
A research framework for Deep Reinforcement Learning using Unity, OpenAI Gym, PyTorch, Tensorflow.
Github Repo | Lab Documentation | Experiment Log Book
This lab is for general deep reinforcement learning research, built with proper software engineering:
- baseline algorithms
- OpenAI gym, Unity environments
- modular reusable components
- multi-agents, multi-environments
- scalable hyperparameter search with ray
- useful graphs and analytics
- fitness vector for universal benchmarking of agents, environments
Work in progress.
The implemented baseline algorithms (besides research) are:
- SARSA
- DQN
- Double DQN
- REINFORCE
- Option to add entropy to encourage exploration
- Actor-Critic
- Batch or episodic training
- Shared or separate actor and critic params
- Advantage calculated using n-step returns or generalized advantage estimation
- Option to add entropy to encourage exploration
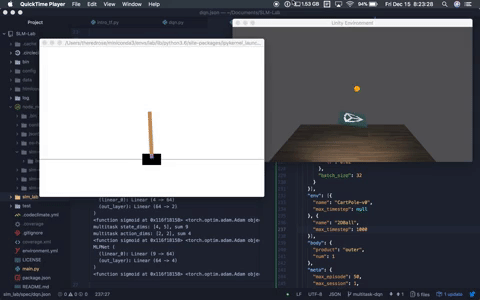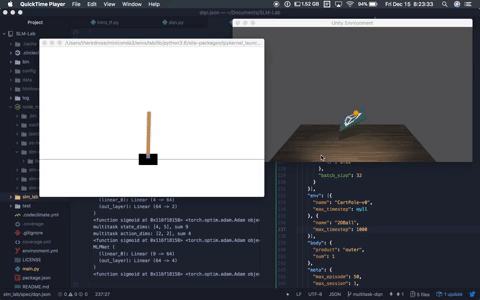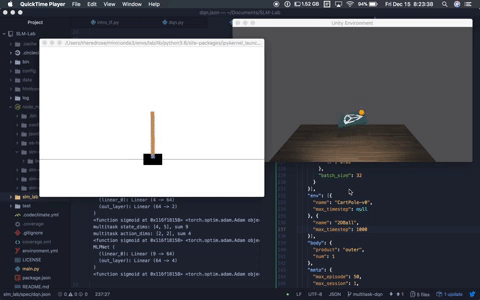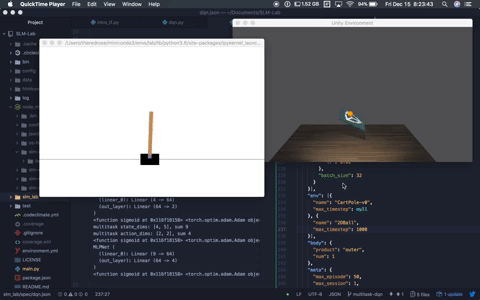
A multitask agent solving both OpenAI Cartpole-v0 and Unity Ball2D.

Experiment graph showing fitness from hyperparameter search.

Example total reward and loss graph from a session.
Read on for tutorials, research and results.
Github Repo | Lab Documentation | Experiment Log Book
-
Clone the SLM-Lab repo:
git clone https://github.com/kengz/SLM-Lab.git
-
Install dependencies (or inspect
bin/setup_*first):cd SLM-Lab/ bin/setup yarn install source activate lab
Alternatively, run the content of
bin/setup_macOSorbin/setup_ubuntuon your terminal manually.
A config file config/default.json will be created.
{
"data_sync_dir": "~/Dropbox/SLM-Lab/data",
"plotly": {
"username": "get from https://plot.ly/settings/api",
"api_key": "generate from https://plot.ly/settings/api"
}
}- update
"data_sync_dir"if you run lab on remote and want to sync data for easy access; it will copydata/there. - for plots, sign up for a free Plotly account and update the
"plotly"JSON key.
To update SLM Lab, pull the latest git commits and run update:
git pull
yarn updateRun the demo to quickly see the lab in action (and to test your installation).

It is VanillaDQN in CartPole-v0:
-
see
slm_lab/spec/demo.jsonfor example spec:"dqn_cartpole": { "agent": [{ "name": "VanillaDQN", "algorithm": { "name": "VanillaDQN", "action_policy": "boltzmann", "action_policy_update": "linear_decay", "gamma": 0.999, ... } }] }
-
see
config/experiments.jsonto schedule experiments:"demo.json": { "dqn_cartpole": "train" }
-
launch terminal in the repo directory, run the lab:
source activate lab yarn start -
This demo will run a single trial using the default parameters, and render the environment. After completion, check the output for data
data/dqn_cartpole/. You should see a healthy session graph. -
Next, change the run mode from
"train"to"search"config/experiments.json, and rerun. This runs experiments of multiple trials with hyperparameter search. Environments will not be rendered.:"demo.json": { "dqn_cartpole": "search" }
If the quick start fails, consult Debugging.
Now the lab is ready for usage.
Read on: Github Repo | Lab Documentation | Experiment Log Book
If you use SLM-Lab in your research, you can cite it as follows:
@misc{kenggraesser2017slmlab,
author = {Wah Loon Keng, Laura Graesser},
title = {SLM-Lab},
year = {2017},
publisher = {GitHub},
journal = {GitHub repository},
howpublished = {\url{https://github.com/kengz/SLM-Lab}},
}
If you're interested in using the lab for research, teaching or applications, please contact the authors.