余弦定理计算文章相似度
实现思路
前些天看了阮一峰大神的文本相似度的实现思路于是就自己搞了一个效果还不错
句子A:我喜欢看电视,不喜欢看电影。
句子B:我不喜欢看电视,也不喜欢看电影。
1首先是分词,这里我用的是结巴分词。
句子A:我/喜欢/看/电视,不/喜欢/看/电影。
句子B:我/不/喜欢/看/电视,也/不/喜欢/看/电影。
2列出所有的词(使用tfidf算法提取20个关键词)
我,喜欢,看,电视,电影,不,也。
3计算词频
句子A:我 1,喜欢 2,看 2,电视 1,电影 1,不 1,也 0。
句子B:我 1,喜欢 2,看 2,电视 1,电影 1,不 2,也 1。
4列出词频向量
句子A:[1, 2, 2, 1, 1, 1, 0]
句子B:[1, 2, 2, 1, 1, 2, 1]
两条线段之间形成一个夹角,如果夹角为0度,意味着方向相同、线段重合;如果夹角为90度,意味着形成直角,方向完全不相似;如果夹角为180度,意味着方向正好相反。因此,我们可以通过夹角的大小,来判断向量的相似程度。夹角越小,就代表越相似。
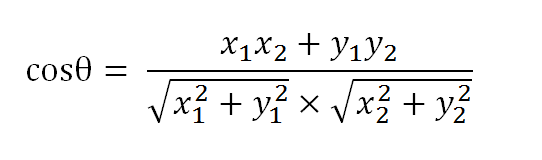
(ps:由于git对上传文件大小有限制程序里有些训练文本没有上传或者只上传了一部分,需要的话联系qq:1137543175)