Algorithm Engineer: Zac Tam Zher Min
Supervisor: Yan Xuyan
Table of Contents
- Introduction
- Requirement
- General Use-Case Demo
- Scenarios to be Accepted or Rejected by the Model
- v0.1 OpenCV Model
- v0.2 Pure C++ Model (w/o OpenCV)
- v0.3 Enlarged Input & Corner Scores
- v0.5 Strictly 3 Corners
- v0.6 Moving Average Corners
- Final Overall Model Architecture
- Final Tuneable Parameters
- Model Performance Evaluation
- Sources
This TD showcases a simple real-time card detector using non-deep learning, purely image processing OpenCV solution based on an open-source Android implementation on GitHub by using edge and corner detection to identify "cards". The goal is to then convert from the Python POC to a C++ API to be implemented in an APK, whereby the automatically captured image of the detected card will be passed to the e-KTP card type, flip and quality checks.
The whole model development processes are shown as below, taking an e-KTP card as an example:
- Use some traditional image processing methods to detect environment light condition, if there is enough light, go to the next step
- Use Edge Detection model to capture the card edge, if "at least 3 corners of the card are visible within the guided viewfinder", then image is captured, and send the image (the whole card with almost no background information) will go to the next step
- Develop card type check model, if confirm the card is KTP, then go to the next step
- Develop card flip check model, if confirm the card is in right direction, then go to the next step
- Develop card quality check model, if confirm the card is not blurry, block..., then go to the next step
This TD aims to handle the Edge Detection step amidst the entire e-KTP Auto Scanning pipeline shown above.
The target of this IC Edge Detection model is to allow "at least 3 corners of the card are visible within the guided viewfinder" before the process moves to the next step, "Card Type Check".
Note: Due to the low resolution of the webcam and low quality of the printed KTP card used in the video demos below, the words on the sample KTP card will not be very legible
| Scenario | Condition(s) | Expected Handling (Auto-Capture Decision) | Demo Video | Remarks |
|---|---|---|---|---|
| Happy Flow | All 5 critical requirements are met | Auto-capture should be triggered as it fulfils all 5 critical requirements: 1. Card is ID e-KTP; AND 2. Card is generally free of quality issue (not blurry, not blocked); AND 3. At least 3 corners of the card are visible within the guided viewfinder; AND 4. Well-lit condition (good lighting; not too dark, not too bright that it diminishes card details); AND 5. Card position is in a proper angle Auto-capture should be triggered |
||
| At least 3 corners of the card are visible within the guided viewfinder | Only 1 corner blocked | Auto-capture should be triggered as it fulfils all 5 critical requirements | The model will auto-capture even if the object is blocking the center of the card with the key information as long as it detects 3 corners | |
| Less than 3 corners of the card are visible within the guided viewfinder | 2 corners blocked by object | Auto-capture should not be triggered as "at least 3 corners of the card is visible" is a critical requirement | ||
| 3 corners blocked by object | Auto-capture should not be triggered as "at least 3 corners of the card is visible" is a critical requirement | |||
| Card is not horizontally aligned to the guided viewfinder | Auto-capture should not be triggered as "at least 3 corners of the card is visible" is a critical requirement | |||
| Card is not vertically aligned to the guided viewfinder | Auto-capture should not be triggered as "at least 3 corners of the card is visible" is a critical requirement | |||
| Card is too zoomed out, skewed or slanted away from the guided viewfinder | Auto-capture should not be triggered as "at least 3 corners of the card is visible" is a critical requirement | |||
| Edge Scenario | Condition(s) | Expected Handling (Auto-Capture Decision) | Demo Video | Remarks |
| Noisy backgrounds | Example: If holding the card in hand or on a background with many lines or dots | Auto-capture should be triggered as it fulfils all 5 critical requirements | This may not always auto-capture and some adjustments by the user may have to be made as the model may face difficulty in such scenarios especially if the user does not fully align the card in the guided viewfinder | |
| Similar coloured backgrounds | In the case of the KTP, a similar background colour would be blue and light backgrounds | Auto-capture should be triggered as it fulfils all 5 critical requirements | This may not always auto-capture and the user might have to position the card in front of a different background or try to hold it in hand | |
| Low exposure | General poor lighting conditions | Auto-capture should not be triggered as "well-lit condition (good lighting; not too dark, not too bright that it diminishes card details)" is a critical requirement | The model will still auto-capture if it can detect the 3 corners because it does not take into account the lighting conditions although the user should reposition to a better lighting condition | |
| Strong shadows blocking card features, resulting in poor lighting conditions | Shadows cast by the user or objects in the way of the light source | Auto-capture should not be triggered as "well-lit condition (good lighting; not too dark, not too bright that it diminishes card details)" is a critical requirement | As above | |
| High exposure blocking card features | Direct exposure to light source | Auto-capture should not be triggered as "well-lit condition (good lighting; not too dark, not too bright that it diminishes card details)" is a critical requirement | As above | |
| Glare blocking card features | Direct exposure to light source | Auto-capture should not be triggered as "well-lit condition (good lighting; not too dark, not too bright that it diminishes card details)" is a critical requirement | As above |

- Initialise either a webcam feed or video file
- Apply a rectangular mask over a frame to guide the card alignment for the user (handled on the app frontend)
- Process the frame to highlight the lines
- Crop and scale down the frame for faster processing
- Convert to grayscale
- Apply a Gaussian blur to reduce noise
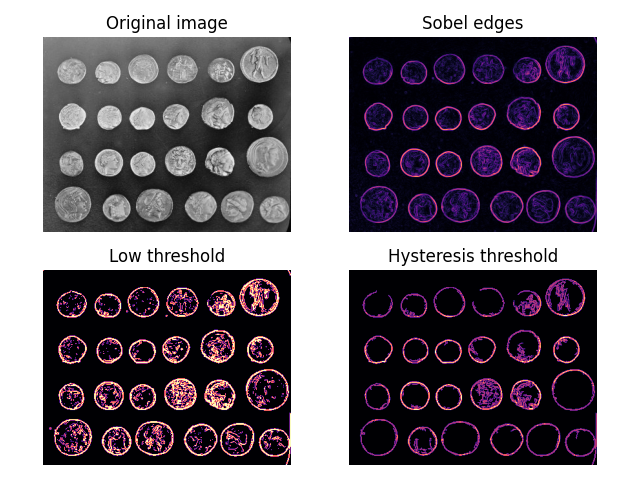
- Apply a Canny edge detector to detect edges
- The Canny edge detector is an image processing algorithm that takes in two parameters: a lower bound and upper bound
- The algorithm will then reject pixels if the pixel gradient is below the lower bound and accept instead if the gradient is above the upper bound
- If the gradient falls between these two bounds, the pixels will only be accepted if they are connected to pixels that are above the upper bound
- The 5-step Canny edge detector algorithm (From Wikipedia):
- Apply Gaussian filterto smooth the image in order to remove the noise (Repeat of previous step)
- Find the intensity gradients of the image
- Apply gradient magnitude thresholding or lower bound cut-off suppression to get rid of spurious response to edge detection
- Apply double threshold to determine potential edges
- Track edge by hysteresis: Finalise the detection of edges by suppressing all the other edges that are weak and not connected to strong edges
- The use of two thresholds with hysteresis allows more flexibility than a single-threshold approach, but general problems of thresholding approaches still apply
- A threshold set too high can miss important information but a threshold set too low will falsely identify irrelevant information (such as noise) as important
- It is difficult to give a generic threshold that works well on all images and no tried and tested approach to this problem yet exists as the thresholds are not dynamic during runtime
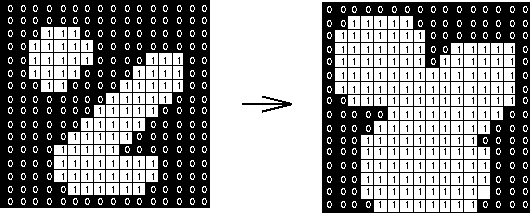
- Apply Dilation to thicken the edges so the lines are more easily found
- Based on a set sized window, eg. a 3x3 window, if within the window, at least 1 pixel is found to be non-black, it will colour the center of the window white
- This gives the effect of fattening the non-black regions
- Check for lines
- Section off the image into 4 areas: left, right, top and bottom
- Use Probabilistic Houghline Transform to find lines in each area by checking if each potential line meets 3 conditions:
- The number of intersection between curves (obtained using the mathematical polar coordinate representation of a line) meets a certain threshold
- Each potential line found must be long enough
- The gaps between potential lines must be short enough to be considered a single line
- The number of intersection between curves (obtained using the mathematical polar coordinate representation of a line) meets a certain threshold
- Check for corners
- Section off the image into the 4 corners: top left, top right, bottom left and bottom right
- Apply Shi-Tomasi corner detection to find corners in the 4 corner regions from the found lines
- At most 1 corner (set parameter) can be found by this algorithm
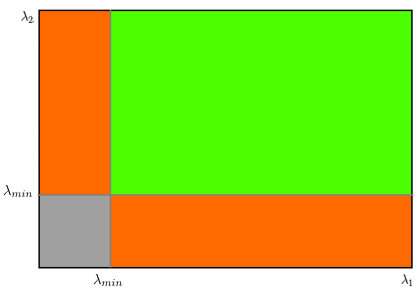
- This "corner" detection algorithm does not necessarily detect corners with a certain angle
- Rather, it finds regions of interest based on the pixel differences illustrated below, where red areas are equivalent to the "edges" and the entire green region is considered a corner if the region score R is above a set parameter
- Hence, even for straight-looking lines, it may sometimes falsely identify it as a corner regardless of how strict the corner detection parameter is set (from 0 to 1)
- The Shi-Tomasi algorithm is an improved "corner" detection algorithm to the Harris algorithm, although both face the same problems stated above
- Card is found if at least 3 corners found and be considered a "valid frame"
- Automatically captures the video frame after some Y milliseconds or the equivalent in some number of consecutive "valid frames" (depending on the device FPS)

- Relatively fast, around 10ms to process each frame for the Python implementation (excluding frame reading due to library and device limitations)
- Dim lighting is not as bad compared to glares as the edges can still be differentiated from the background
- If colours of the card borders are similar to the background, it will be harder to detect but still possible if parameters tuned to be sensitive
- Relatively straightforward to understand and implement if utilising OpenCV, using only around 5 key image processing algorithms excluding standard image processing steps such as cropping, scaling and grayscale
- Glare or strong light reflections causing certain areas of the frame to be completely white may hinder the detection
- If someone is holding the card in their hand or is generally in a noisy background, it can be hard to detect as well because the non-card lines can throw the model off
- We can prompt user to place the card flat on a surface before scanning
- The "corner" detection method also detects curves, which can cause false positives for the corners even if a corner is blocked
- This can be somewhat mitigated by adding the short delay before auto capture (some number of consecutive valid frames)
The OpenCV library takes up a lot of space (PC version is 500MB-1GB), even a minimal build with the key libraries for mobile devices will likely still take up 10+MB. The existing SeaBanking app as I understand is also not currently using OpenCV. Here are some possible solutions:
For prototyping v0.1, OpenCV was used as is, with most or all of the libraries included. This allows for easy testing and tuning as there is no worry about missing features or managing requirements. However, this will not be an option in the future as the overall SDK size increment limit is currently set to be 3MB.
We can replace existing functions such as Canny edge detector with a custom C++ open-sourced implementation. This will take some time and effort in researching and linking them up together to work as well as the current OpenCV prototype, which might impact performance.
Since the rest of the steps in the Auto Capture pipeline (Card Type/Flip and Quality Check) does not use OpenCV and are instead NN-based, we can completely eliminate the use of OpenCV along the entire pipeline and just use some simple custom image input and output functions to feed into the small MNN model. This is similar to the strategy employed by the Aurora Liveness Check app, which is purely NN-based as well. This approach will also require some time and effort to gather training data and train the model.

- Image masking, cropping and resizing will be done on the app's frontend
- After the Java preprocessing steps above, the edge detection model will receive a C++
byteArrayorunsigned char *input which has already been grayscaled - Use the custom C++ Canny edge detector and Hough Line transform algorithm
- Further crop and scale down the frame for faster processing
- The algo applies a Gaussian blur to reduce noise
- The algo then applies a Canny edge detector to detect edges (full details of the Canny algorithm can be found in the v0.1 TD)
- I believe the algo does not apply a Dilation to thicken the edges
- The algo finally applies the hough line transform to find lines
- Check for lines
- Section off the image into 4 areas: left, right, top and bottom
- Keep only the lines at the 4 side regions
- Check for corners
- Section off the image into the 4 corners: top left, top right, bottom left and bottom right
- Instead of using a corner detection algorithm like Shi-Tomasi (used in v0.1 OpenCV version), a simple algorithm to check for corners is used
- By checking if there are lines starting or ending at the 4 corner regions, we can get roughly the same performance as the Shi-Tomasi algorithm
- Draw the found lines and corners on a new image for debugging purposes
- Return the number of corners found; if 3 or 4 corners found, the auto-capture pipeline can move to the Card Type detection, else, it will restart from the beginning of the pipeline
- Guides the user to align the card edges exactly to the guided viewfinder
- Downstream neural network models are often trained on card images with almost no excess space around the card
- These NN models will continue to receive the cropped input frame directly from the guided viewfinder
- However, this card detection model will receive a slightly larger cropped frame to perform the edge detections outside of the guided viewfinder
- This is because the edge detection requires some gap to be able to differentiate edges from background
- This will be handled from the SDK Frontend, where cropping and frame inputs will be preprocessed before sending into this model and other NN models
- Possible improvement to the processing speed
- For the center exclusion area, change the pixel values to 0 to avoid line/edge detection there
- Runtime did not exhibit any noticeable change
- Runtime fluctuates from 15ms to 20ms with or without this implementation
- However additional challenges would be introduced
- Since exclusion area is completely skipped, certain lines/edges could be missed by the algorithm
- More loops will have to be run to preprocess the image, perhaps the reason for no net change in the runtime
- Trying to split the
unsigned char *frame into 4 separate regions is tedious without an image processing library like OpenCV- Additionally, the runtime might also increase due to the overhead of calling the Canny, Hough Transform and other post-processing algorithms 4 times
- Overall, this idea will likely not improve the model and might actually make it slightly worse due to further complications introduced

- A corner "accuracy" score is implemented to give more granular feedback and to allow the best frame to be picked if multiple frames with 4 corners are found
- Higher scores will be achieved if the user aligns the card as perfectly to the guided viewfinder as possible
- The model detection zone is from the red border to the yellow border; everything inside of the yellow zone is NOT scanned
- The scoring formula is calculated by checking the distance between the coordinates of the found corner against the guide view corner shown in the figure above

- Corners must have lines found in both side edges (instead of 1 edge)
- Mostly fixed partial and incomplete cards (< 3 corners)
- Improved stability due to slightly stricter corner logic

- Store set of 4 corner coordinates in a queue (deque)
- Queue size = Sliding window size; default=3
- Average them if found (not -1), eg. if size = 3:
- TL.x : [2, -1, 4] → [(2+4)/2] = [3] at the end
- TL.x : [2, -1, 4, -1, -1, -1] → [2, 2, 3, 4, 4, -1]
- Fix random frame drops resetting auto capture
- Above would have caused 4/6 rejections
- Also improves robustness to lighting changes and light backgrounds

struct {
float resizedWidth = 300; // new width of sized down image
float innerDetectionPercentWidth = 0.20; // x detection inside of guideview
float innerDetectionPercentHeight = 0.30; // y detection inside of guideview
float sigma = 1.5; // higher sigma for more gaussian blur
float cannyLowerThreshold = 10; // reject if pixel gradient below threshold
float cannyUpperThreshold = 20; // accept if pixel gradient above threshold
int houghlineThreshold = 70; // minimum intersections to detect a line
float houghlineMinLineLengthRatio = 0.40; // min length of line to detect
float houghlineMaxLineGapRatio = 0.20; // max gap between 2 potential lines
int queueSize = 3; // moving average window of consecutive frame corners
} params;| Parameter | Configuration [default | min | max] | Definition | Description | How to Decrease Strictness |
|---|---|---|---|---|
| cornerCannyLowerThreshold | [10 | 0 | MAX] | lower pixel gradient threshold to accept | decreasing this will take in more details in the image (higher sensitivity, decrease strictness) | Decrease this |
| cornerCannyUpperThreshold | [20 | 0 | MAX] | upper pixel gradient threshold to accept | decreasing this will also accept more details in the image (higher sensitivity), but usually higher than the lower threshold | Decrease this |
| cornerInnerDetectionPercentWidth | [0.2 | 0 | 1.0] | amount of x area to allow detection within guideview | amount of area to detect inside of guideview, controls how much user can zoom out and still detect the card | Increase this |
| cornerInnerDetectionPercentHeight | [0.3 | 0 | 1.0] | amount of y area to allow detection within guideview | amount of area to detect inside of guideview, controls how much user can zoom out and still detect the card | Increase this |
| cornerHoughlineMaxLineGapRatio | [0.2 | 0 | 1.0] | ratio x cornerResizedWidth | increasing will cause larger gaps to be accepted and joined together to form a line | Increase this |
| cornerHoughlineMinLineLengthRatio | [0.4 | 0 | 1.0] | ratio x cornerResizedWidth, right now it’s 300 x 0.1 = 30 pixels | decreasing will cause lines that are shorter to be accepted | Decrease this |
| cornerHoughlineThreshold | [70 | 0 | 300] | number of votes for a line to be accepted | decreasing this will lower the threshold to accept a line, making more lines and non-lines to be detected | Decrease this |
| cornerQueueSize | [3 | 1 | MAX] | size of moving average window | increasing this will allow more drop frames to still be accepted but the corners will update slower | Increase this |
| cornerResizedWidth | [300 | 0 | 440] | resize it smaller to speed up processing | increasing this will lose less details when downsizing the image but processing speed will be slower | Neutral |
| cornerSigma | [1.5 | 0 | 6.0] | the amount of blurring done to the image | increasing this will affect the image smoothening but take in more noise that we might think is not there | Neutral |
- Size: From 17MB with OpenCV to 42KB pure C++ version
- Speed: Around 15-20ms
- Accuracy & Stability: Did not manage to evaluate on any benchmark dataset
- Library overall is written in both Java and C++ with the help of OpenCV (but the file size is big because they imported most or all of the libraries)
- The repository was last updated ~2019, using a depreciated Android camera library from ~2018-2019, around 3-4 years ago
- Outdated camera library (depreciated in 2019 but still functions): Google’s open source CameraView
- More updated Android Camera API: Jetpack CameraX
- CameraView & CameraX are Android APIs to use the smartphone’s cameras to get the video stream, the rest of the implementation works fine till this day