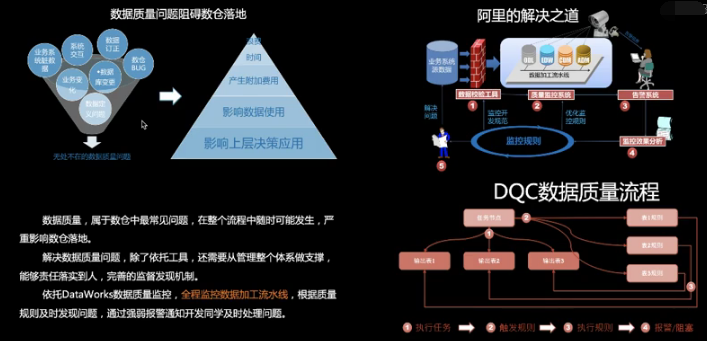
- 数据质量,属于数仓中最常见问题,在整个流程中随时可能发生,严重影响数仓落地。
- 解决数据质量问题,除了依托工具,还需要从管理整个体系做支撑,能够责任落实到人,完善监督发现机制。
- 依托DataWorks数据质量监控,全程监控数据加工流水线,根据质量规则及时发现问题,通过强弱报警通知开发同学及时处理问题。
-
-
- DataWorks数据云上托管服务中心-数据服务:支持弹性伸缩的,高稳定QPS的,多数据源多协议的,Serverless服务编排的,云上数据托管API服务平台,包括:可视化生成API,自定义SQL生成API,函数计算,服务编排等,致力于数据服务化,数据共享和开放。
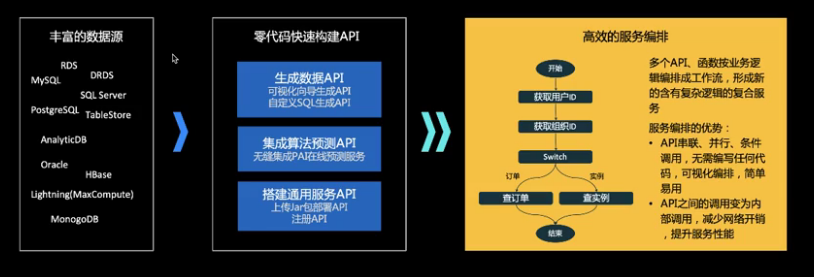
- DataWorks数据云上托管服务中心-数据服务:支持弹性伸缩的,高稳定QPS的,多数据源多协议的,Serverless服务编排的,云上数据托管API服务平台,包括:可视化生成API,自定义SQL生成API,函数计算,服务编排等,致力于数据服务化,数据共享和开放。
-
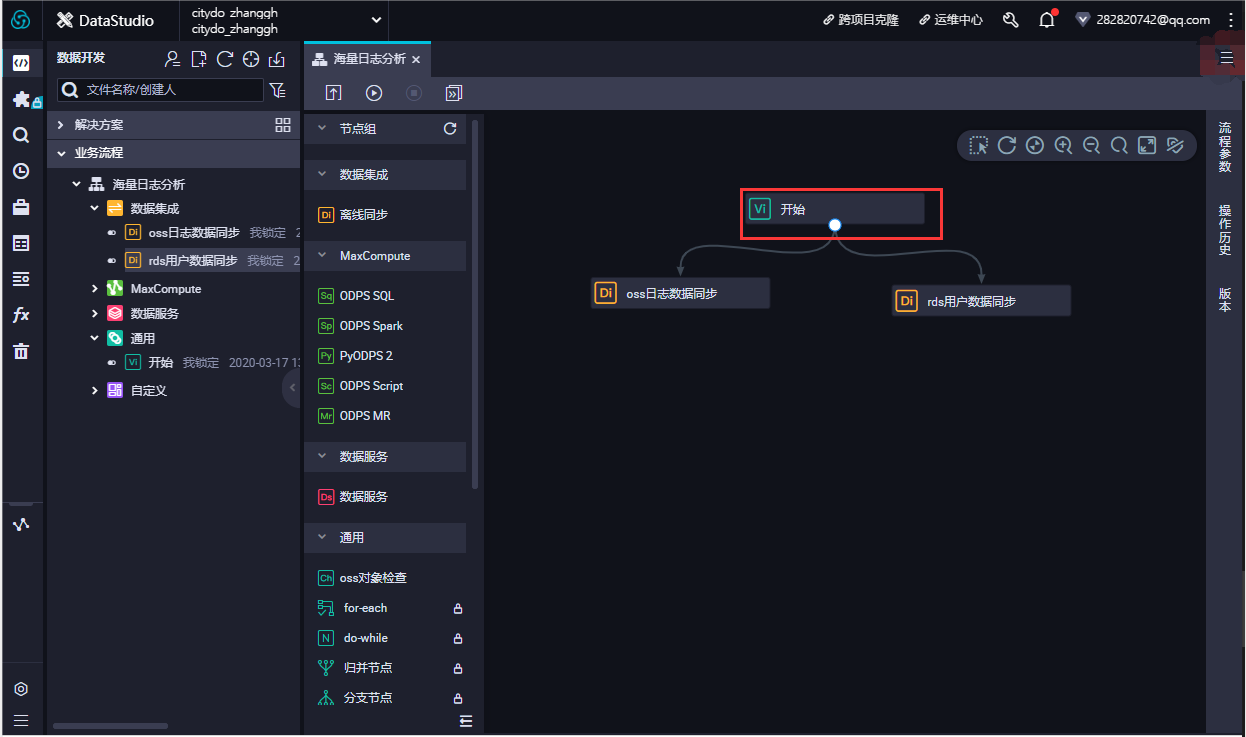
场景:海量日志分析
-
数据集成、数据开发、数据分析、运维中心、数据质量、数据服务、数据服务
-
开通地址:https://data.aliyun.com/product/ide?spm=5176.10695662.881989.1.52434695XIl4Yx
-
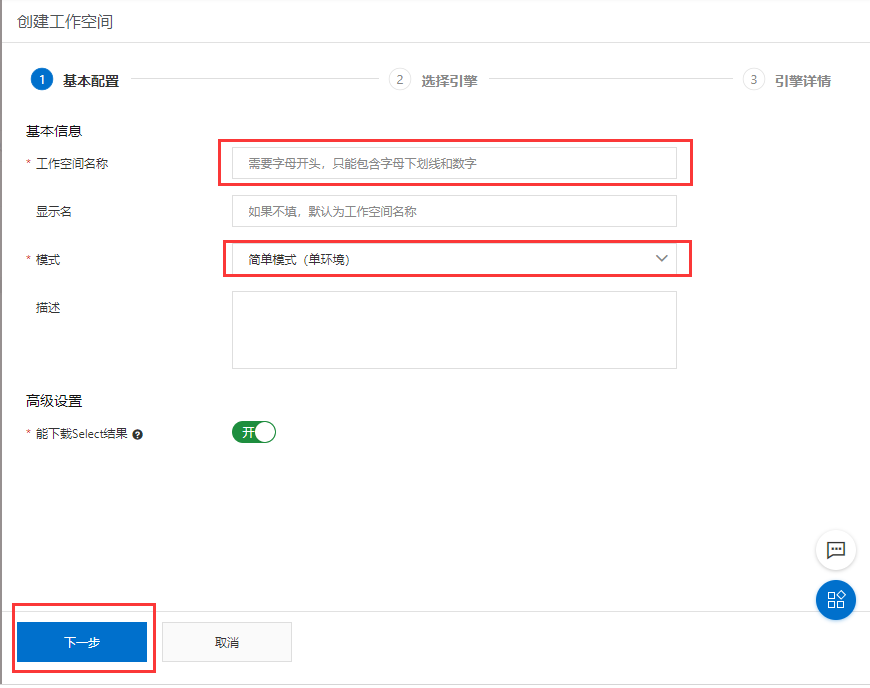
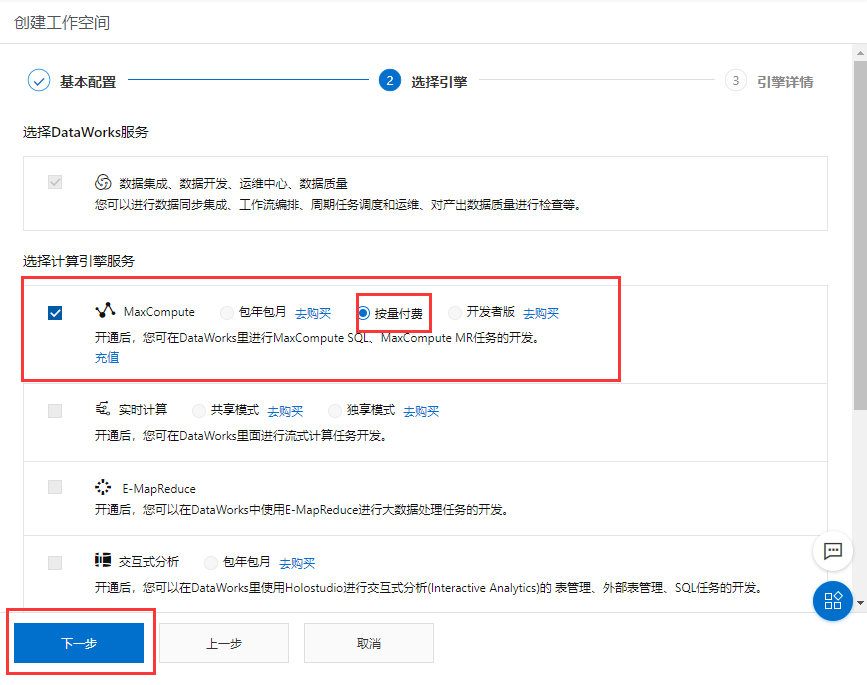
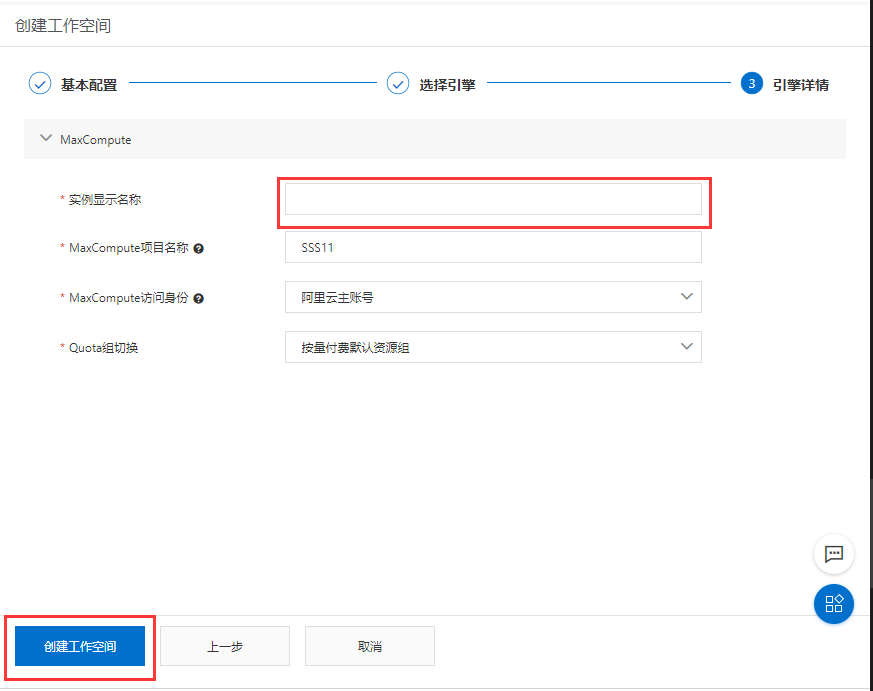
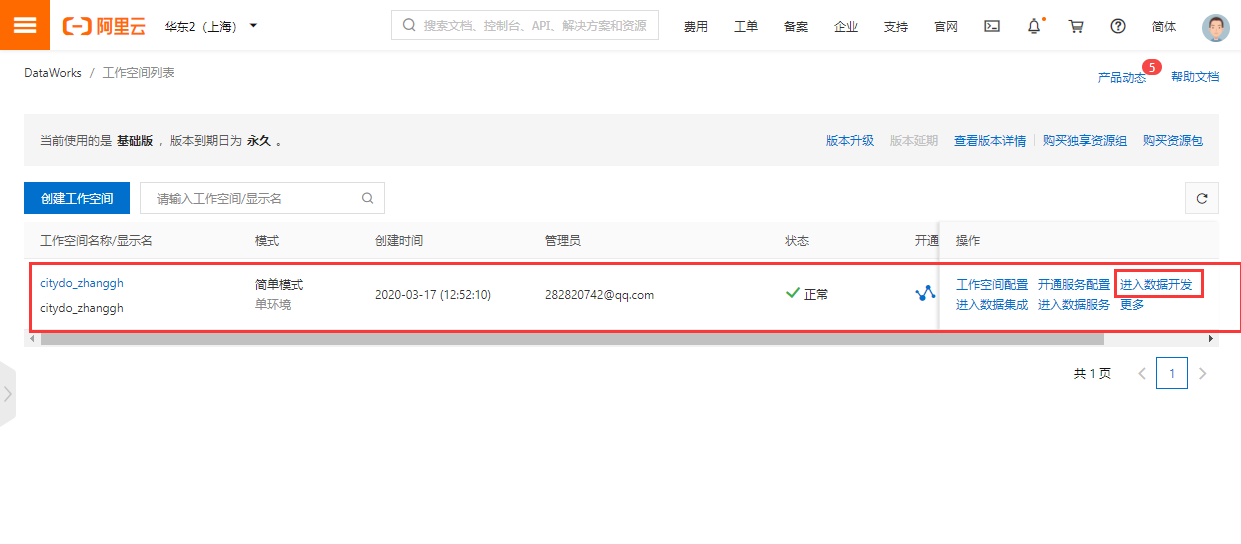
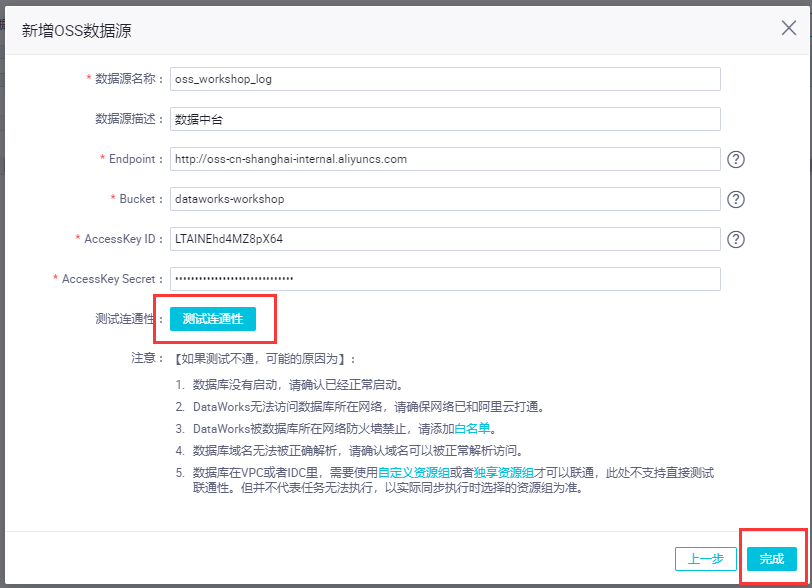
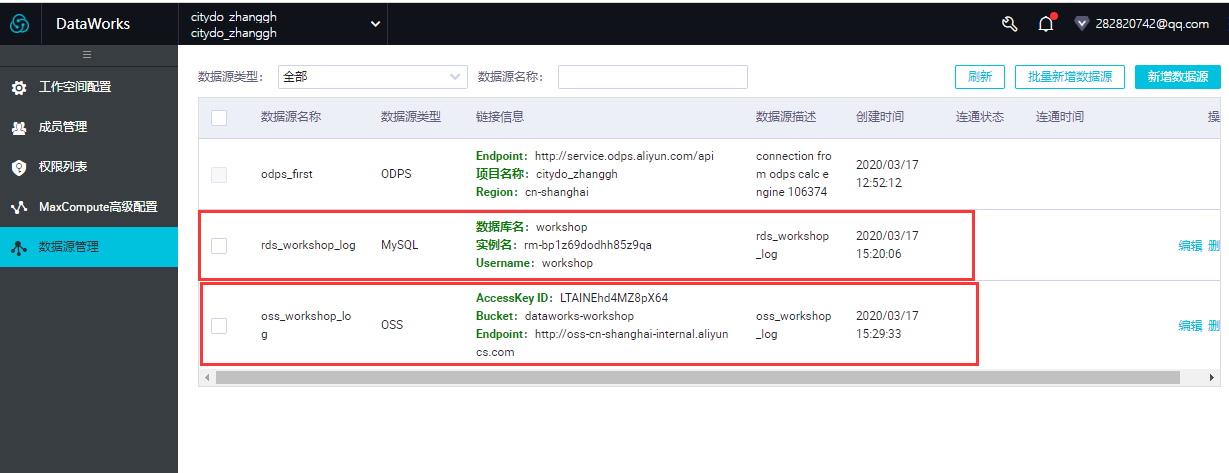
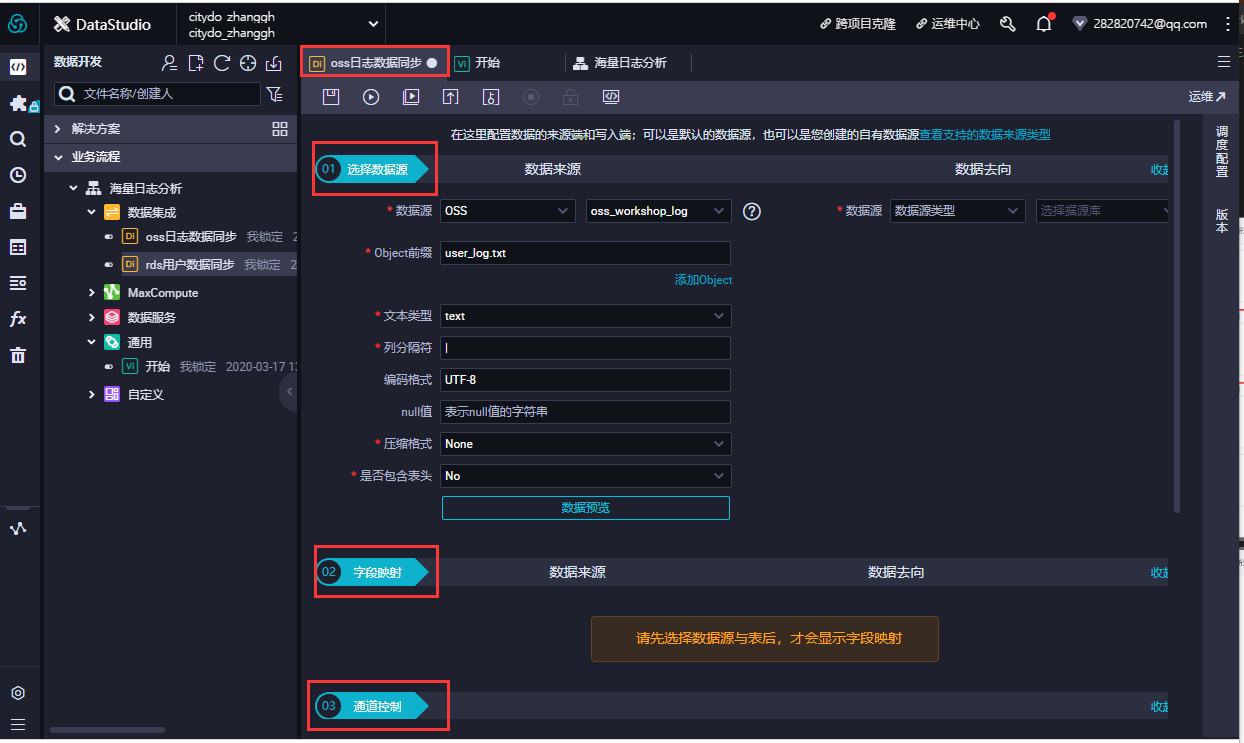
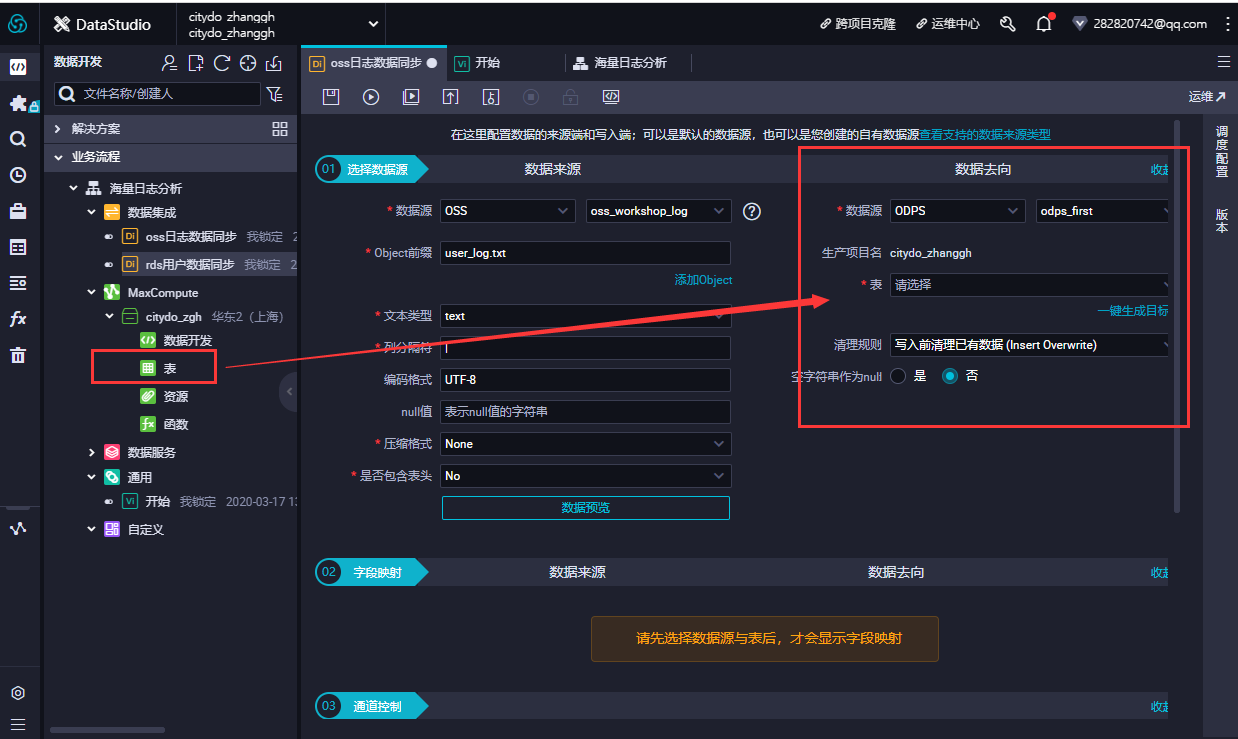
-
-
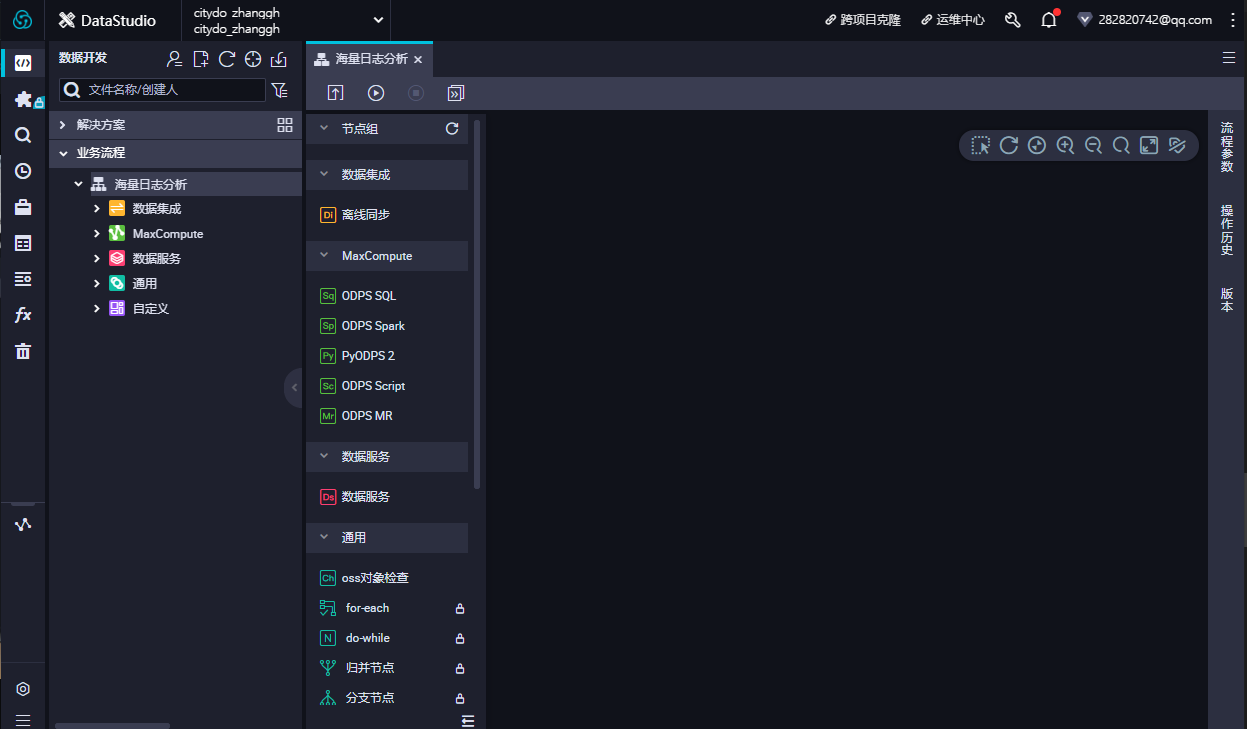
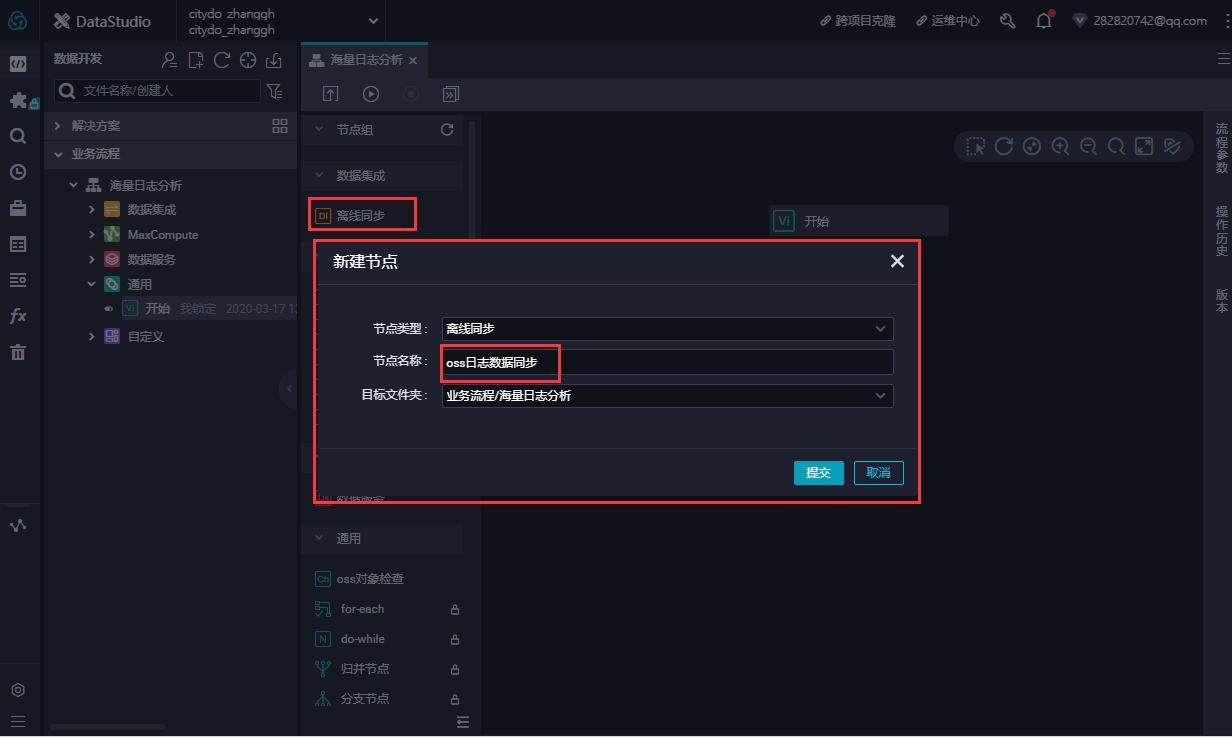
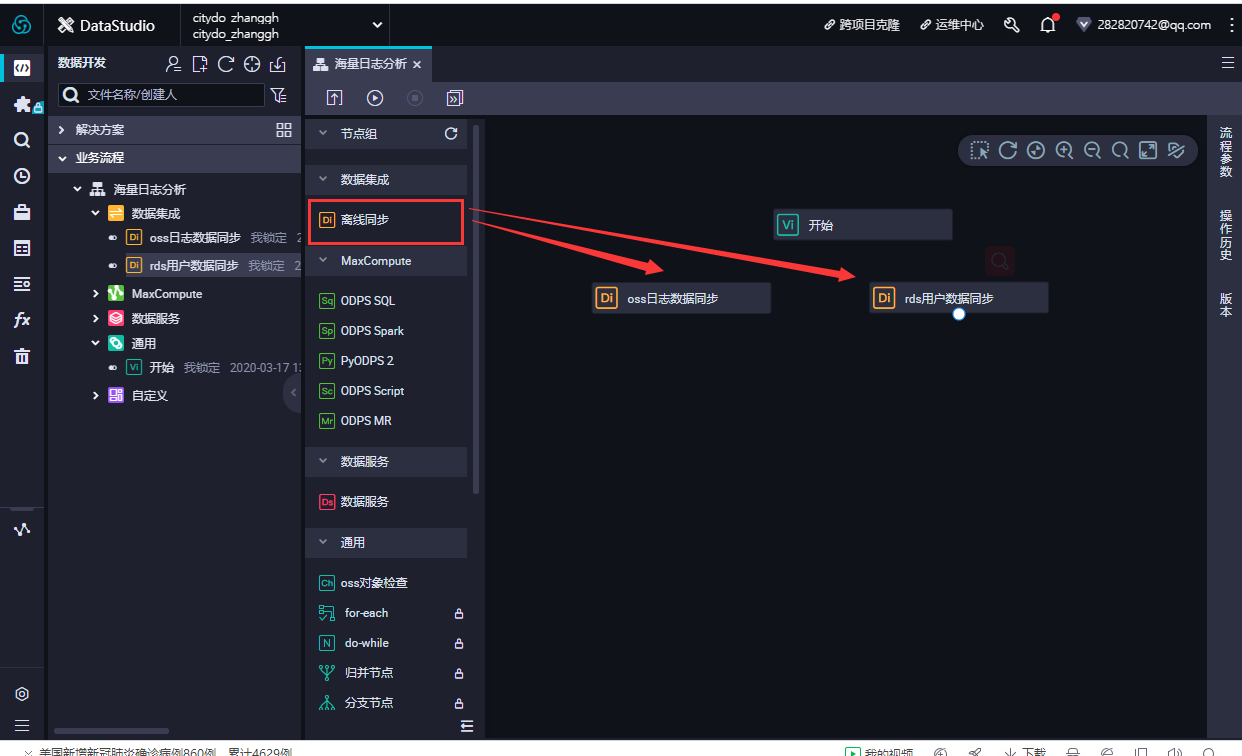
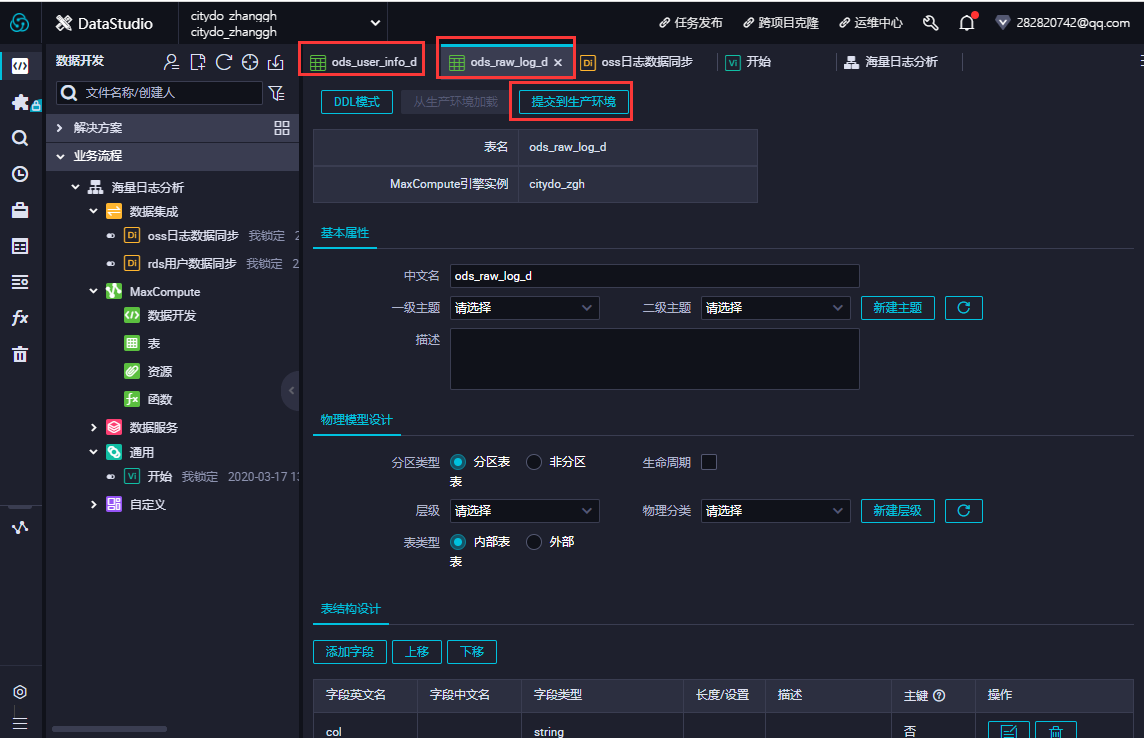
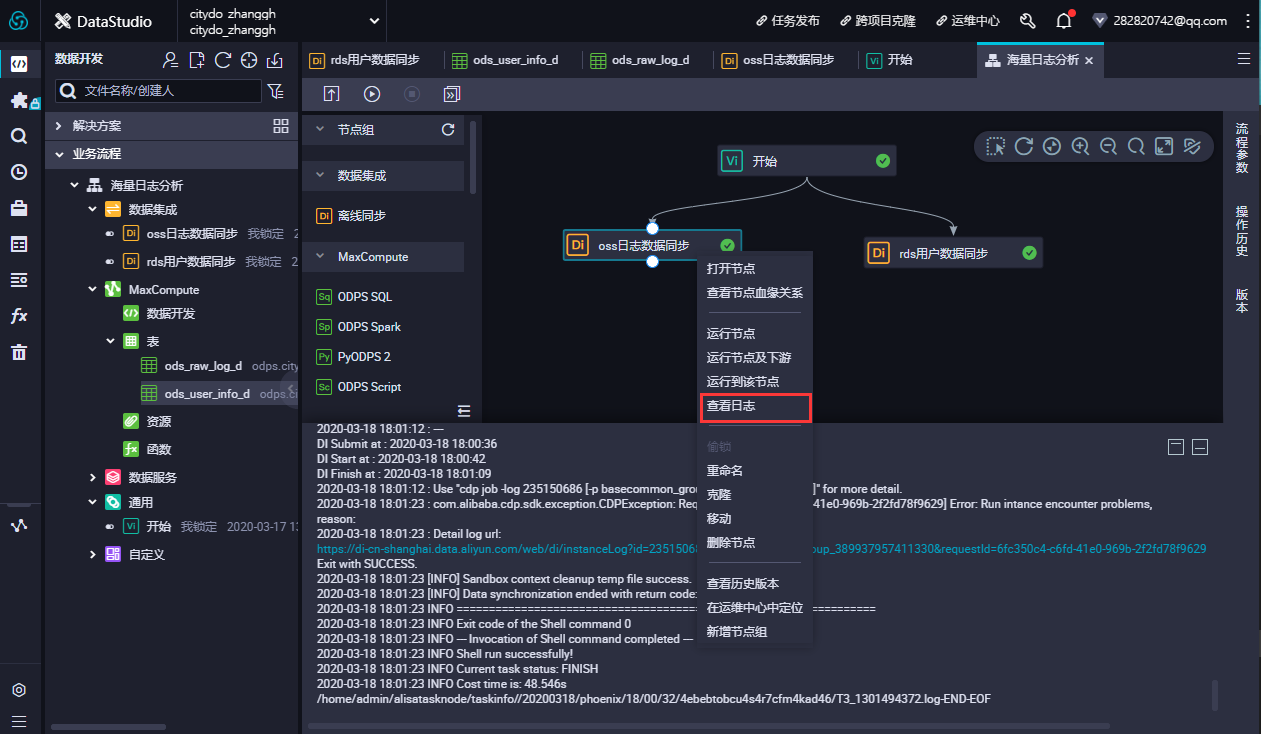
在数据开发页面打开新建的业务流程,右键单击MaxCompute,选择新建 > 表。在新建表对话框中,输入表名,单击提交。此处需要创建2张表(ods_raw_log_d和ods_user_info_d),分别存储同步过来的OSS日志数据和RDS日志数据。
-
通过DDL模式新建表。 新建ods_raw_log_d表。 双击ods_raw_log_d表,在右侧的编辑页面单击DDL模式,输入下述建表语句。
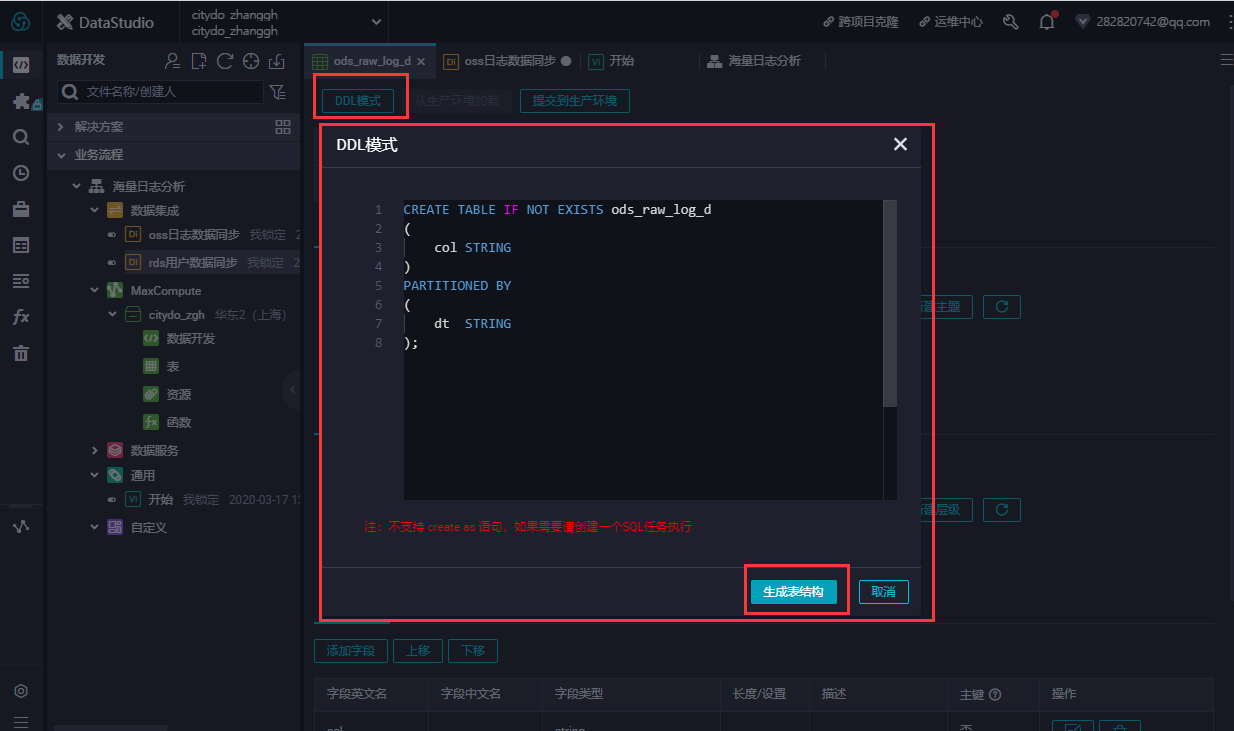
-
--创建OSS日志对应目标表 CREATE TABLE IF NOT EXISTS ods_raw_log_d ( col STRING ) PARTITIONED BY ( dt STRING );
--创建RDS对应目标表 CREATE TABLE IF NOT EXISTS ods_user_info_d ( uid STRING COMMENT '用户ID', gender STRING COMMENT '性别', age_range STRING COMMENT '年龄段', zodiac STRING COMMENT '星座' ) PARTITIONED BY ( dt STRING );
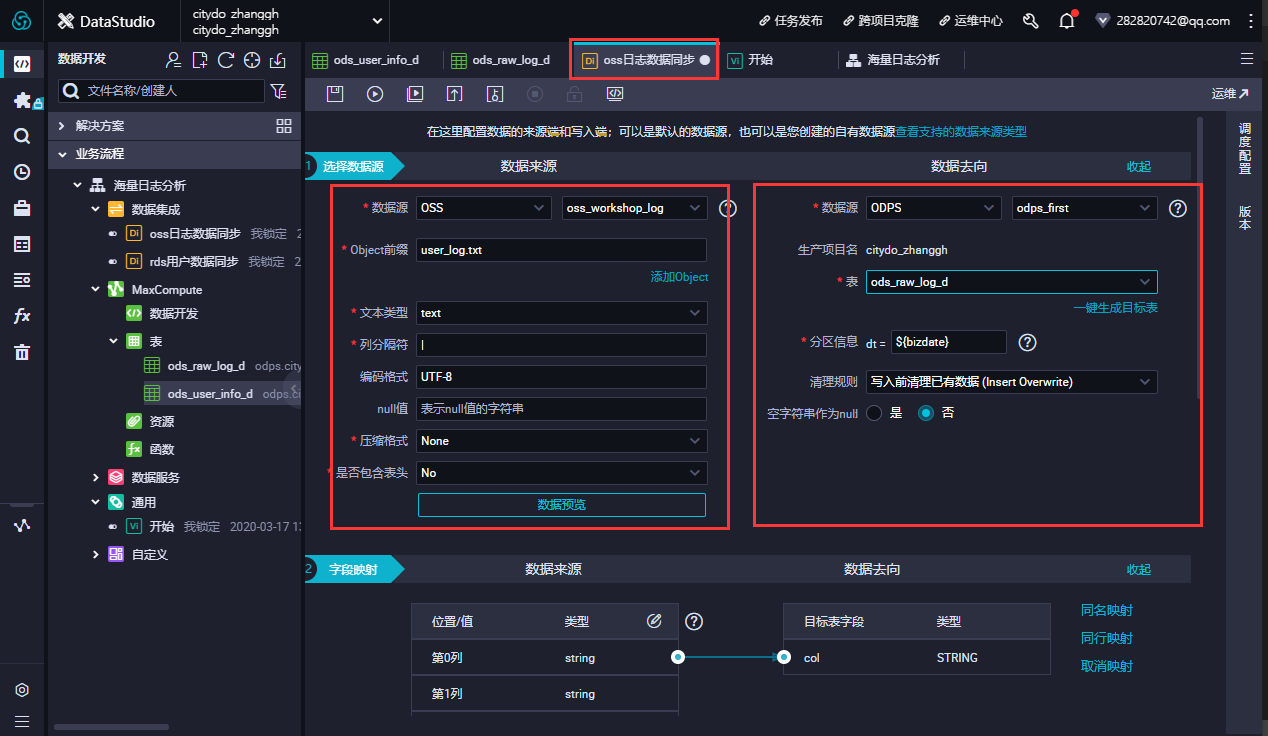
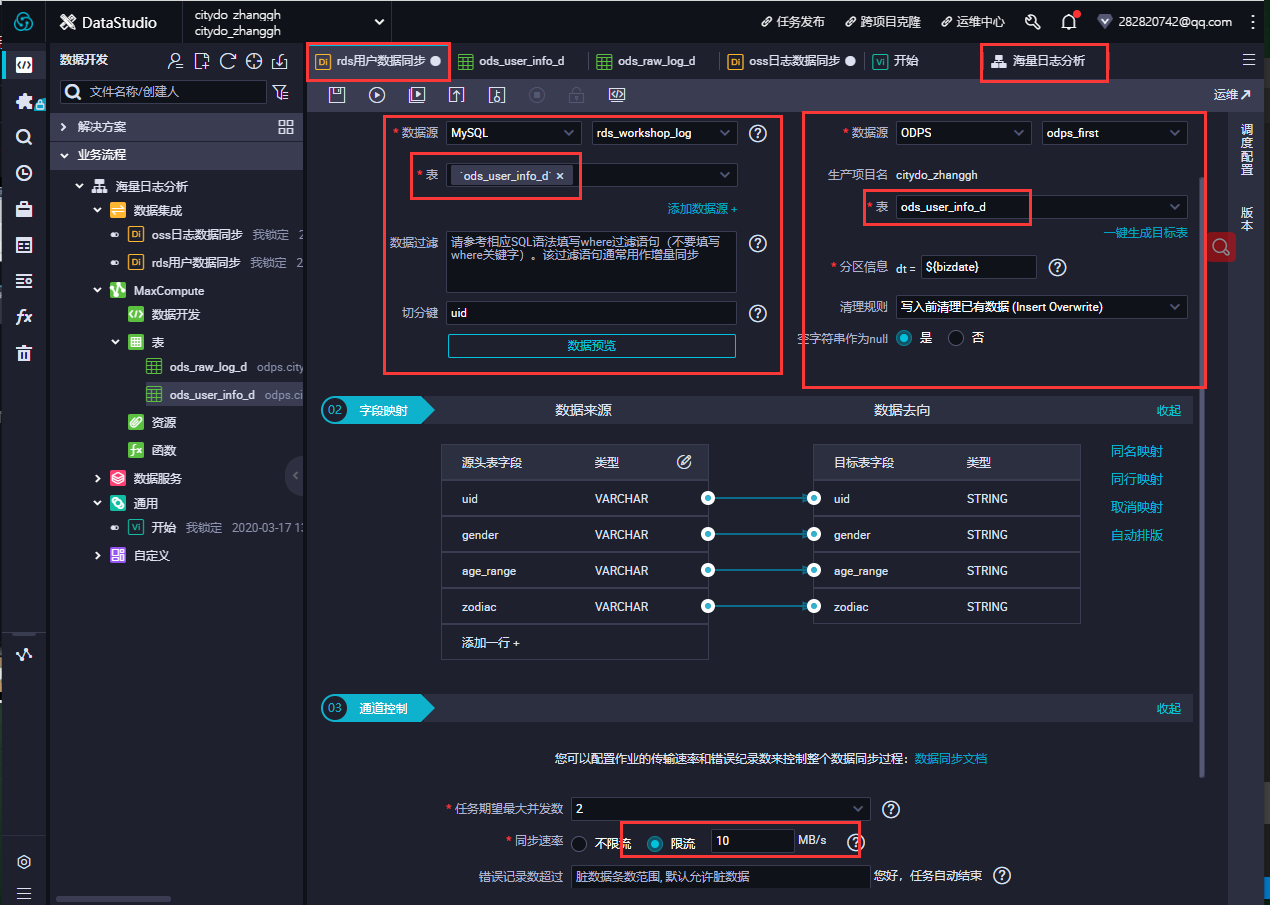
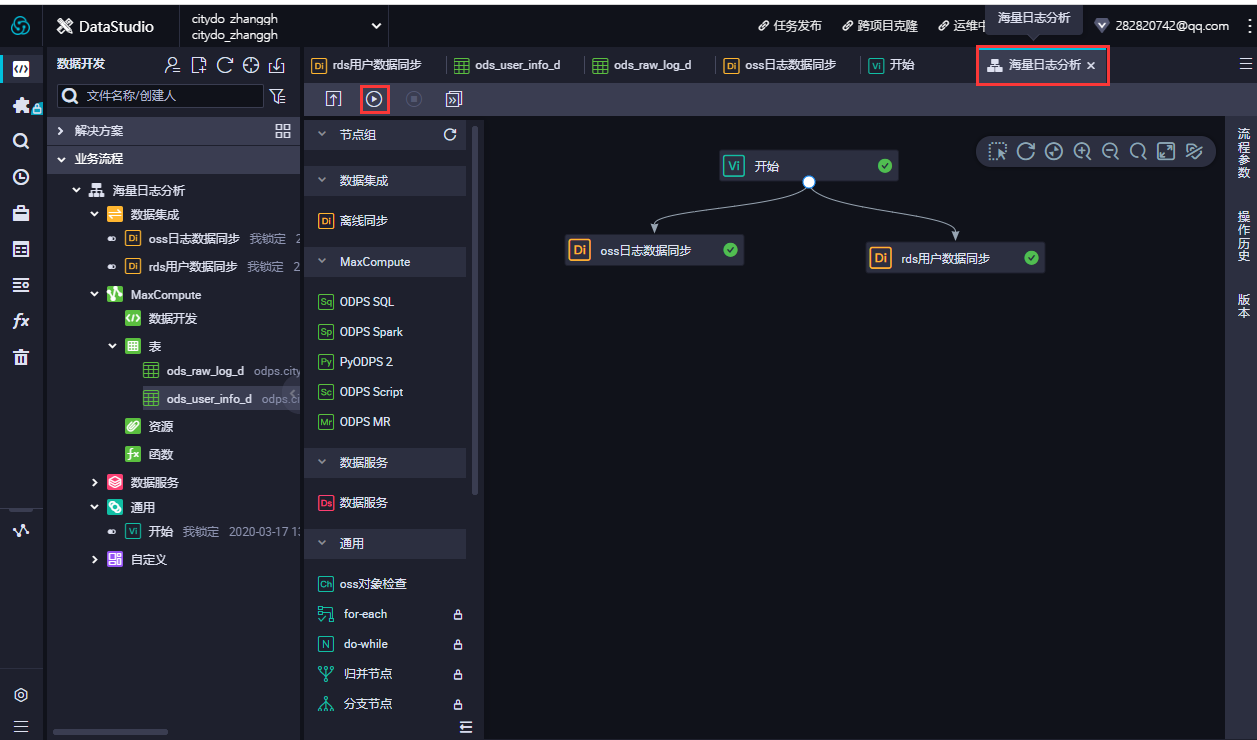
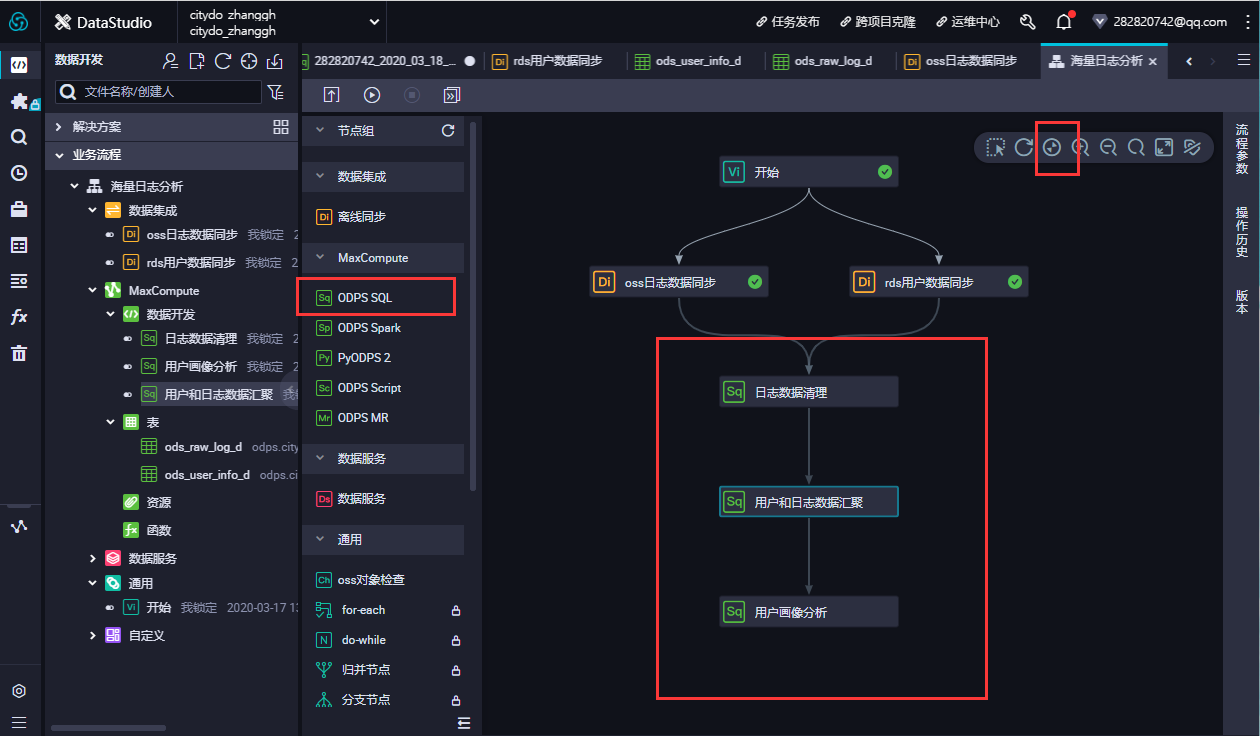
- 在数据开发面板,打开新建的业务流程,右键单击MaxCompute,选择新建 > 表。在新建表对话框中,输入表名,单击提交。此处需要创建3张表,分别为ODS层表(ods_log_info_d)、DW层表(dw_user_info_all_d)和RPT层表(rpt_user_info_d)。
- 通过DDL模式新建表。新建ods_log_info_d表。双击ods_log_info_d表,在右侧的编辑页面单击DDL模式,输入下述建表语句。
--创建ODS层表 CREATE TABLE IF NOT EXISTS ods_log_info_d ( ip STRING COMMENT 'ip地址', uid STRING COMMENT '用户ID', time STRING COMMENT '时间yyyymmddhh:mi:ss', status STRING COMMENT '服务器返回状态码', bytes STRING COMMENT '返回给客户端的字节数', region STRING COMMENT '地域,根据ip得到', method STRING COMMENT 'http请求类型', url STRING COMMENT 'url', protocol STRING COMMENT 'http协议版本号', referer STRING COMMENT '来源url', device STRING COMMENT '终端类型 ', identity STRING COMMENT '访问类型 crawler feed user unknown' ) PARTITIONED BY ( dt STRING );
- 新建dw_user_info_all_d表。双击dw_user_info_all_d表,在右侧的编辑页面单击DDL模式,输入下述建表语句。
--创建DW层表 CREATE TABLE IF NOT EXISTS dw_user_info_all_d ( uid STRING COMMENT '用户ID', gender STRING COMMENT '性别', age_range STRING COMMENT '年龄段', zodiac STRING COMMENT '星座', region STRING COMMENT '地域,根据ip得到', device STRING COMMENT '终端类型 ', identity STRING COMMENT '访问类型 crawler feed user unknown', method STRING COMMENT 'http请求类型', url STRING COMMENT 'url', referer STRING COMMENT '来源url', time STRING COMMENT '时间yyyymmddhh:mi:ss' ) PARTITIONED BY ( dt STRING );
- 新建rpt_user_info_d表。双击rpt_user_info_d表,在右侧的编辑页面单击DDL模式,输入下述建表语句。
--创建RPT层表 CREATE TABLE IF NOT EXISTS rpt_user_info_d ( uid STRING COMMENT '用户ID', region STRING COMMENT '地域,根据ip得到', device STRING COMMENT '终端类型 ', pv BIGINT COMMENT 'pv', gender STRING COMMENT '性别', age_range STRING COMMENT '年龄段', zodiac STRING COMMENT '星座' ) PARTITIONED BY ( dt STRING );
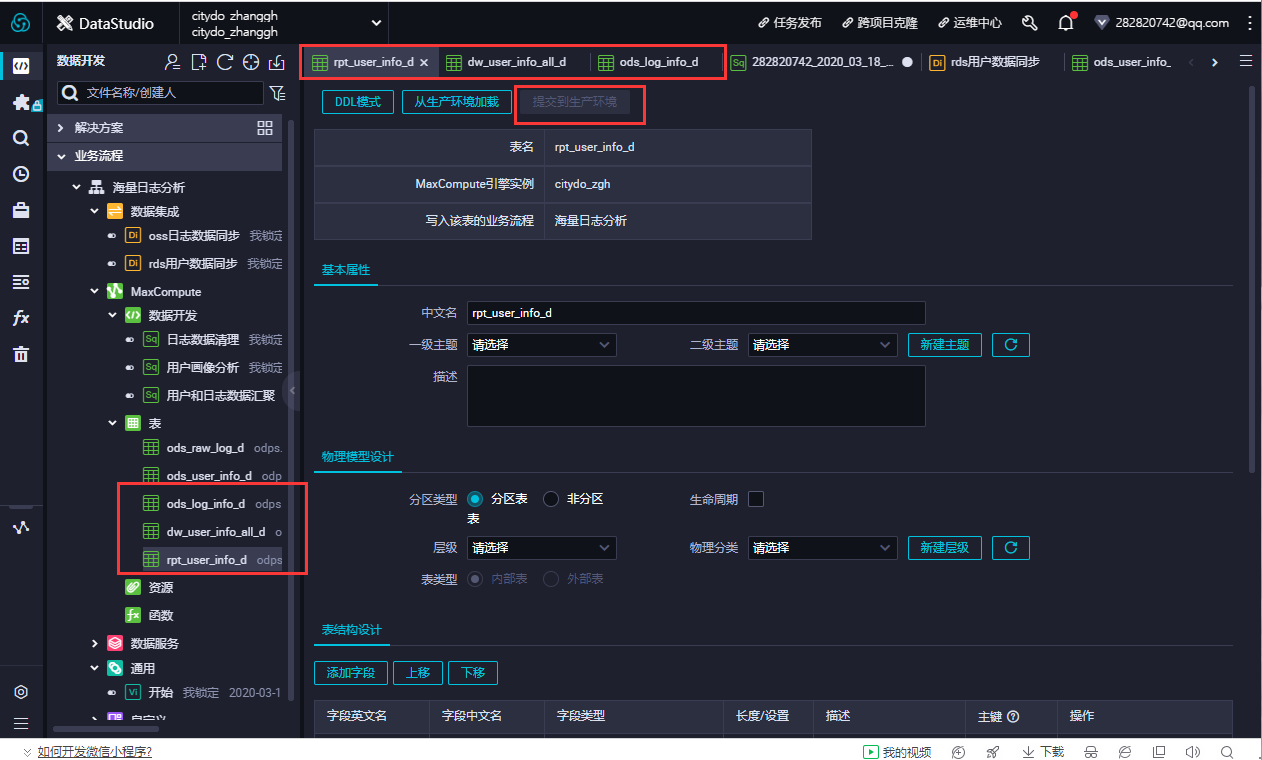
- 建表语句输入完成后,单击生成表结构并确认覆盖当前操作。返回建表页面后,在基本属性中输入表的中文名。完成设置后,分别单击提交到开发环境和提交到生产环境。
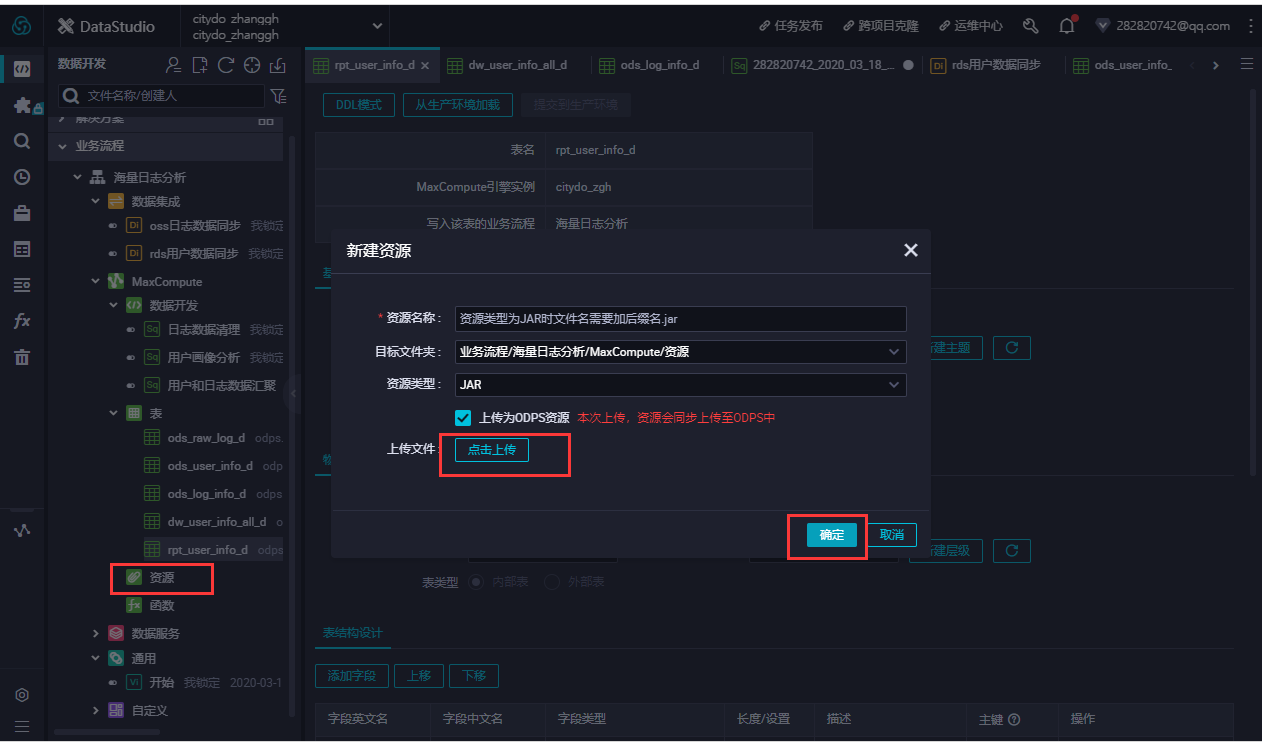
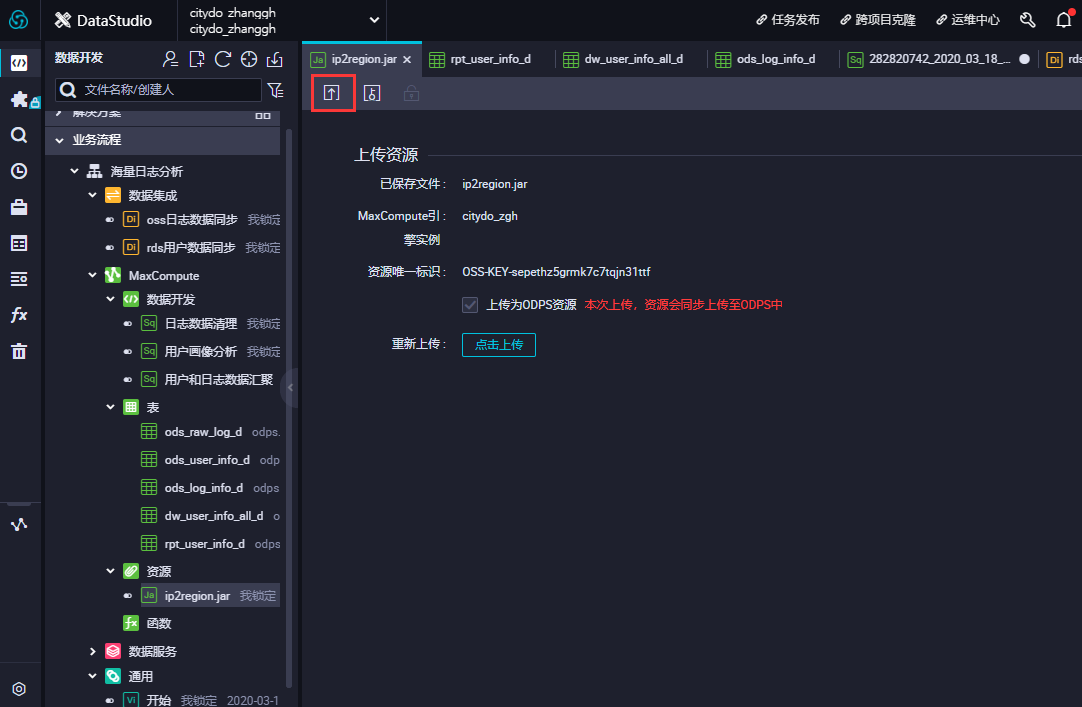
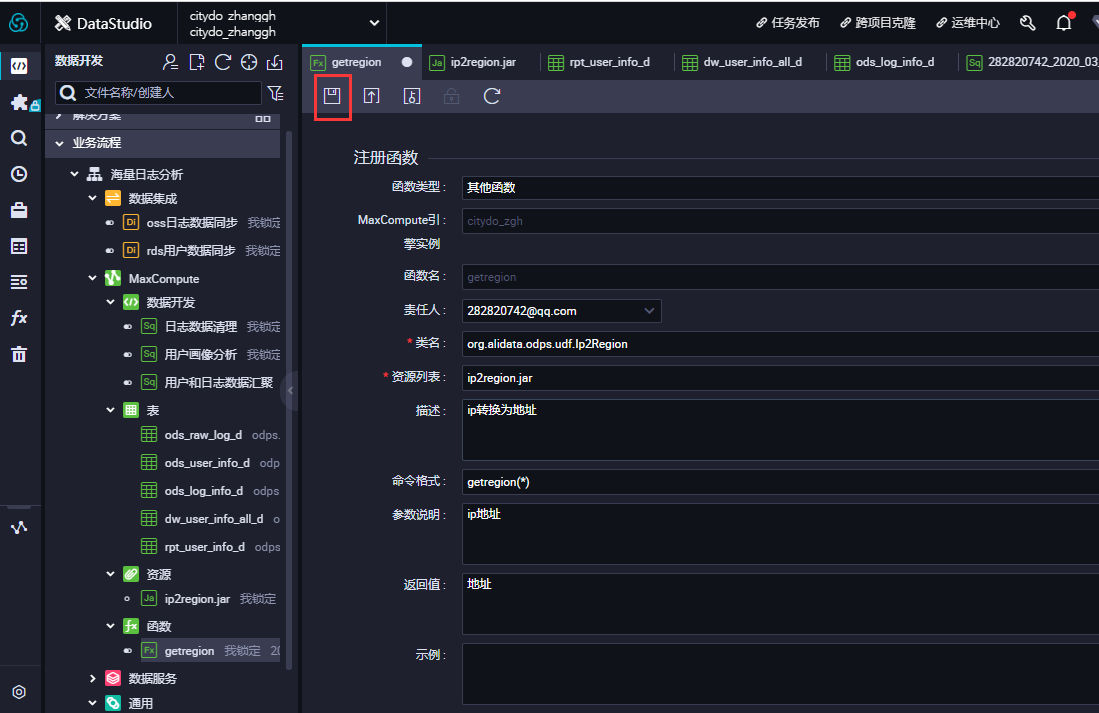
-
- 配置ods_log_info_d节点。双击ods_log_info_d节点,进入节点配置页面。在节点编辑页面,编写如下SQL语句。
INSERT OVERWRITE TABLE ods_log_info_d PARTITION (dt=${bdp.system.bizdate}) SELECT ip , uid , time , status , bytes , getregion(ip) AS region --使用自定义UDF通过IP得到地域。 , regexp_substr(request, '(^[^ ]+ )') AS method --通过正则把request差分为3个字段。 , regexp_extract(request, '^[^ ]+ (.*) [^ ]+$') AS url , regexp_substr(request, '([^ ]+$)') AS protocol , regexp_extract(referer, '^[^/]+://([^/]+){1}') AS referer --通过正则清晰refer,得到更精准的URL。 , CASE WHEN TOLOWER(agent) RLIKE 'android' THEN 'android' --通过agent得到终端信息和访问形式。 WHEN TOLOWER(agent) RLIKE 'iphone' THEN 'iphone' WHEN TOLOWER(agent) RLIKE 'ipad' THEN 'ipad' WHEN TOLOWER(agent) RLIKE 'macintosh' THEN 'macintosh' WHEN TOLOWER(agent) RLIKE 'windows phone' THEN 'windows_phone' WHEN TOLOWER(agent) RLIKE 'windows' THEN 'windows_pc' ELSE 'unknown' END AS device , CASE WHEN TOLOWER(agent) RLIKE '(bot|spider|crawler|slurp)' THEN 'crawler' WHEN TOLOWER(agent) RLIKE 'feed' OR regexp_extract(request, '^[^ ]+ (.*) [^ ]+$') RLIKE 'feed' THEN 'feed' WHEN TOLOWER(agent) NOT RLIKE '(bot|spider|crawler|feed|slurp)' AND agent RLIKE '^[Mozilla|Opera]' AND regexp_extract(request, '^[^ ]+ (.*) [^ ]+$') NOT RLIKE 'feed' THEN 'user' ELSE 'unknown' END AS identity FROM ( SELECT SPLIT(col, '##@@')[0] AS ip , SPLIT(col, '##@@')[1] AS uid , SPLIT(col, '##@@')[2] AS time , SPLIT(col, '##@@')[3] AS request , SPLIT(col, '##@@')[4] AS status , SPLIT(col, '##@@')[5] AS bytes , SPLIT(col, '##@@')[6] AS referer , SPLIT(col, '##@@')[7] AS agent FROM ods_raw_log_d WHERE dt = ${bdp.system.bizdate} ) a;
- 单击左上角的保存图标。
- 配置dw_user_info_all_d节点。
- 双击dw_user_info_all_d节点,进入节点配置页面。在节点编辑页面,编写如下SQL语句。
INSERT OVERWRITE TABLE dw_user_info_all_d PARTITION (dt='${bdp.system.bizdate}') SELECT COALESCE(a.uid, b.uid) AS uid , b.gender , b.age_range , b.zodiac , a.region , a.device , a.identity , a.method , a.url , a.referer , a.time FROM ( SELECT * FROM ods_log_info_d WHERE dt = ${bdp.system.bizdate} ) a LEFT OUTER JOIN ( SELECT * FROM ods_user_info_d WHERE dt = ${bdp.system.bizdate} ) b ON a.uid = b.uid;
- 单击左上角的保存图标。
- 配置rpt_user_info_d节点。
- 双击rpt_user_info_d节点,进入节点配置页面。在节点编辑页面,编写如下SQL语句。
INSERT OVERWRITE TABLE rpt_user_info_d PARTITION (dt='${bdp.system.bizdate}') SELECT uid , MAX(region) , MAX(device) , COUNT(0) AS pv , MAX(gender) , MAX(age_range) , MAX(zodiac) FROM dw_user_info_all_d WHERE dt = ${bdp.system.bizdate} GROUP BY uid;
- 单击左上角的保存图标。
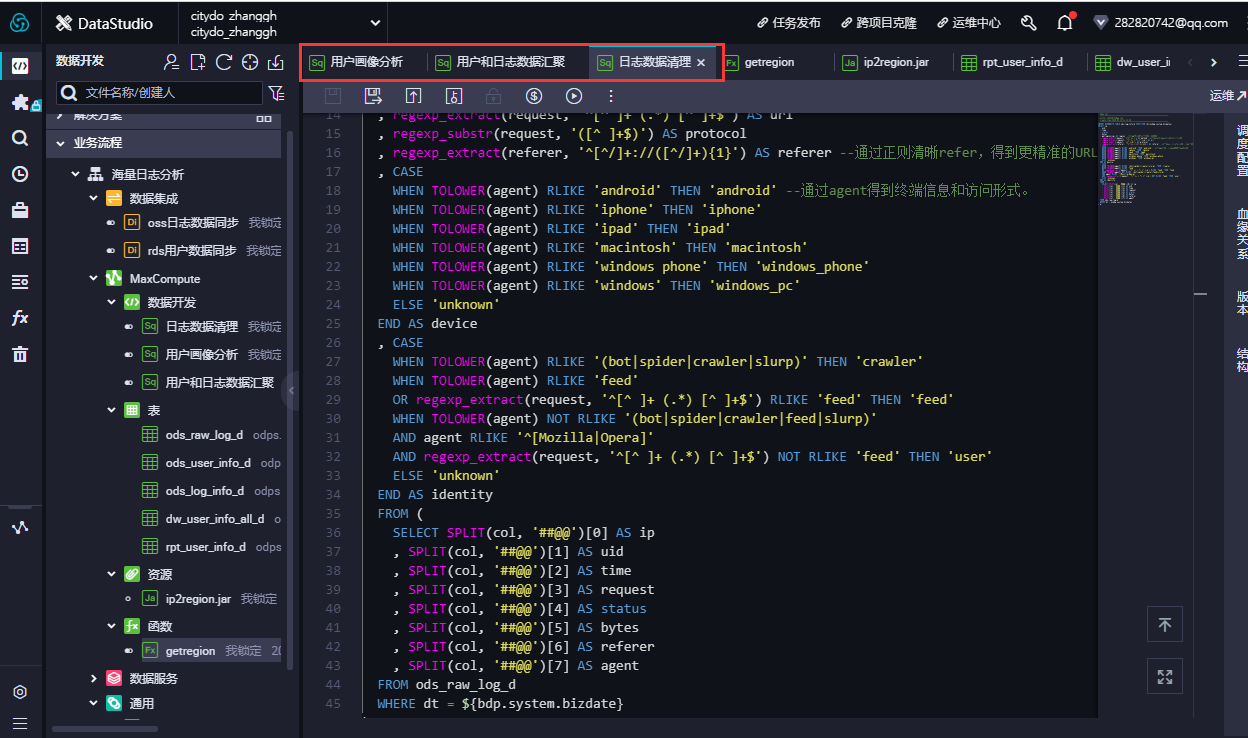
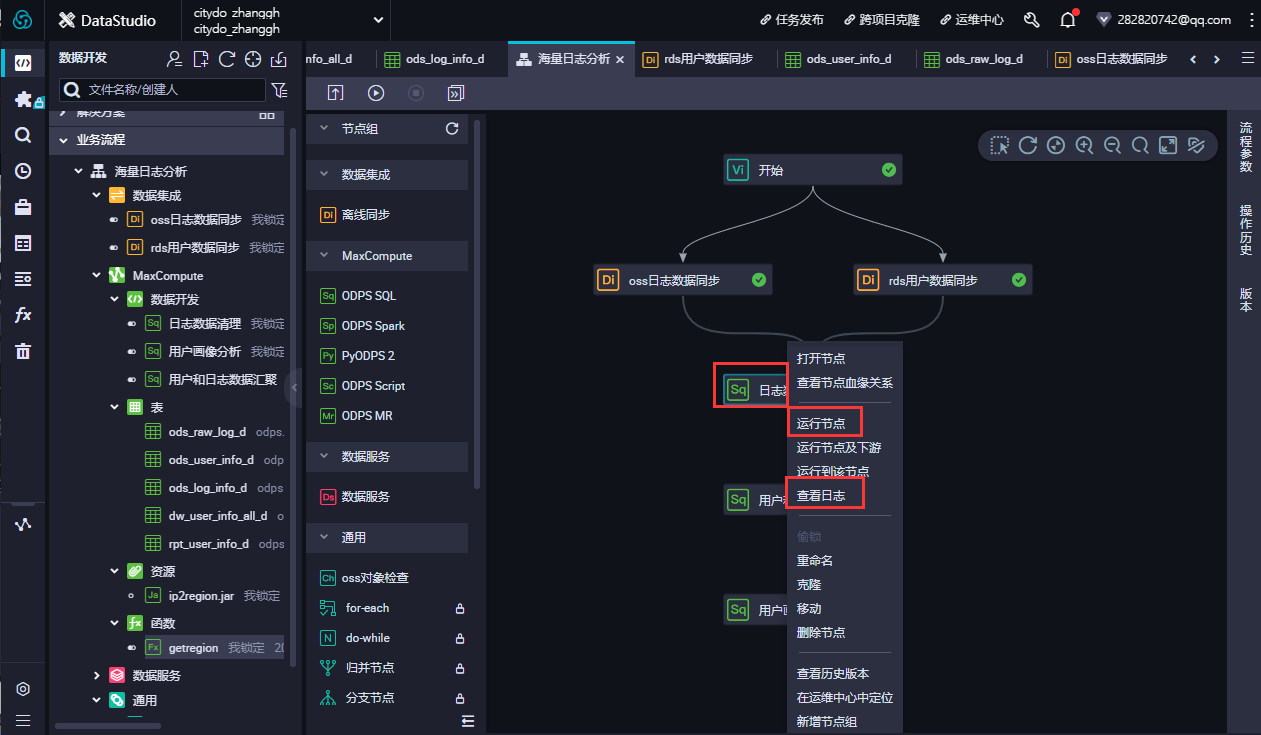
-
-
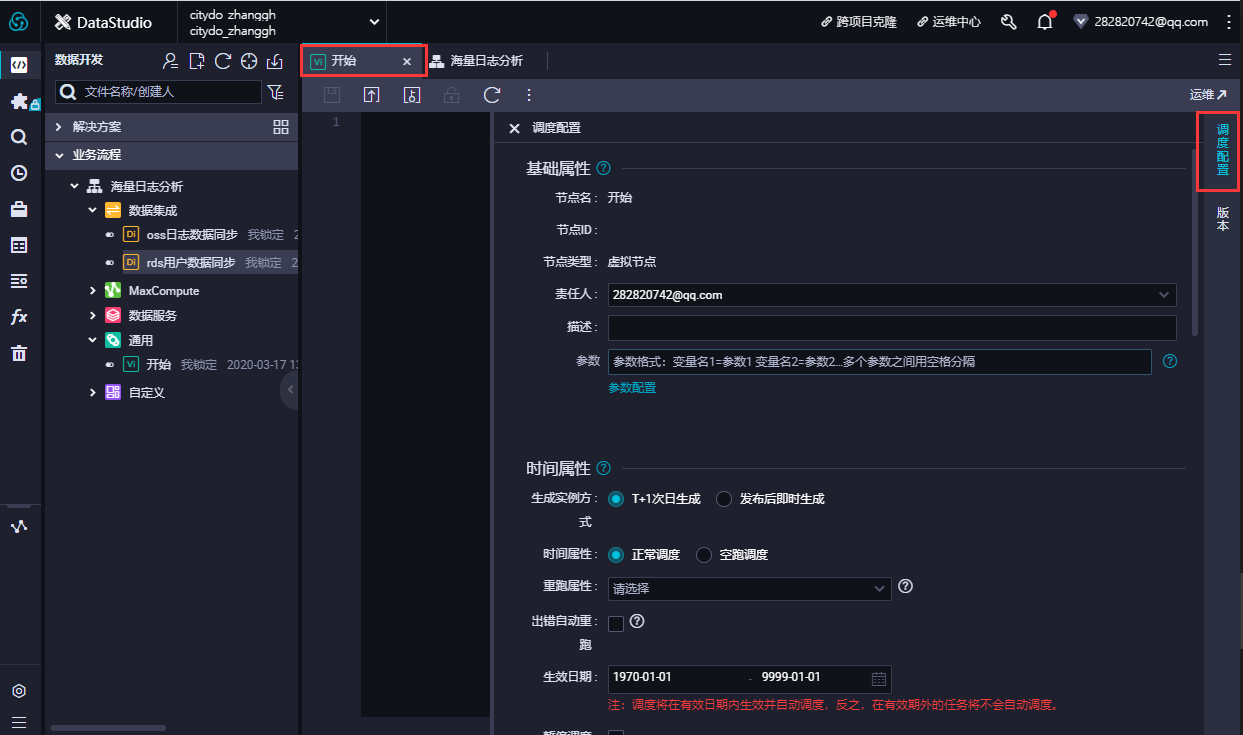
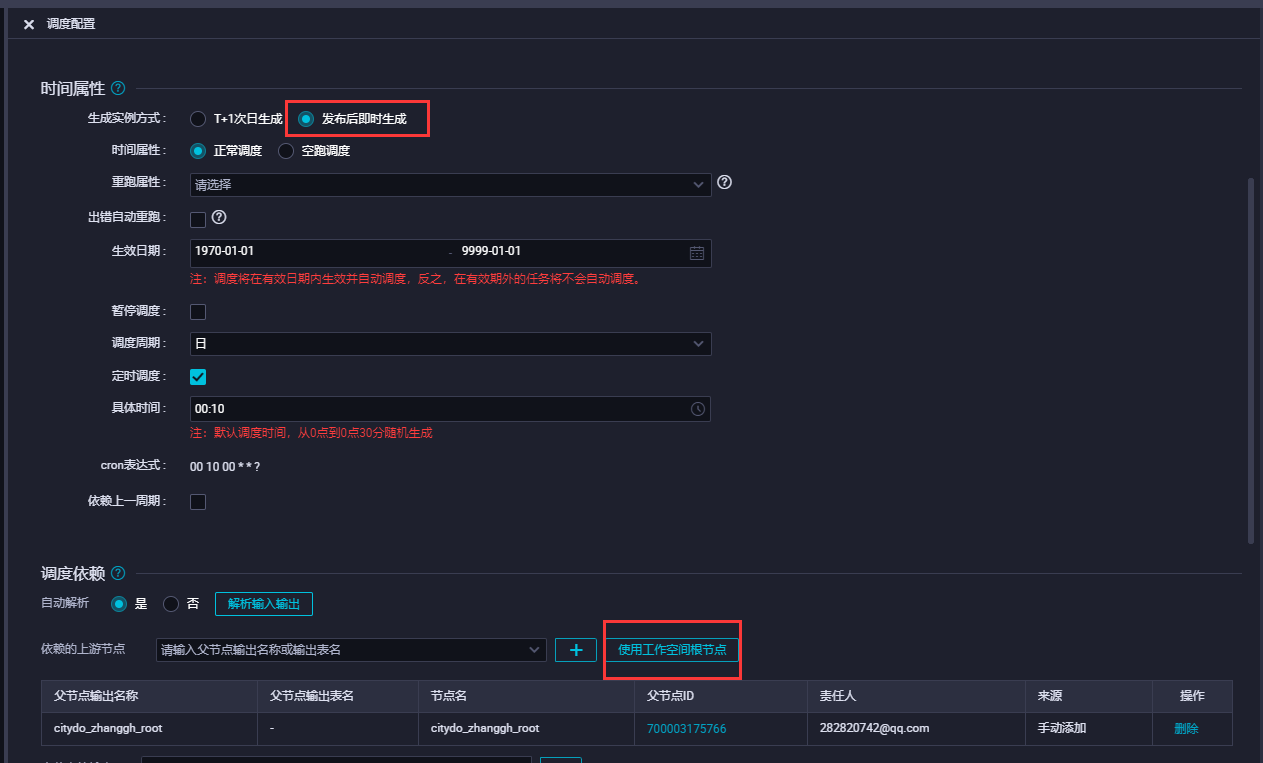
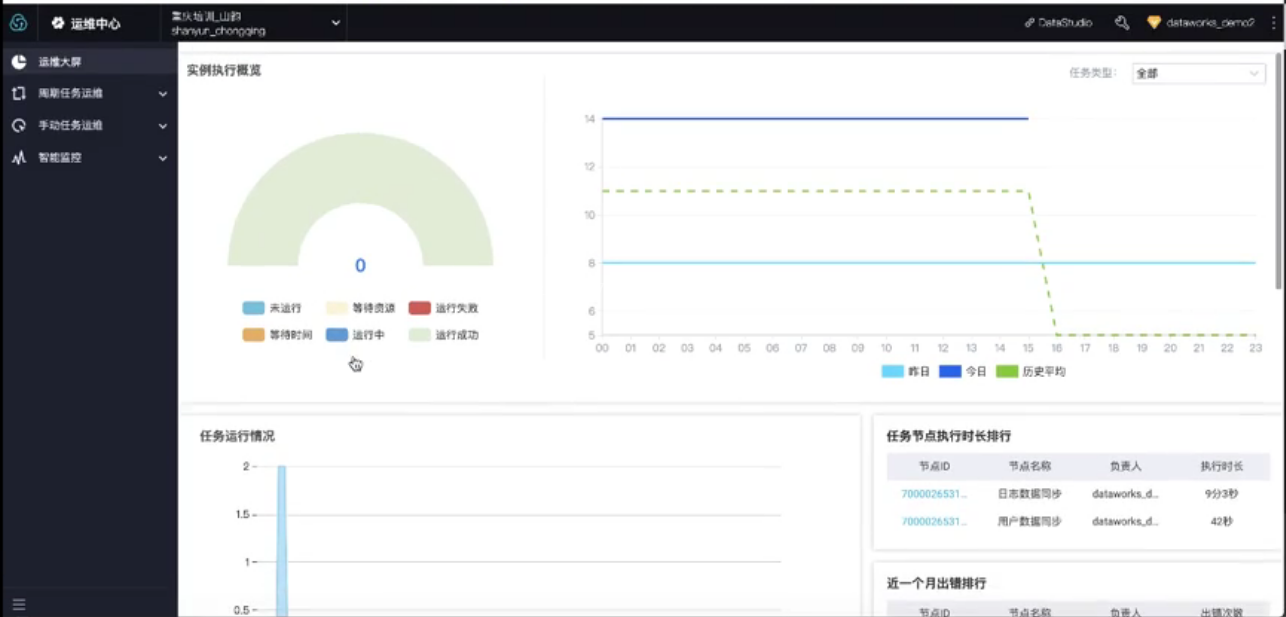
- 通过主界面右上角进入运维中心,可查看当前dataworks中运行的实例
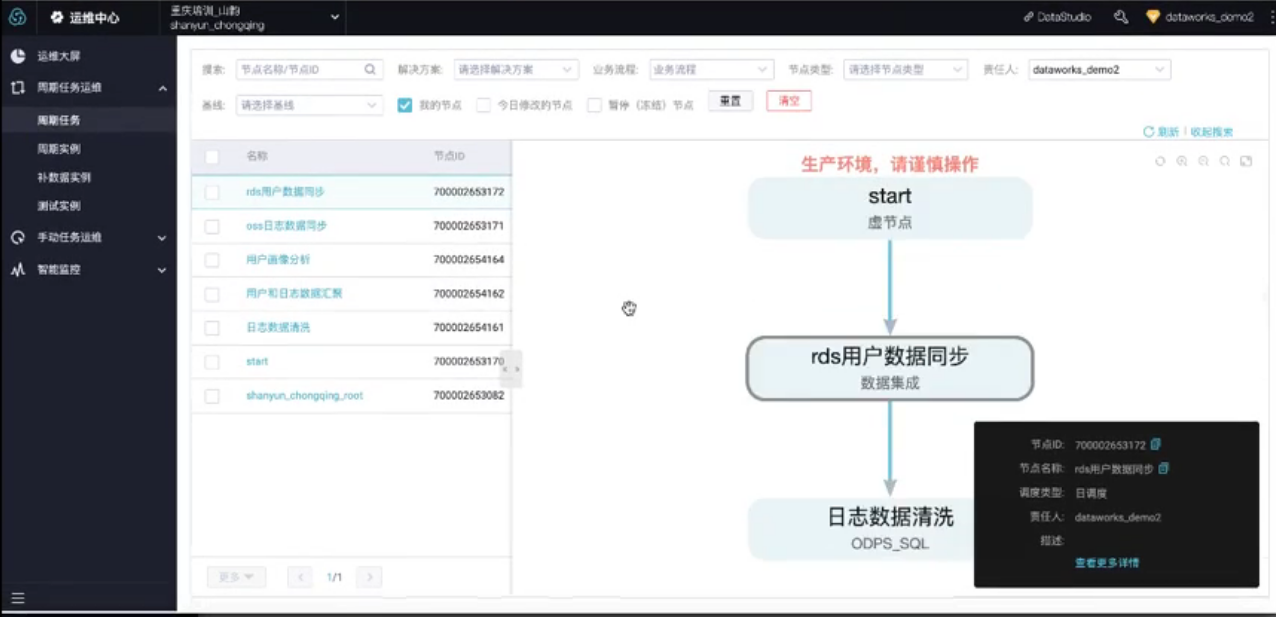
- 进入周期任务运维栏,可以查看当前周期任务预览运行情况
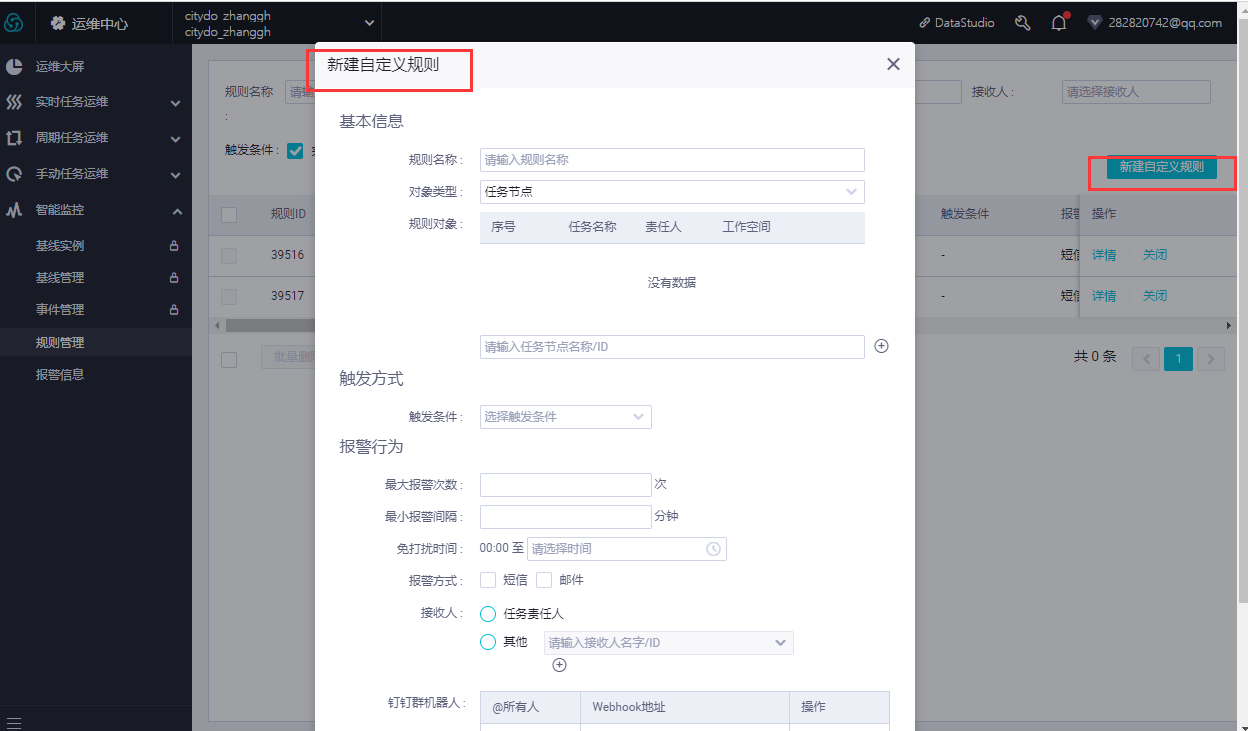
- 进入智能监控规则配置栏,新增规则配置,规则可自行设定
- 通过主界面右上角进入运维中心,可查看当前dataworks中运行的实例
-
- 主界面进入数据地图,可以看到当前的数据总览、全部数据、我的数据、配置管理、数据发现
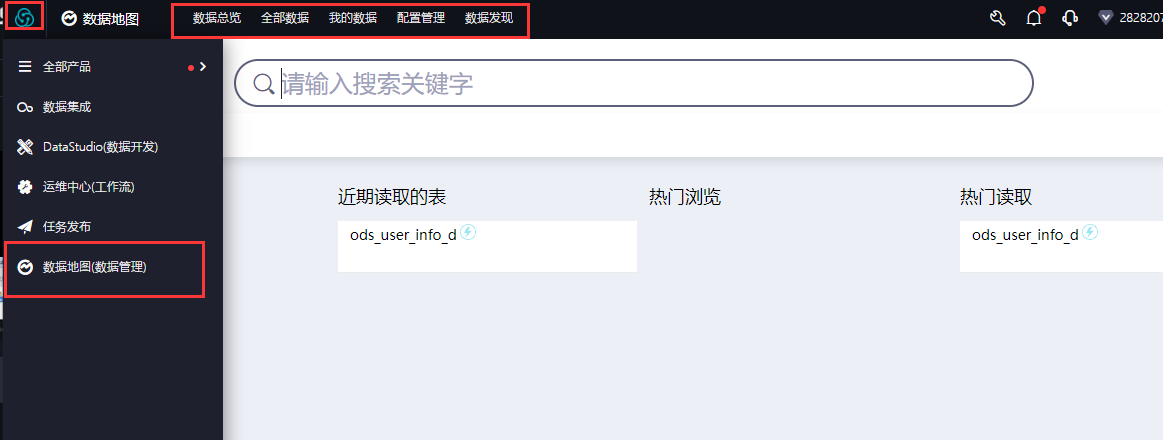
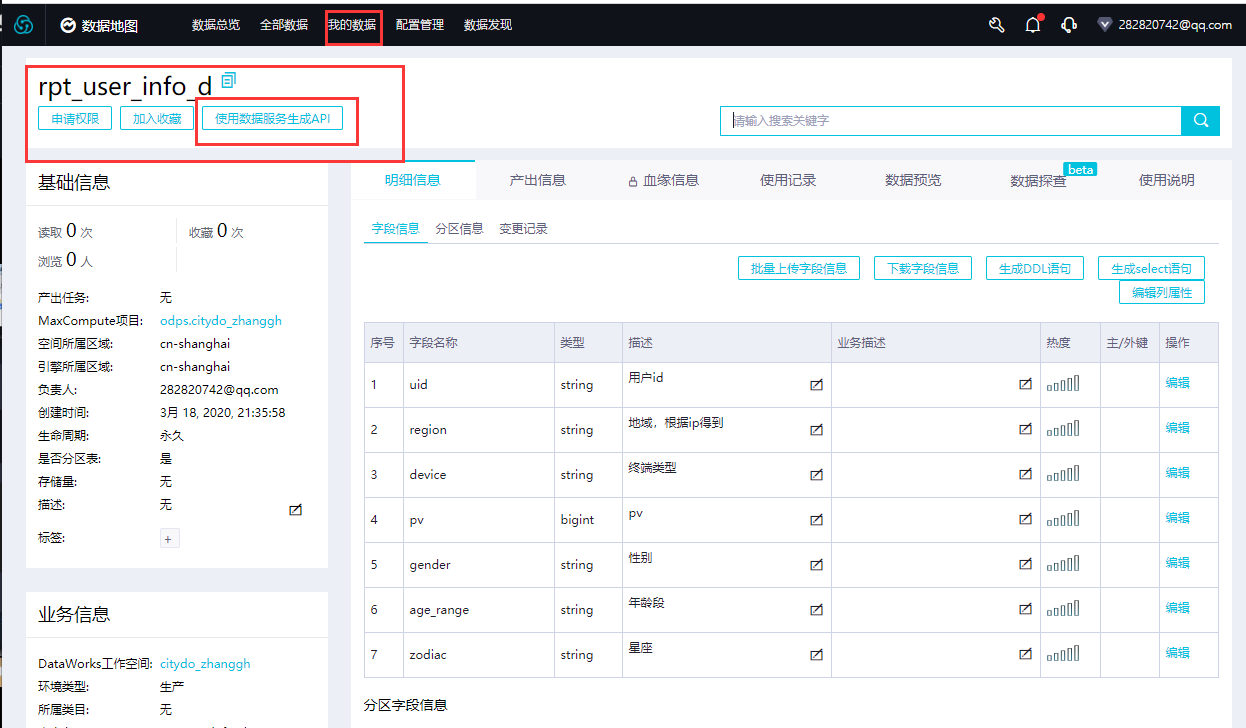
- 点击我的数据单张表,可进入该表生成对应请求API调用
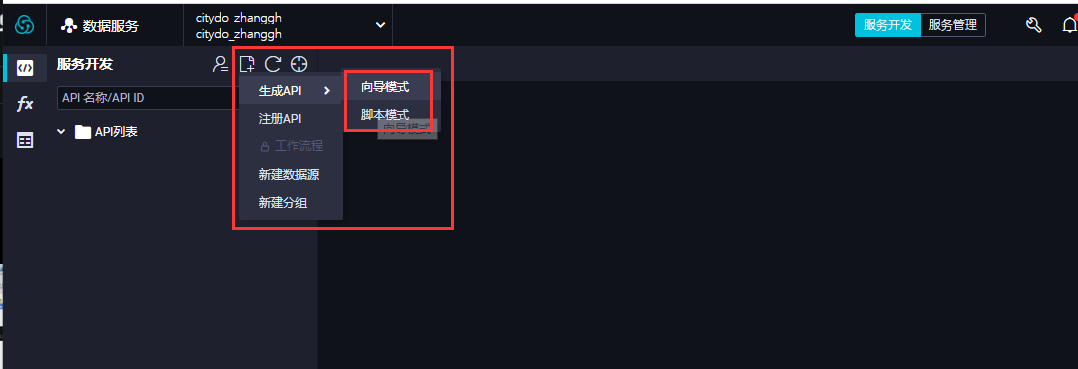
- 在设置API过程中, 需要新建API分组,通过新增按钮可以看到两种模式:向导模式、脚本模式,本次使用向导模式
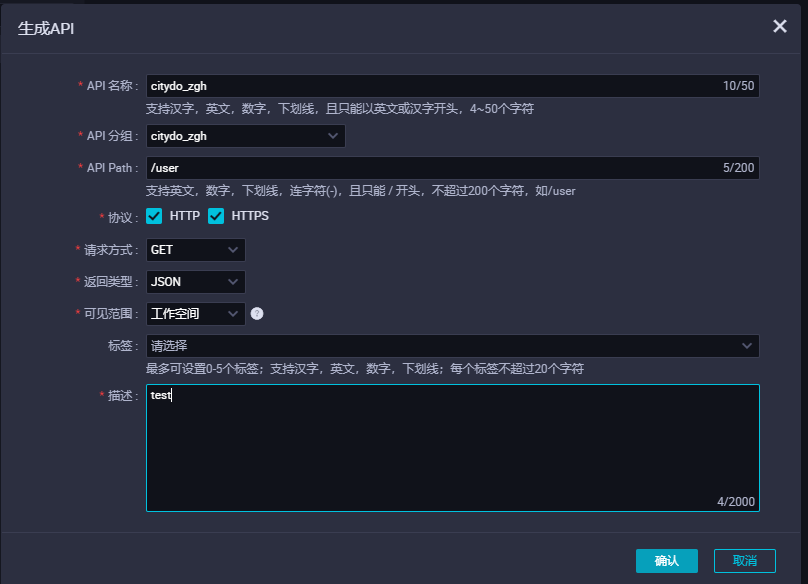
- 完成新增生成API后,可以勾选对应字段,可以看到,勾选请求参数为uid,返回参数为性别gender,即发送UID,返回对应uidd 性别
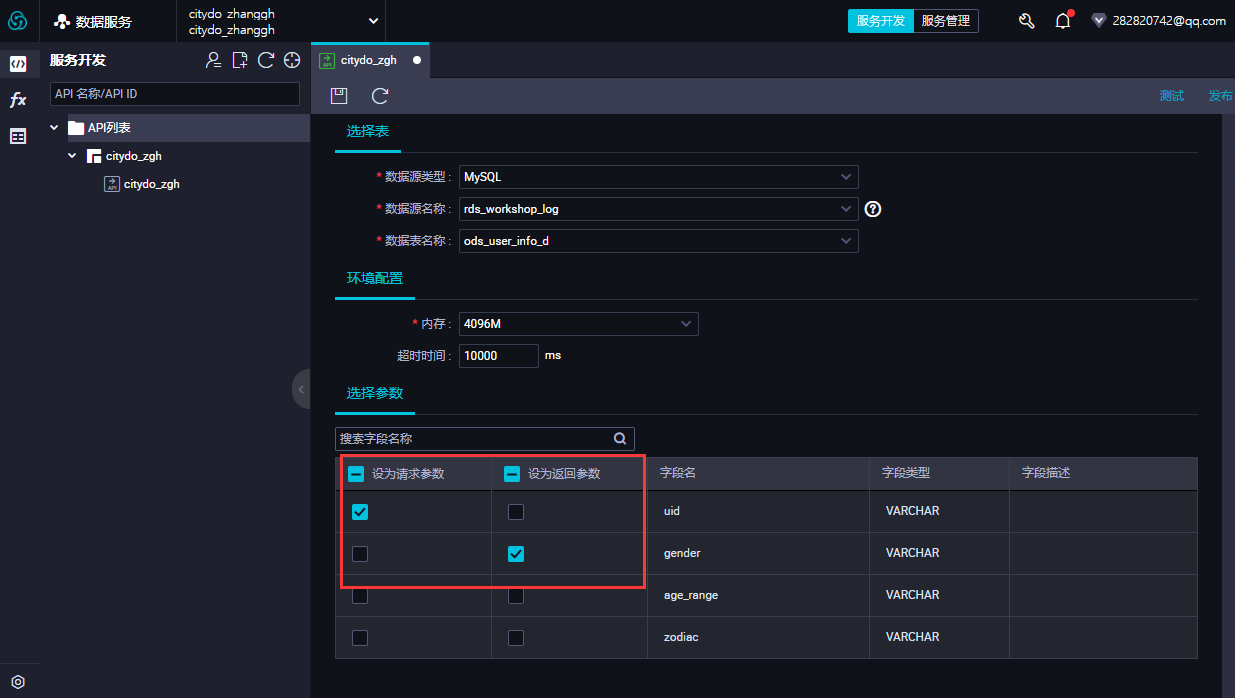
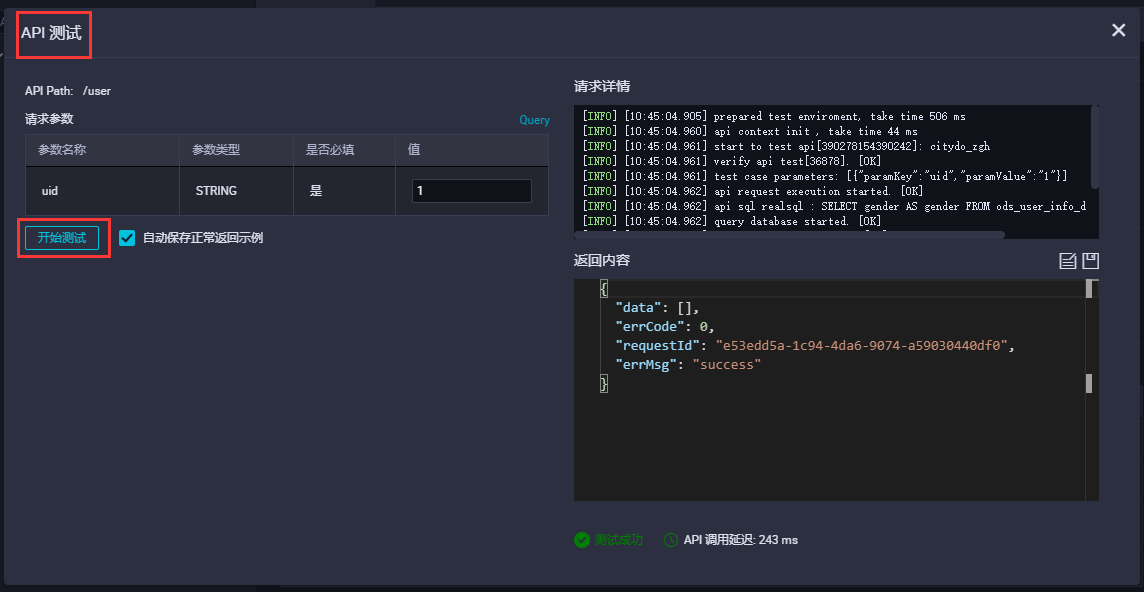
- 点击测试运行可以,检测API调用情况
- 完成后,点击发布即可
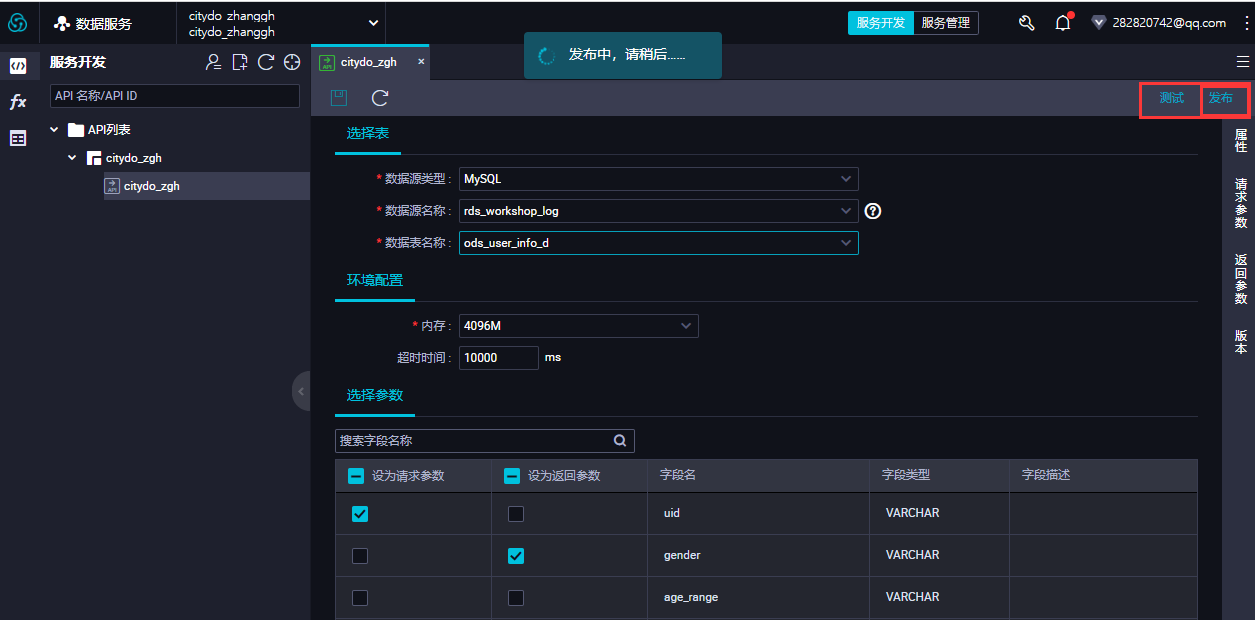
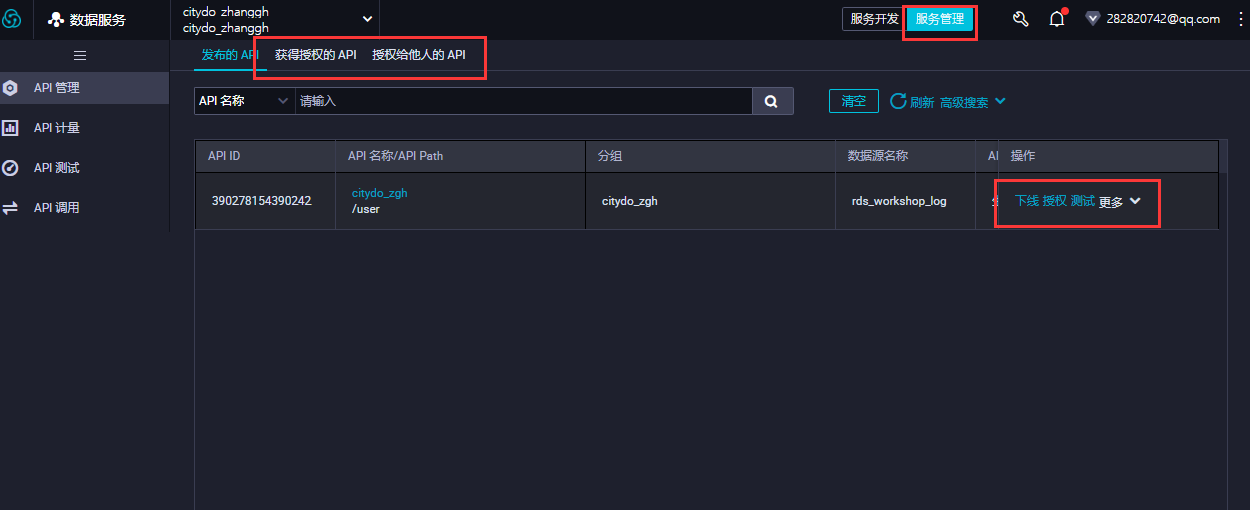
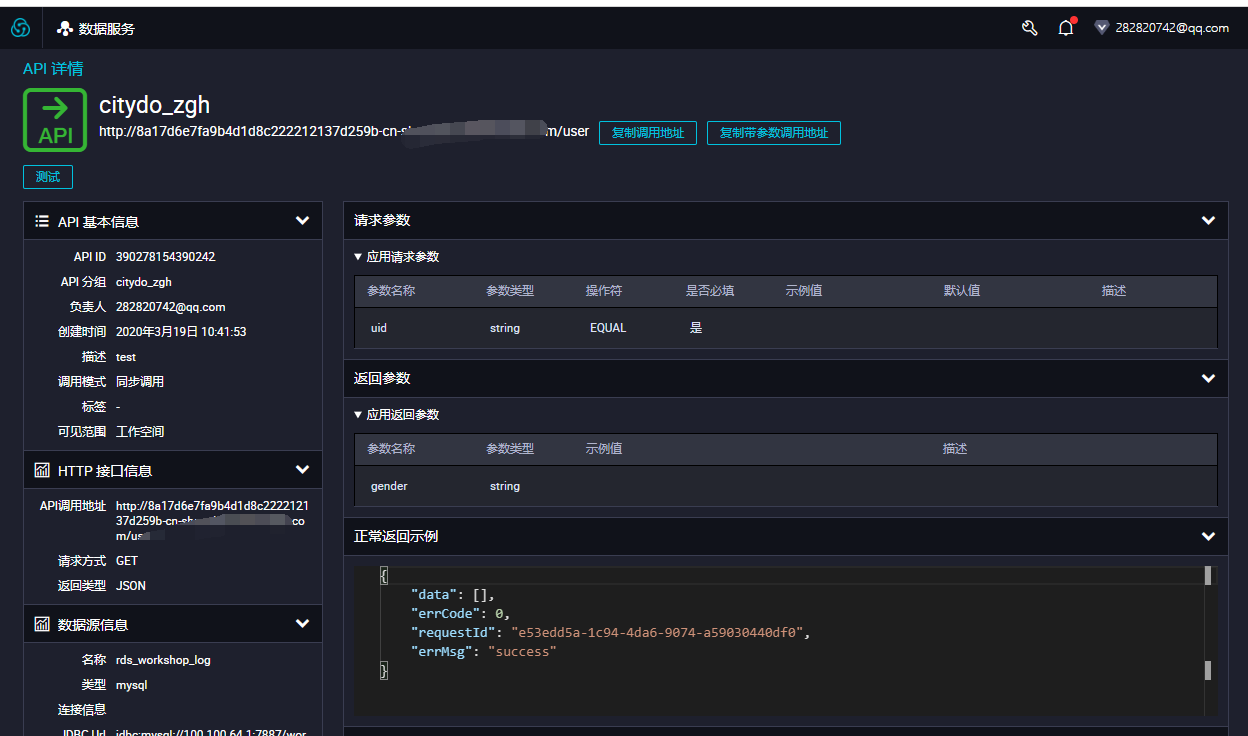
- 通过标签切换到服务管理,可以进行下线、授权、测试等管理;点击名称,可进入详情,查看API调用地址
- 主界面进入数据地图,可以看到当前的数据总览、全部数据、我的数据、配置管理、数据发现


























































