Implementation of Using Fast Weights to Attend to the Recent Past
Using Fast Weights to Attend to the Recent Past
Jimmy Ba, Geoffrey Hinton, Volodymyr Mnih, Joel Z. Leibo, Catalin Ionescu
NIPS 2016, https://arxiv.org/abs/1610.06258
More details @ https://theneuralperspective.com/2016/12/04/implementation-of-using-fast-weights-to-attend-to-the-recent-past/
Use fast weights to aid in learning associative tasks and store temporary memories of recent past. In a traditional recurrent architecture we have our slow weights which are used to determine the next hidden state and hold long-term memory. We introduce the concept of fast weights, in conjunction with the slow weights, in order to account for short-term knowledge. These weights are quick to update and decay as they change from the introduction of new hidden states.
The overall task of the fast weights is to quickly be able to adjust to recent hidden states while remembering the recent past. You use the fast weights to determine the final hidden state at each time step. Though BPTT does not directly change our fast weights (these fast weights A are unique for each sample actually), BPTT does affect the hidden states states' weights, and recall that fast weights do affects our hidden states (and vice versa). So with training, we affect our slow weights (Wh and Wx) which intern affects how our fast weights are determined. Eventually, they will be determined as to keep track of the recent past so we can create hidden states that lead to the correct answer.
Physiological Motivations
How do we store memories? We don't store memories by keeping track of the exact neural activity that occurred at the time of the memory. Instead, we try to recreate the neural activity through a set of associative weights which can map to many other memories as well. This allows for efficient storage of many memories without storing separate weights for each instance. This associative network also allows for associative learning which is the ability to learn the recall the relationship between initially unrelated instances.(1)

Concept
-
In a traditional recurrent architecture we have our slow weights. These weights are used with the input and the previous hidden state to determine the next hidden state. These weights are responsible for the long-term knowledge of our systems. These weights are updated at the end of a batch, so they are quite slow to update and decay.
-
We introduce the concept of fast weights, in conjunction with the slow weights, in order to account for short-term knowledge. These weights are quick to update and decay as they change from the introduction of new hidden states.
-
For each connection in our network, the total weight is the sum of the results from both the slow and fast weights. The hidden state for each time step for each input is determined by the operations with the slow and fast weights. We use a fast memory weights matrix A to alter the hidden states to keep track of the features required for any associative learning tasks.
-
The fast weights memory matrix, A(t), starts with 0 at the beginning of the sequence. Then all the inputs for the time step are processed and A(t) is updated with a scalar decay with the previous A(t) and the outer product of the hidden state with a scalar operation with learning rate eta.

- For each time step, the same A(t) is used for all the inputs and for all S steps of the "inner loop". This inner loop is transforming the previous hidden state h(t) into the next output hidden state h(t+1). For our toy task, S=1 but for more complicated tasks where more associate learning is required, we need to increase S.

Efficient Implementation
- If a neural net, we compute our fast weights matrix A by changing synapses but if we want to employ an efficient computer simulation, we need to utilize the fact that A will be <full rank matrix since number of time steps t < number of hidden units h. This means we might not need to calculate the fast weights matrix explicitly at all.

- We can rewrite A by recursively applying it (assuming A=0 @ beginning of seq.). This also allows us to compute the third component required for the inner loop's hidden state vector. We do not need to explicitly compute the fast weights matrix A at any point! The real advantage here is that now we do not have to store a fast weights matrix for each sequence in the minibatch, which becomes a major space issue for forward/back prop on multiple sequences in the minibatch. Now, we just have to keep track of the previous hidden states (one row each time step).

Notice the last two terms when computing the inner loops next hidden vector. This is just the scalar product of the earlier hidden state vector, h(\tau ), and the current hidden state vector, hs(t+ 1) in the inner loop. So you can think of each iteration as attending to the past hidden vectors in proportion to the similarity with the current inner loop hidden vector.
We do not use this method in our basic implementation because I wanted to explicitly show what the fast weights matrix looks like and having this "memory augmented" view does not really inhibit using minibatches (as you can see). But the problem an explicit fast weights matrix can create is the space issue, so using this efficient implementation will really help us out there.
Note that this 'efficient implementation' will be costly if our sequence length is greater than the hidden state dimensionality. The computations will scale quadratically now because since we need to attend to all previous hidden states with the current inner loop's hidden representation.
Requirements
- tensorflow (>0.10)
Execution
- To see the advantage behind the fast weights, Ba et. al. used a very simple toy task.
Given: g1o2k3??g we need to predict 1.
-
You can think of each letter-number pair as a key/value pair. We are given a key at the end and we need to predict the appropriate value. The fast associative memory is required here in order to keep track of the key/value pairs it has just seen and retrieve the proper value given a key. After backpropagation, the fast memory will give us a hidden state vector, for example after g and 1, with a part for g and another part for 1 and learn to associate the two together.
-
Create datasets:
python data_utils.py- For training:
python train.py train <model_name: RNN-LN-FW | RNN-LN | CONTROL | GRU-LN >- For sampling:
python train.py test <model_name: RNN-LN-FW | RNN-LN | CONTROL | GRU-LN >- For plotting results:
python train.py plotResults
- Control: RNN without layer normalization (LN) or fast weights (FW)
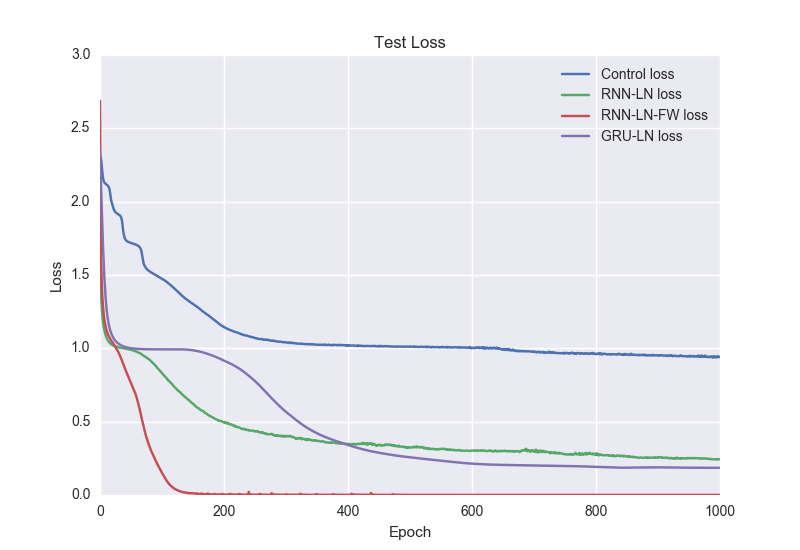
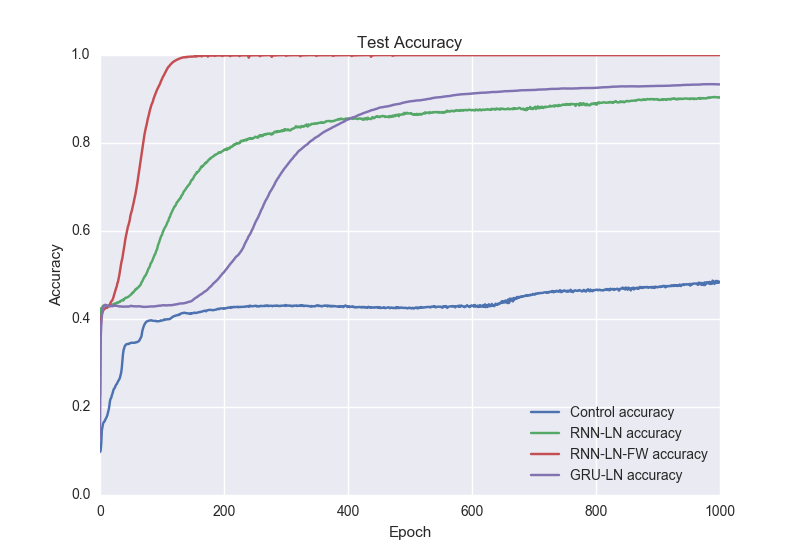


Bag of Tricks
- Initialize slow hidden weights with an identity matrix in RNN to avoid gradient issues.(2)
- Layer norm is required when using an RNN for convergence.
- Weights should be properly initialized in order to have unit variance after the dot product, prior to non-linearity or else things can blow up really quickly.
- Keep track of the gradient norm and tune accordingly.
- No need to add extra input processing and extra layer after softmax as Jimmy Ba did. (He was doing that simply to compare with another task so it will just add extra computation if you blindly follow that).
Extensions
-
I will be releasing my code comparing fast weights with an attention interface for language related sequence to sequence tasks (in a sep repo).
-
It will also be interesting to compare the computational demands of fast weights compared to LSTM/GRUs and see which one is better for test time.
Citations
- Suzuki, Wendy A. "Associative Learning and the Hippocampus." APA. American Psychological Association, Feb. 2005. Web. 04 Dec. 2016.
- Hinton, Geoffrey. "FieldsLive Video Archive." Fields Institute for Research in Mathematical Sciences. University of Toronto, 13 Oct. 2016. Web. 04 Dec. 2016.
Author
Goku Mohandas (gokumd@gmail.com)