channel pruning and distillation for mobile-yolov5 (applied to android)
yolov5s的计算量和参数量分别为8.39G和7.07M。部署在android上的推理速度仍然有提升的空间。本项目主要从模型端入手,通过替换backbone(mobilenetv2),通道剪枝对模型进行压缩。 利用yolov5对剪枝后的模型进行蒸馏finetune。
数据集采用Pascal VOC,trainset = train2007+train2012+val2007+val2012,testset = test2007,Baseline采用mobile-yolo(imagenet预训练)第一个模块采用Focus
如果未经特殊说明则均为使用默认参数,batchsize=24,epoch=50,train_size = 640,test_size = 640,conf_thres=0.001,iou_thres=0.6,mAP均为50
PS. 由于资源有限,此项目只训练50个epoch,实际上可以通过调整学习率和迭代次数进一步提高mAP。但是可以通过控制相同的超参数来进行实验对比,所以并不影响最终结果。
baseline由4个部分组成:yolov5s,官方提供的coco权重在voc上进行微调所以不具备可比性,但是可以作为蒸馏指导模型;mobilev2-yolo5s和mobilev2-yolo5l均是只更改了对应的backbone;mobilev2-yolo3则是用的yolo3head,结构同https://github.com/Adamdad/keras-YOLOv3-mobilenet 基本一致(keras的是mobilev1,参数量和计算量更大),此处作为参照物。
| Model | Precision | Recall | mAP | Params(M) | Flops(G) |
|---|---|---|---|---|---|
| yolo5l | 0.659 | 0.881 | 0.862 | 49.90 | 57.52 |
| yolo5s | 0.536 | 0.863 | 0.809 | 7.07 | 8.39 |
| mobilev2-yolo3 | 0.458 | 0.838 | 0.755 | 22.05 | 19.65 |
| mobilev2-yolo5l | 0.496 | 0.807 | 0.741 | 15.38 | 16.72 |
| mobilev2-yolo5s | 0.457 | 0.809 | 0.719 | 3.62 | 4.72 |
由于yolo5s用了coco权重,实际上是不具备可比性的,然而我们可以利用他作为Teacher模型对小模型进行蒸馏。mobilev2-yolo3是验证github上keras版本 在此项目中的表现,忽略一些不同的超参选择,mAP在一个点之内是可以接受的。不过mobilev2-yolo3的参数量和计算量还是太大了(主要是head的branch), 于是用yolo5的head构建了mobilev2-yolo5l和mobilev2-yolo5s。可以看出随着参数量和计算量的下降,mAP也是在非线性下降。 而yolov5独有的focus模块表现并不好,对精度基本上没有任何影响,反而还提升了模型计算量。
从baseline中可以看出mobilev2-yolo5s整体的计算量已经很少了,不过在追求高性能的路上还是有压缩的空间的。 我们选取mobilev2-yolo5s作为剪枝的基础模型。以以下策略为基础:
- 输出层不动,统计其他所有BN层的weight分布
- 根据稀疏率决定剪枝阈值
- 开始剪枝,如果当前层所有值均小于阈值则保留最大的一个通道(保证结构不被破坏)
| Model | Precision | Recall | mAP | ex-epoch | sl | Prune_prob | Params(M) | Flops(G) |
|---|---|---|---|---|---|---|---|---|
| mobilev2-yolo5s | 0.457 | 0.809 | 0.719 | - | - | - | 3.62 | 4.72 |
| mobilev2-yolo5s | 0.407 | 0.793 | 0.687 | - | 6e-4 | - | 3.62 | 4.72 |
| pruning 1 | 0.427 | 0.695 | 0.604 | 10 | 6e-4 | thres=0.01 | 2.7 | 3.84 |
| pruning 2 | 0.384 | 0.821 | 0.699 | 20 | 6e-4 | thres=0.01 | 2.7 | 3.84 |
| pruning 3 | 0.337 | 0.704 | 0.555 | 20 | 6e-4 | 0.5 | 1.88 | 3.08 |
-
先从头训练一个baseline,以及训练一个对bn中gamma参数加入L1正则化的网络。稀疏参数为sl=6e-4。结果比baseline掉了3个点。
-
剪枝策略按照论文中的做法给定一个稀疏率,统计所有参与剪枝层的bn参数l1值并进行排序,依据稀疏率确定阈值。
-
将所有小于阈值的层全部减掉,如果有依赖则将依赖的对应部分也剪掉。如果一层中所有的层都需要被移除,那么就保留最大的一层通道(保证网络结构)
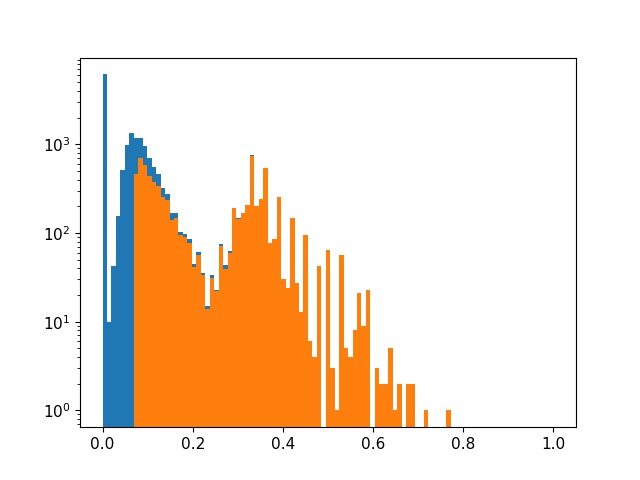
-
不过还可以看出一个问题,就是选的0.5稀疏率太大了,把很多并不小的层都剪切掉了。说明我们对应当前sl训练出来的模型,使用0.5的稀疏率不够好,这次我们不按照稀疏率来剪枝,而是给定一个非常小的值0.01。
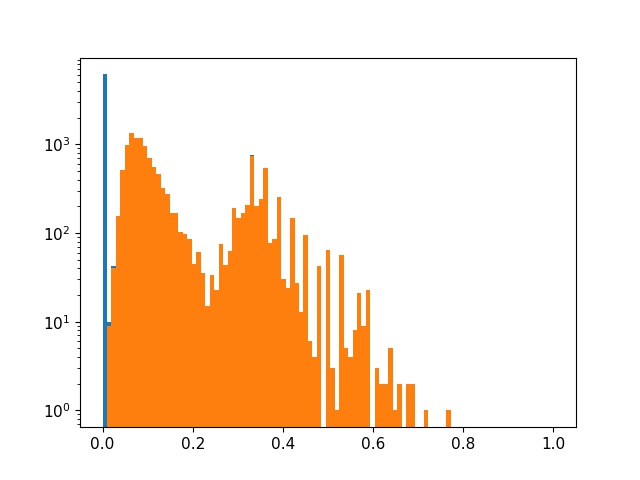
-
finetune 10个epoch。mAP是0.604掉点严重,不过注意到是用的cos学习率,在训练末期val acc还在上涨。为了验证是否是finetune训练次数不够,此时尝试训练20个epoch,map果然上升到0.699。 此时剪枝过后的mAP已经超过稀疏训练的baseline了。不过不排除是因为多训练了20个epoch的原因。


我们以mobilev2-yolo5s作为S-model,希望能将T-model在coco和voc上学习到的知识蒸馏到mobilev2-yolo5s中。以Object detection at 200 Frames Per Second为基础方法配置蒸馏损失函数,抑制背景框带来的类别不均衡问题。 用L2 loss作为蒸馏基础函数。损失中的蒸馏dist平衡系数选择为1。
- 选取基于darknet为backbone的yolo5s作为T模型。这样能尽可能的保证结构上的一致。而yolo5s的参数量和计算量差不多正好是mobilev2-yolo5s的两倍, capacity gap并不是很明显。蒸馏后提了接近3个点。
| Model | Precision | Recall | mAP | Params(M) | Flops(G) |
|---|---|---|---|---|---|
| T-yolo5s | 0.536 | 0.863 | 0.809 | 7.07 | 8.39 |
| mobilev2-yolo5s | 0.457 | 0.809 | 0.719 | 3.62 | 4.72 |
| S-mobilev2-yolo5s | 0.296 | 0.876 | 0.746 | 3.62 | 4.72 |
- 选取yolo5l作为T模型,精度更高,但是gap更大,可以看到蒸馏后提升很少。
| Model | Precision | Recall | mAP | Params(M) | Flops(G) |
|---|---|---|---|---|---|
| T-yolo5l | 0.659 | 0.881 | 0.862 | 49.90 | 57.52 |
| mobilev2-yolo5s | 0.457 | 0.809 | 0.719 | 3.62 | 4.72 |
| S-mobilev2-yolo5s | 0.233 | 0.879 | 0.724 | 3.62 | 4.72 |
| Model | instruction |
|---|---|
| yolo5s | python3 train.py --type voc |
| mobilev2-yolo3 | python3 train.py --type mvoc3 |
| mobilev2-yolo5l | python3 train.py --type mvocl |
| mobilev2-yolo5s | python3 train.py --type mvocs |
| Model | instruction |
|---|---|
| sparse learning | python3 train.py --type smvocs |
| pruning | python3 pruning.py -t 0.1 |
| finetune | python3 train.py --type fsmvocs |
| Model | instruction |
|---|---|
| distillation | python3 train.py --type dmvocs |
export PYTHONPATH=$PWD
python3 test.py --weights 权重路径
- python3 model/onnx_export.py --weights weight_path
- 参考https://github.com/Syencil/tensorRT
- 在将onnx转换为ncnn格式的时候,发现focus模块的slice无法直接转换。发现是step=2的原因。
针对这个问题,有3个方案:用4个原图叠加然后推理;用Conv代替Focus重新训一个;修改ncnn的代码迫使其支持step!=1的slice操作。
- 在sunnyden/YOLOV5_NCNN_Android#2中直接将4个原图叠在一起。这看起来很方便,实际上是将输入图像大小扩大了一倍。为了弥补计算量上的增多只能原图输入尺寸降成原来的一半,带来的就是精度的损失。
- 如果在ncnn中实现的话,单纯实现step=2的Slice操作对性能影响很大(内存不连续)所以需要将整个focus模块拿出来实现,这样onnx的导出部分也得改.
- 用Conv重新训练一个模型,从以上实验可以看出Conv替换Focus之后精度并没有任何变化(0.1这种算正常扰动),计算量和参数量反而小了。
| Model | Precision | Recall | mAP | Params(M) | Flops(G) |
|---|---|---|---|---|---|
| mobilev2-yolo3(conv) | 0.462 | 0.838 | 0.756 | 22.05 | 19.38 |
| mobilev2-yolo3(focus) | 0.458 | 0.838 | 0.755 | 22.05 | 19.65 |
| mobilev2-yolo5s(conv) | 0.423 | 0.819 | 0.718 | 3.61 | 4.46 |
| mobilev2-yolo5s(focus) | 0.457 | 0.809 | 0.719 | 3.62 | 4.72 |
| S-mobilev2-yolo5s(conv) | 0.333 | 0.866 | 0.744 | 3.61 | 4.46 |
| S-mobilev2-yolo5s(focus) | 0.296 | 0.876 | 0.746 | 3.62 | 4.72 |
其中focus代表第一个模块采用yolov5的focus模块,conv则是采用stride=2的3x3卷积作为第一个模块。 根据以上结论,我们采用重新训练了一个模型,并进行蒸馏得到S-mobilev2-yolo5s(conv)。利用onnx2ncnn将其转换并部署到android
-
TnesorRT中的tensor内存是连续模型,然而在ncnn中采用腾讯自己的mat格式,并不能保证channel之间的内存是连续性的。 这就导致无法按照之前tensorRT的后处理(BHWAC)来进行。在导出的时候尽量保证BCHW的格式,这样在ncnn中没有个channel中的值才是连续的、可解释的。
-
有一个比较坑的点:由于用的是nn.Upsample进行上采样,在导出为onnx格式的时候,resize操作中只保存了输出outputsize而不是scale。 这导致在转ncnn的时候,将其转换为Interp操作的时候直接将outputsize固定了。然而Onnx和trt中输入是固定的,在ncnn中是动态尺寸输入,这就会导致m和l的输出大小永远不变。