Getting Started
git clone https://github.com/attractivechaos/udb2
cd udb2
# compile directories that include the library code; C++11/14 required for some libraries
make
# run benchmarks for compiled programs
ls */run-test*|grep -v log|xargs -i echo '{} > {}.log 2>&1'|shIntroduction
This repo implements a micro-benchmark to evaluate the performance of various hashtable libraries in C/C++. Each library is given N 32-bit integers with ~25% of them are distinct. The task is to find the occurrence of each distinct integer with a dictionary. To show the effect of rehashing, the benchmark program runs the task for six rounds with N set to 10, 18, 26, 34, 42 and 50 million, respectively.
Each directory in this repo typically corresponds to one library. Directories
not prefixed with underscores include the library source code and can be
compiled without external dependencies (warning: most C++ libraries require
C++11). Directories prefixed with underscores require third-party libraries or
compiler-specific extensions. They are not compiled when you type make. You
have to install the external dependencies first and then compile manually by
yourself.
Results
Complete results can be found in the __logs directory. The following figure shows the memory vs runtime when the benchmark is run on "n1-standard-1" machine from the Google Cloud:
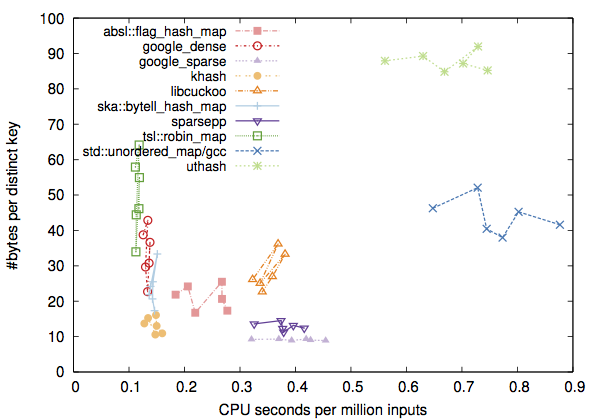
It is worth noting that the results vary with machines. The following figure was derived from runs on a Linux server with a much larger cache (CPU: Xeon E5-2683 v3, 2.0GHz, 35MB cache; memory: 640GB; gcc: v5.4.0):
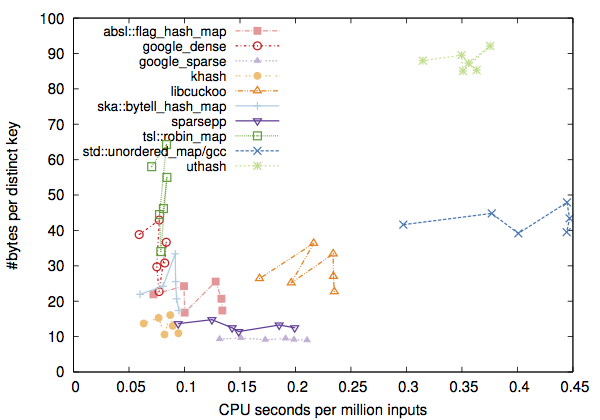
The companion blog post gives more context about this benchmark.