
![]()
Snowplow is an enterprise-strength marketing and product analytics platform. It does three things:
- Identifies your users, and tracks the way they engage with your website or application
- Stores your users' behavioral data in a scalable "event data warehouse" you control: Amazon Redshift, Google BigQuery, Snowflake or Elasticsearch
- Lets you leverage the biggest range of tools to analyze that data, including big data tools (e.g. Spark) via EMR or more traditional tools e.g. Looker, Mode, Superset, Re:dash to analyze that behavioral data
To find out more, please check out the Snowplow website and the docs website.
For compatibility assurance, the version compatibility matrix offers clarity on our recommended stack. It is strongly recommended when setting up a Snowplow pipeline to use the versions listed in the version compatibility matrix which can be found within our docs.
This repository also contains the Snowplow Public Roadmap. The Public Roadmap lets you stay up to date and find out what's happening on the Snowplow Platform. Help us prioritize our cards: open the issue and leave a 👍 to vote for your favorites. Want us to build a feature or function? Tell us by heading to our Discourse forum 💬.
Setting up a full open-source Snowplow pipeline requires a non-trivial amount of engineering expertise and time investment. You might be interested in finding out what Snowplow can do first, by setting up Try Snowplow.
If you wish to get everything setup and managed for you, you can consider Snowplow Insights. You can also request a demo.
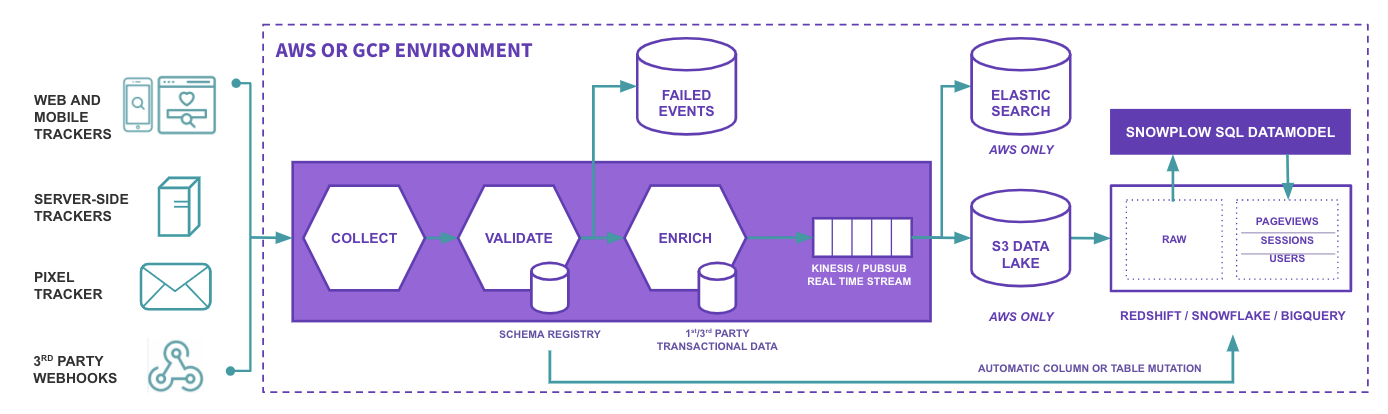
The repository structure follows the conceptual architecture of Snowplow, which consists of six loosely-coupled sub-systems connected by five standardized data protocols/formats.
To briefly explain these six sub-systems:
- Trackers fire Snowplow events. Currently we have 15 trackers, covering web, mobile, desktop, server and IoT
- Collector receives Snowplow events from trackers. Currently we have one official collector implementation with different sinks: Amazon Kinesis, Google PubSub, Amazon SQS, Apache Kafka and NSQ
- Enrich cleans up the raw Snowplow events, enriches them and puts them into storage. Currently we have several implementations, built for different environments (GCP, AWS, Apache Kafka) and one core library
- Storage is where the Snowplow events live. Currently we store the Snowplow events in a flat file structure on S3, and in the Redshift, Postgres, Snowflake and BigQuery databases
- Data modeling is where event-level data is joined with other data sets and aggregated into smaller data sets, and business logic is applied. This produces a clean set of tables which make it easier to perform analysis on the data. We officially support data models for Redshift, Snowflake and BigQuery.
- Analytics are performed on the Snowplow events or on the aggregate tables.
For more information on the current Snowplow architecture, please see the Technical architecture.
This repository is an umbrella repository for all loosely-coupled Snowplow components and is updated on each component release.
Since June 2020, all components have been extracted into their dedicated repositories (more info here) and this repository serves as an entry point for Snowplow users, the home of our public roadmap and as a historical artifact.
Components that have been extracted to their own repository are still here as git submodules.
- BigQuery (streaming)
- Redshift (batch)
- Snowflake (batch)
- Google Cloud Storage (streaming)
- Amazon S3 (streaming)
- Postgres (streaming)
- Elasticsearch (streaming)
- Analytics SDK Scala
- Analytics SDK Python
- Analytics SDK .NET
- Analytics SDK Javascript
- Analytics SDK Golang
We want to make it super-easy for Snowplow users and contributors to talk to us and connect with each other, to share ideas, solve problems and help make Snowplow awesome. Here are the main channels we're running currently, we'd love to hear from you on one of them:
This is for all Snowplow users: engineers setting up Snowplow, data modelers structuring the data and data consumers building insights. You can find guides, recipes, questions and answers from Snowplow users including the Snowplow team.
We welcome all questions and contributions!
@SnowplowData for official news or @SnowplowLabs for engineering-heavy conversations and release updates.
If you spot a bug, then please raise an issue in the GitHub repository of the component in question. Likewise if you have developed a cool new feature or an improvement, please open a pull request, we'll be glad to integrate it in the codebase!
If you want to brainstorm a potential new feature, then Discourse is the best place to start.
community@snowplowanalytics.com
If you want to talk directly to us (e.g. about a commercially sensitive issue), email is the easiest way.
Snowplow is copyright 2012-2021 Snowplow Analytics Ltd.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this software except in compliance with the License.
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the specific language governing permissions and limitations under the License.