N, K, M = input().strip().split(' ')
# 输出
print() class ListNode(object):
def __init__(self, val=0, next=None):
self.val = val
self.next = next
def __le__(self,other):
#定义less than函数,如果涉及到节点的val比较大小
return self.val<=other.val
def __ge__(self,other):
return self.val>other.val
# 如果链表结构已经定义好了,可以通过传一个函数进去,修改原来类内部的函数
class ListNode(object):
def __init__(self, val=0, next=None):
self.val = val
self.next = next
#如
ListNode.__le__ = lambda x,y:x.val<=y.val
#或者
def __le__(self.other):
ListNode.__le__ = __le__- 二叉树操作最好不要动给定的数组,可以使用start index 和 end index 调整
class TreeNode(object):
def __init__(self, val=0, left=None, right=None):
self.val = val
self.left = left
self.right = right

class VisitedVertex(object):
def __init__(self, vertex_num):
self.visited = [False for i in range(vertex_num)]
self.dis = [float('inf') for i in range(vertex_num)]
self.pre = [0 for i in range(vertex_num)]
class DijsktraGraph(object):
def __init__(self, vertexes, edges):
self.vertexes = vertexes
self.edges = edges
self.vv = VisitedVertex(len(vertexes))
def dijsktra(self, start):
"""
使用迪杰斯特拉算法计算某一个点到其他顶点的最短路径
:param start:
:return:
"""
# 标记起始顶点被访问
self.vv.visited[start] = True
# 标记起始顶点与自己的距离为0
self.vv.dis[start] = 0
self.update(start)
for i in range(len(self.vertexes)):
new_index = self.get_new_index()
self.update(new_index)
def get_new_index(self):
"""
当起始顶点访问之后需要找到下一层需要访问的顶点,找到该顶点到其他顶点距离最小的即为目标顶点
:param index:
:return:
"""
min_dis = float('inf')
index = 0
for i in range(len(self.vv.visited)):
if not self.vv.visited[i] and self.vv.dis[i] < min_dis:
min_dis = self.vv.dis[i]
index = i
# 标记已访问
self.vv.visited[index] = True
return index
def update(self, index):
"""
更新最短距离
:return:
"""
length = 0
for i in range(len(self.edges[index])):
# 起始节点 到index的距离 相当于起始节点可能不能直接到达i 节点需要经过index
dis = self.vv.dis[index]
# 顶点 index 到 顶点 i的距离
di = self.edges[index][i]
# length 含义是 : 出发顶点到index顶点的距离 + 从index顶点到j顶点的距离的和
length = dis + di
if not self.vv.visited[i] and 0 < length < self.vv.dis[i]:
# 更新出发顶点到i的最短距离 和前驱节点
self.vv.dis[i] = length
self.vv.pre[i] = index
def show(self):
print(self.vv.visited)
print(self.vv.pre)
count = 0
for i in self.vv.dis:
if i != float('inf'):
print(self.vertexes[count] + "(%d)" % i)
else:
print(self.vertexes[count] + '(N)')
count += 1
if __name__ == '__main__':
vertex = ['A', 'B', 'C', 'D', 'E', 'F', 'G']
N = float('inf')
mertix = [
[0, 5, 7, N, N, N, 2],
[5, 0, N, 9, N, N, 3],
[7, N, 0, N, 8, N, N],
[N, 9, N, 0, N, 4, N],
[N, N, 8, N, 0, 5, 4],
[N, N, N, 4, 5, 0, 6],
[2, 3, N, N, 4, 6, 0],
]
dijsktra_graph = DijsktraGraph(vertex, mertix)
dijsktra_graph.dijsktra(6)
dijsktra_graph.show()import heapq
'''
小顶堆,直接 heapq.heappush(dui,value) 循环push
大顶堆 heapq.heappush(dui,-value) 循环push
大顶堆 -heapq.heappop(dui)
'''
# heapq 也可以接受元组排序,默认安照元组的第一项排序
a = [(1,2),(4,1),(3,5)]
>>> heapq.heapify(a)
>>> print(a)
[(1, 2), (4, 1), (3, 5)]
>>> heapq.heappop(a)
(1, 2)
>>> heapq.heappop(a)
(3, 5)
>>> heapq.heappop(a)
(4, 1)int binarySearch(int[] nums, int target) {
int left = 0, right = ...;
while(...) {
int mid = left + (right - left) / 2;
if (nums[mid] == target) {
...
} else if (nums[mid] < target) {
left = ...
} else if (nums[mid] > target) {
right = ...
}
}
return ...;
}
# 搜索一个数
int binarySearch(int[] nums, int target) {
int left = 0;
int right = nums.length - 1; // 注意
while(left <= right) {
int mid = left + (right - left) / 2;
if(nums[mid] == target)
return mid;
else if (nums[mid] < target)
left = mid + 1; // 注意
else if (nums[mid] > target)
right = mid - 1; // 注意
}
return -1;
}
# 寻找左侧边界
int left_bound(int[] nums, int target) {
int left = 0, right = nums.length - 1;
// 搜索区间为 [left, right]
while (left <= right) {
int mid = left + (right - left) / 2;
if (nums[mid] < target) {
// 搜索区间变为 [mid+1, right]
left = mid + 1;
} else if (nums[mid] > target) {
// 搜索区间变为 [left, mid-1]
right = mid - 1;
} else if (nums[mid] == target) {
// 收缩右侧边界
right = mid - 1;
}
}
// 检查出界情况
if (left >= nums.length || nums[left] != target) {
return -1;
}
return left;
}
# 寻找右侧边界
int right_bound(int[] nums, int target) {
if (nums.length == 0) return -1;
int left = 0, right = nums.length;
while (left < right) {
int mid = left + (right - left) / 2;
if (nums[mid] == target) {
left = mid + 1; // 注意
} else if (nums[mid] < target) {
left = mid + 1;
} else if (nums[mid] > target) {
right = mid;
}
}
return left - 1; // 注意
}class Solution:
def canFinish(self, numCourses: int, prerequisites: List[List[int]]) -> bool:
# 判断是否有环,有环无法完成
def build_graph(prerequisites,numCourses):
graph = [[] for i in range(numCourses)]
for p in prerequisites:
# 注意这里是反向的
froms,to = p[1],p[0]
graph[froms].append(to)
return graph
graph = build_graph(prerequisites,numCourses)
has_cycle = False
visited = [0]*numCourses
on_path = [0]*numCourses
def traverse(node_index):
# 遍历过这个点return 或者 找到环 return
nonlocal has_cycle
if on_path[node_index]==1:
has_cycle=True
if visited[node_index]==1 or has_cycle:
return
visited[node_index] = 1
on_path[node_index] = 1
for n in graph[node_index]:
traverse(n)
on_path[node_index] = 0
# 不要忘了 遍历全部节点,要循环所有节点检查
for i in range(len(graph)):
traverse(i)
return not has_cycle// 主函数
public boolean canFinish(int numCourses, int[][] prerequisites) {
// 建图,有向边代表「被依赖」关系
List<Integer>[] graph = buildGraph(numCourses, prerequisites);
// 构建入度数组
int[] indegree = new int[numCourses];
for (int[] edge : prerequisites) {
int from = edge[1], to = edge[0];
// 节点 to 的入度加一
indegree[to]++;
}
// 根据入度初始化队列中的节点
Queue<Integer> q = new LinkedList<>();
for (int i = 0; i < numCourses; i++) {
if (indegree[i] == 0) {
// 节点 i 没有入度,即没有依赖的节点
// 可以作为拓扑排序的起点,加入队列
q.offer(i);
}
}
// 记录遍历的节点个数
int count = 0;
// 开始执行 BFS 循环
while (!q.isEmpty()) {
// 弹出节点 cur,并将它指向的节点的入度减一
int cur = q.poll();
count++;
for (int next : graph[cur]) {
indegree[next]--;
if (indegree[next] == 0) {
// 如果入度变为 0,说明 next 依赖的节点都已被遍历
q.offer(next);
}
}
}
// 如果所有节点都被遍历过,说明不成环
return count == numCourses;
}
// 建图函数
List<Integer>[] buildGraph(int n, int[][] edges) {
// 见前文
}// 主函数
public int[] findOrder(int numCourses, int[][] prerequisites) {
// 建图,和环检测算法相同
List<Integer>[] graph = buildGraph(numCourses, prerequisites);
// 计算入度,和环检测算法相同
int[] indegree = new int[numCourses];
for (int[] edge : prerequisites) {
int from = edge[1], to = edge[0];
indegree[to]++;
}
// 根据入度初始化队列中的节点,和环检测算法相同
Queue<Integer> q = new LinkedList<>();
for (int i = 0; i < numCourses; i++) {
if (indegree[i] == 0) {
q.offer(i);
}
}
// 记录拓扑排序结果
int[] res = new int[numCourses];
// 记录遍历节点的顺序(索引)
int count = 0;
// 开始执行 BFS 算法
while (!q.isEmpty()) {
int cur = q.poll();
// 弹出节点的顺序即为拓扑排序结果
res[count] = cur;
count++;
for (int next : graph[cur]) {
indegree[next]--;
if (indegree[next] == 0) {
q.offer(next);
}
}
}
if (count != numCourses) {
// 存在环,拓扑排序不存在
return new int[]{};
}
return res;
}
// 建图函数
List<Integer>[] buildGraph(int n, int[][] edges) {
// 见前文
}class Solution:
def findOrder(self, numCourses: int, prerequisites: List[List[int]]) -> List[int]:
# 判断是否有环,有环无法完成
def build_graph(prerequisites,numCourses):
graph = [[] for i in range(numCourses)]
for p in prerequisites:
froms,to = p[1],p[0]
graph[froms].append(to)
return graph
# global has_cycle
graph = build_graph(prerequisites,numCourses)
has_cycle = False
visited = [0]*numCourses
on_path = [0]*numCourses
postorder = []
def traverse(node_index):
# 遍历过这个点return 或者 找到环 return
nonlocal has_cycle
if on_path[node_index]==1:
has_cycle=True
if visited[node_index]==1 or has_cycle:
return
visited[node_index] = 1
on_path[node_index] = 1
for n in graph[node_index]:
traverse(n)
postorder.append(node_index)
on_path[node_index] = 0
# 不要忘了 遍历全部节点,要循环所有节点检查
for i in range(len(graph)):
traverse(i)
if has_cycle:
return []
else:
return postorder[::-1]def dailyTemperatures(self, temperatures: List[int]) -> List[int]:
stack = []
res = [0]*len(temperatures)
# 从后往前入栈
for i in range(len(temperatures)-1,-1,-1):
while stack and temperatures[stack[-1]]<=temperatures[i]:
stack.pop()
if stack:
# 这里要求是距离就 i 入栈,结果计算和i的距离,如果是数值,就直接数值入栈
res[i] = stack[-1]-i
else:
res[i] = 0
stack.append(i)
return res def reverseList(self, head: ListNode) -> ListNode:
prev = None
curr = head
while curr:
nextTemp = curr.next
curr.next = prev
prev = curr
curr = nextTemp
return prevlist[::-1]
reversed(list) def middleNode(self, head: ListNode) -> ListNode:
slow = fast = head
while fast.next and fast.next.next:
slow = slow.next
fast = fast.next.next
return slow- 1 二进制理解为 000.....1
- 因此 任何数 和 1做 运算就是与这个数字的最后一位做运算,如 3是0011,那么3&1 就是1
- 如果一个数&1,意思就是取最后一位的数字(0或1),&0 则相反。
- 右移:>> , 如 3>>2 就变成0,(3>>2)&1 就是0
- ans |= (1 << i) ,按位或,就相当于做加法
- python中 int 是有符号整数,因此第32位,也就是左数第一位代表们
$-2^31$ - a 和 -a 做与得到的就是,a右边第一个为1的那一位的数,如 10&-10 = 2,0010
- python 转二进制函数 bin(num), bin(10)
- 左移 a<<b, 把a左移b位,a>>b, 把a右移b位
split 函数 如果写 s.split(),无参数, 会去掉字符串中 所有空格,把剩下的字符串留下来
而 split(' '),会去掉' ', 这样在 得到的list 中可能会出现空串,因为 空格空格的中间是空- 注意第二个while,left 缩短的条件,要想清楚。
# graph 为 邻接表法,path 在一些图题里面,也可以用一个数组onpath 代替,onpath代表现在所走的路径,visited代表全部访问过的节点,可以理解为onpath是贪食蛇的身体,visited 是他经过的地方
class Solution:
def allPathsSourceTarget(self, graph: List[List[int]]) -> List[List[int]]:
#类似回溯
res = []
n = len(graph)
def traverse(path,node_index):
path.append(node_index)
if node_index == n-1:
res.append(path[:])
for i in graph[node_index]:
traverse(path,i)
path.pop()
traverse([],0)
return resclass Solution:
def canFinish(self, numCourses: int, prerequisites: List[List[int]]) -> bool:
# 判断是否有环,有环无法完成
def build_graph(prerequisites,numCourses):
graph = [[] for i in range(numCourses)]
for p in prerequisites:
# 注意这里是反向的
froms,to = p[1],p[0]
graph[froms].append(to)
return graph
graph = build_graph(prerequisites,numCourses)
has_cycle = False
visited = [0]*numCourses
on_path = [0]*numCourses
def traverse(node_index):
# 遍历过这个点return 或者 找到环 return
nonlocal has_cycle
if on_path[node_index]==1:
has_cycle=True
if visited[node_index]==1 or has_cycle:
return
visited[node_index] = 1
on_path[node_index] = 1
for n in graph[node_index]:
traverse(n)
on_path[node_index] = 0
# 不要忘了 遍历全部节点,要循环所有节点检查
for i in range(len(graph)):
traverse(i)
return not has_cycleclass Solution:
def findOrder(self, numCourses: int, prerequisites: List[List[int]]) -> List[int]:
# 判断是否有环,有环无法完成
def build_graph(prerequisites,numCourses):
graph = [[] for i in range(numCourses)]
for p in prerequisites:
froms,to = p[1],p[0]
graph[froms].append(to)
return graph
# global has_cycle
graph = build_graph(prerequisites,numCourses)
has_cycle = False
visited = [0]*numCourses
on_path = [0]*numCourses
postorder = []
def traverse(node_index):
# 遍历过这个点return 或者 找到环 return
nonlocal has_cycle
if on_path[node_index]==1:
has_cycle=True
if visited[node_index]==1 or has_cycle:
return
visited[node_index] = 1
on_path[node_index] = 1
for n in graph[node_index]:
traverse(n)
postorder.append(node_index)
on_path[node_index] = 0
# 不要忘了 遍历全部节点,要循环所有节点检查
for i in range(len(graph)):
traverse(i)
if has_cycle:
return []
else:
return postorder[::-1]#给定一个整数数组 temperatures ,表示每天的温度,返回一个数组 answer ,其中 answer[i] 是指在第 i 天之后,才会有更高的温度。如果气温在这之后都不会升高,请在该位置用 0 来代替。from leetcode.
class Solution:
def dailyTemperatures(self, temperatures: List[int]) -> List[int]:
stack = []
res = [0]*len(temperatures)
# 从后往前入栈
for i in range(len(temperatures)-1,-1,-1):
while stack and temperatures[stack[-1]]<=temperatures[i]:
stack.pop()
if stack:
res[i] = stack[-1]-i
else:
res[i] = 0
stack.append(i)
return res# 指针法
import heapq
class Solution:
def mergeKLists(self, lists: List[Optional[ListNode]]) -> Optional[ListNode]:
if not lists:
return None
dumy = node = ListNode()
# for index,q in enumerate(qs):
# temp = lists[index]
# while temp:
length = len(lists)
flags = [1]*length
while True:
min_val = 100000
min_index = -1
for index,i in enumerate(lists):
if i :
if min_val > i.val:
min_val = i.val
min_index = index
else:
flags[index]=0
if sum(flags)==0:
break
node.next = ListNode(min_val)
node = node.next
lists[min_index] = lists[min_index].next
return dumy.next
#优先队列
ListNode mergeKLists(ListNode[] lists) {
if (lists.length == 0) return null;
// 虚拟头结点
ListNode dummy = new ListNode(-1);
ListNode p = dummy;
// 优先级队列,最小堆
PriorityQueue<ListNode> pq = new PriorityQueue<>(
lists.length, (a, b)->(a.val - b.val));
// 将 k 个链表的头结点加入最小堆
for (ListNode head : lists) {
if (head != null)
pq.add(head);
}
while (!pq.isEmpty()) {
// 获取最小节点,接到结果链表中
ListNode node = pq.poll();
p.next = node;
if (node.next != null) {
pq.add(node.next);
}
// p 指针不断前进
p = p.next;
}
return dummy.next;
}class Solution(object):
def levelOrder(self, root):
"""
:type root: TreeNode
:rtype: List[List[int]]
"""
if not root:
return []
res = []
queue = [root]
while queue:
# 获取当前队列的长度,这个长度相当于 当前这一层的节点个数
size = len(queue)
tmp = []
# 将队列中的元素都拿出来(也就是获取这一层的节点),放到临时list中
# 如果节点的左/右子树不为空,也放入队列中
for _ in xrange(size):
r = queue.pop(0)
tmp.append(r.val)
if r.left:
queue.append(r.left)
if r.right:
queue.append(r.right)
# 将临时list加入最终返回结果中
res.append(tmp)
return res
class Solution:
def change(self, amount: int, coins: List[int]) -> int:
# 回溯不给过, 用 动规
# dp[i][j] amount=j,coins 为 coins[:i] 时 有几种选法,注意 ij 的顺序设计
# 转移 这coin 是放还是不放, dp[i][j] 的 结果是 放 和 不放的总和, 这个状态转移要想好
dp = []
for i in range(len(coins)+1):
temp = [0]*(amount+1)
temp[0] = 1
dp.append(temp)
for i in range(1,len(coins)+1):
for j in range(1,amount+1):
if j-coins[i-1]>=0:
#注意这里是 >=
dp[i][j] = dp[i-1][j]+dp[i][j-coins[i-1]]
else:
dp[i][j] = dp[i-1][j]
return dp[len(coins)][amount]class Solution:
def longestPalindromeSubseq(self, s: str) -> int:
n = len(s)
#dp 表示 从 i 到 j 的子串的最长回文子序列
# i从大到小,保证i,i+1都有值,j从小到大,保证j j-1 都有值。
dp = [[0] * n for _ in range(n)]
for i in range(n-1,-1,-1):
dp[i][i] = 1
for j in range(i+1,n):
if s[i] == s[j]:
dp[i][j] = dp[i+1][j-1]+2
continue
dp[i][j] = max(dp[i+1][j],dp[i][j-1])
return dp[0][n-1]class Solution(object):
def maxSubArray(self, nums):
"""
:type nums: List[int]
:rtype: int
"""
# dp代表 以list[k] 结尾的最大子数组和。
dp = [-10001]*len(nums)
dp[0] = nums[0]
for index,num in enumerate(nums):
if index==0:
continue
dp[index] = max(num,num+dp[index-1])
return max(dp)# python3
'''解题思路:
由前面连续子数组最大和可知dp[i] = max(dp[i-1]*nums[i],nums[i]),由于本体是乘积最大子数组,且数组元素中存在负数情形,因此遍历数组时若当前元素为负数则最大值与最小值交换,然后再分别求最大与最小值,最后与一个结果进行比较每次取最大的值
'''
class Solution:
def maxProduct(self, nums: List[int]) -> int:
nlen = len(nums)
minval,maxval = 1,1
res = -2**32
for i in range(nlen):
if nums[i] < 0:
minval,maxval = maxval,minval
maxval = max(maxval*nums[i],nums[i])
minval = min(minval*nums[i],nums[i])
res = max(res,maxval)
return res#给定一个单链表 L 的头节点 head ,单链表 L 表示为:
L0 → L1 → … → Ln - 1 → Ln
请将其重新排列后变为:
L0 → Ln → L1 → Ln - 1 → L2 → Ln - 2 → …
#
class Solution(object):
def reorderList(self, head):
"""
:type head: ListNode
:rtype: None Do not return anything, modify head in-place instead.
"""
fast = slow = head
# print(fast)
# 快慢指针
while fast and fast.next:
fast = fast.next.next
slow = slow.next
headres = head
pre = None
curr = slow
# 翻转
while curr:
next = curr.next
curr.next = pre
pre = curr
curr = next
head_node = head.next
end_node = pre
while head_node is not end_node and head_node and end_node:
headres.next = end_node
end_node = end_node.next
headres = headres.next
headres.next = head_node
head_node = head_node.next
headres = headres.next输入两棵二叉树A和B,判断B是不是A的子结构。(约定空树不是任意一个树的子结构)
B是A的子结构, 即 A中有出现和B相同的结构和节点值。
class Solution(object):
def isSubStructure(self, A, B):
"""
:type A: TreeNode
:type B: TreeNode
:rtype: bool
"""
# 注意,此题有重复节点,因此要全找出来。
if B==None:
return False
target_val = B.val
all_find_node=[]
def find(target_val,tree_node):
if tree_node==None:
return None
if tree_node.val == target_val:
all_find_node.append(tree_node)
find(target_val,tree_node.left)
find(target_val,tree_node.right)
def compare(T1,T2):
# print(T1,'++++',T2,'____')
if T1==None and T2!=None:
return False
if T2==None and T1!=None:
return True
if T1==None and T2==None:
return True
if T1.val != T2.val:
return False
return compare(T1.left,T2.left) and compare(T1.right,T2.right)
find(target_val,A)
for root in all_find_node:
if compare(root,B):
return True
return Falseclass Solution:
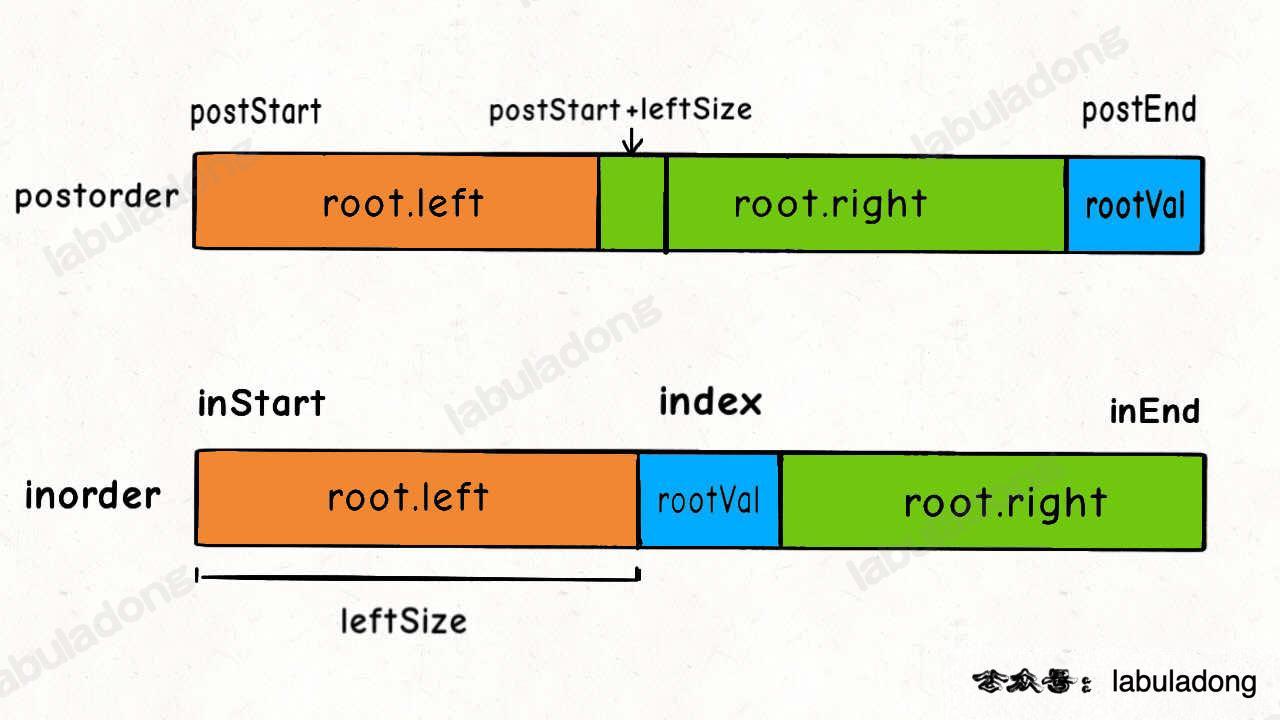
def buildTree(self, preorder: List[int], inorder: List[int]) -> TreeNode:
# root = temp = TreeNode(preorder[0])
def build(preorder,pre_start,pre_end,inorder,in_start,in_end):
if pre_start>pre_end:
return None
mid_node = TreeNode(preorder[pre_start])
mid_index = inorder.index(mid_node.val)
left_len = mid_index - in_start
# 在构建二叉树的 时候,不要动原数组,都用index来更新。
mid_node.left = build(preorder,pre_start+1,pre_start+left_len,inorder,in_start,mid_index-1)
mid_node.right = build(preorder,pre_start+left_len+1,pre_end,inorder,mid_index+1,in_end)
return mid_node
return build(preorder,0,len(preorder)-1,inorder,0,len(inorder)-1)class Solution:
def minSubArrayLen(self, target: int, nums: List[int]) -> int:
left = right =0
sum = 0
min_len = 100000
flag = True
while right < len(nums):
sum+=nums[right]
while sum>=target:
flag = False
sum-=nums[left]
min_len = min(min_len,right-left)
# print(min_len,left,right)
left+=1
right+=1
if flag:
return 0
return min_len+1class Solution:
def search(self, nums: List[int], target: int) -> int:
if nums == None:
return -1
left = 0
right = len(nums)-1
while left<=right:
mid = left + (right - left)//2
if nums[mid] == target:
return mid
if nums[mid] >= nums[0]:
# 左侧有序
if target<=nums[mid] and target>=nums[left]:
right = mid-1
else :
left = mid+1
else:
# 右侧有序
if target >= nums[mid] and target <= nums[right]:
left = mid+1
else :
right = mid-1
return -1给定一个整数数组 nums,其中恰好有两个元素只出现一次,其余所有元素均出现两次。 找出只出现一次的那两个元素。你可以按 任意顺序 返回答案。
class Solution(object):
def singleNumber(self, nums):
"""
:type nums: List[int]
:rtype: List[int]
"""
# 通过 异或操作来找到一个位,这个位的异或结果为1,也就说明这个位可以用来区分那两个数字,利用这个数字把原来的数组分为两组,每一组都和0做异或,叠加,最后得到的就是对应的数字。
xor = 0
for num in nums:
xor^=num
bit = xor&(-xor) #可以得到最右边为1的那一位,不知道为什么
res = [0,0]
for num in nums:
if num&bit==0:
# print(num)
res[0]^=num
else:
res[1]^=num
return res# 返回环起始位置,
class Solution(object):
def detectCycle(self, head):
"""
:type head: ListNode
:rtype: bool
"""
slow = fast = head
k=0
flag = False
while fast:
slow = slow.next
k+=1
if fast.next==None:
break
fast = fast.next.next
if slow is fast:
flag = True
break
# k_m = 0
if flag:
while head is not fast:
head=head.next
fast=fast.next
# k_m+=1
return head
else:
return None pow_dict = {}
for i in range(10):
pow_dict[str(i)] = pow(i,2)
def getsum(ss):
sum=0
for i in ss:
sum+=pow_dict[i]
return sum
s = str(n)
while len(s)>1:
n = getsum(s)
s = str(n)
if s=='1' or s=='7':
return True
else:
return Falseclass Solution:
def coinChange(self, coins: List[int], amount: int) -> int:
# 状态 amount
# 选择 硬币的变化
#要用到for 来选择硬币
def dp(coins,amount):
if amount in memo:
return memo[amount]
if amount == 0:
return 0
if amount <0:
return -1
res = 10001
for coin in coins:
num = dp(coins,amount-coin)
if num<0:
continue
res = min(res,num+1)
if res == 10001:
memo[amount] = -1
return -1
else:
memo[amount] = res
return res
memo = {}
return dp(coins,amount)class Solution(object):
def minDepth(self, root):
"""
:type root: TreeNode
:rtype: int
"""
if root is None:
return 0
q = []
depth = 1
q.append(root)
while q is not None:
length=len(q)
for i in range(length):
node = q.pop(0)
if node.left is None and node.right is not None:
q.append(node.right)
elif node.left is not None and node.right is None:
q.append(node.left)
elif node.left is not None and node.right is not None:
q.append(node.left)
q.append(node.right)
else:
return depth
depth+=1class Solution:
def dfs(self,grid,node_x,node_y):
limit_y = len(grid)
limit_x = len(grid[0])
grid[node_x][node_y]=0
for x,y in [(node_x,node_y-1),(node_x,node_y+1),(node_x-1,node_y),(node_x+1,node_y)]:
if x>=0 and x<limit_y and y>=0 and y<limit_x :
# print(x,y)
if grid[x][y]=='1':
self.dfs(grid,x,y)
def numIslands(self, grid: List[List[str]]) -> int:
limit_y = len(grid)
limit_x = len(grid[0])
# print(limit_y,limit_x)
num = 0
for xx in range(limit_x):
for yy in range(limit_y):
# print(type(grid[yy][xx]))
if grid[yy][xx] == '1':
# print('fuck')
num+=1
self.dfs(grid,yy,xx)
return numclass Solution:
def threeSum(self, nums: List[int]) -> List[List[int]]:
nums = sorted(nums)
def twosum(num_list,target):
res=[]
start = 0
end = len(num_list)-1
while start<end:
sum = num_list[start]+num_list[end]
left = num_list[start]
right = num_list[end]
if sum==target:
res.append([num_list[start],num_list[end]])
while start<end and num_list[start]==left:
start+=1
while start<end and num_list[end]==right:
end-=1
elif sum>target:
while start<end and num_list[end]==right:
end-=1
else:
while start<end and num_list[start]==left:
start+=1
return res
index=0
length= len(nums)
final_res = []
while index<length:
temp = None
if index+1<length:
temp = twosum(nums[index+1:],-nums[index])
if temp:
for i in range(len(temp)):
temp[i].append(nums[index])
final_res+=temp
while index+1<length and nums[index] == nums[index+1]:
index+=1
flag=False
# 循环保证 index 和 index+1 不相等,但是还是原来的那个值,要再加一
index+=1
return final_res-
HOOK机制的好处:
- 可以灵活的插入到程序的运行过程中,实现自定义的功能。
-
HOOK 机制,mmlab的代码运行使用了很多Hook的机制,每一个hook中对应了训练过程中要用到的各种操作,如果想自己设计一些流程就自己去实现Hook并且用ruuner 去注册他
-
在Hook的注册过程中,runner会将新的hook加入到 ruuner._ _hooks _ _ 命名的一个list中,在插入过程中根据hook在实例化时候的优先级,来判断这个hook在list中的插入位置,从而也就决定了在调用的时候的调用顺序
-
在ruuner的运行过程中,在需要相关的hook时候,就调用 runner.call_hook('操作的名字fnname'),在call_hook函数中,会遍历 ruuner._ _hooks _ _并且将同名的函数执行一遍。
import sys class HOOK: def before_breakfast(self, runner): print('{}:吃早饭之前晨练30分钟'.format(sys._getframe().f_code.co_name)) def after_breakfast(self, runner): print('{}:吃早饭之前晨练30分钟'.format(sys._getframe().f_code.co_name)) def before_lunch(self, runner): print('{}:吃午饭之前跑上实验'.format(sys._getframe().f_code.co_name)) def after_lunch(self, runner): print('{}:吃完午饭午休30分钟'.format(sys._getframe().f_code.co_name)) def before_dinner(self, runner): print('{}: 没想好做什么'.format(sys._getframe().f_code.co_name)) def after_dinner(self, runner): print('{}: 没想好做什么'.format(sys._getframe().f_code.co_name)) def after_finish_work(self, runner, are_you_busy=False): if are_you_busy: print('{}:今天事贼多,还是加班吧'.format(sys._getframe().f_code.co_name)) else: print('{}:今天没啥事,去锻炼30分钟'.format(sys._getframe().f_code.co_name)) class Runner(object): def __init__(self, ): pass self._hooks = [] def register_hook(self, hook): # 这里不做优先级判断,直接在头部插入HOOK self._hooks.insert(0, hook) #将hook这个类插入到self._hook list中的第0个位置 def call_hook(self, hook_name): for hook in self._hooks: getattr(hook, hook_name)(self) def run(self): print('开始启动我的一天') self.call_hook('before_breakfast') self.call_hook('after_breakfast') self.call_hook('before_lunch') self.call_hook('after_lunch') self.call_hook('before_dinner') self.call_hook('after_dinner') self.call_hook('after_finish_work') print('~~睡觉~~') runner = Runner() hook = HOOK() runner.register_hook(hook) runner.run() # from https://blog.csdn.net/hxxjxw/article/details/115767507
- 先下采样得到多层特征,用深层特征与做上采样,与之前同等大小的底层feature融合,因此金字塔结构可以既包含底层语义又包含高级语义
- 在所有重叠框中,保留置信度最高的
- 结果集合A一开始为空集,框集合为B,每次从B中取置信度最高的框a,放入A,然后去除B中所有和a重叠的框,重复操作。最后A中留下的就是最终的框。
- 目标大小 N x N,抠出来的feature大小 M x M
- 在M x M中画出 N x N的格子,每个格子中有多个数值,在每个格子中选取采样点,如2 x 2=4 个,采样点的位置可能不是格子的坐标位置,用双线性差值,最后得到采样点,对采样点做pooling操作
- yolov1 是选置信度大的
- 大部分是按IOU来选择box
- 怎么选择正负样本
- 怎么处理正负样本
- 怎么算loss
- 金字塔是多个不同层的特征融合成一个size,ssd是不融合,直接用多个size去做预测
- 对于每个GTbox,把他 和IOU最大的 anchor box匹配
- 其他的anchor boxes 和IOU大于0.5 的 GTbox匹配
- 一个GTbox可匹配多个anchor boxes
- 匹配上的 anchor box 是正样本,其他anchor box为负样本
- ssd的正样本计算分类和边界框回归,负样本只计算分类
- 由于单阶段没有 RPN的过程,会有大量的负样本产生,因此单阶段更需要解决正负样本不均衡问题
- YOLO对正负样本用了不同的weight,SSD用了难挖掘的负样本(hard negative mining)并且正负样本比例1:3,Retinanet 使用focal loss
- 困难样本:分类器不容易分对的样本,(loss较大的样本),负样本==真值为背景,但是容易分成前景,而且置信度较高的样本。e.g. GTbox 附近的,IOU不高的框,或者形状或纹理与前景物体类似。
- 在一张自然图像里,正负样本比例大约是1:1000
- 如 Faster Rcnn,Yolov2v3等
- 需要调整很多超参数,长宽比,IOU阈值等
-
有锚框与无锚框区别:
- 一个回归偏移,一个回归位置
-
FCOS
-
每个特征图的一个位置都预测三组数值,物体位置,分类,中心度
-
与传统检测算法对比
- FCOS不用IOU判断正负样本,而是用这个点是否在物体的内部判断,正在方式可以增加正样本的数量
- FCOS的坐标偏移量是用该位置坐标预测偏移量,其他算法是用锚框与实际的位置预测
-
和YOLO的区别,yolo直接回归边界框,不能处理重叠物体
- FCOS有金字塔结构特征图,因此不同size的特征图,可以预测不同的物体。如果相同层有重叠,则会预测较小的
- YOLOv3也有多尺度,待调查。
-
为什么会提出中心度
-
如果每个框内的点,都是正样本,确实可以增加正样本数量,GT框周围会产生很多低质量的预测框,所以每个位置预测一个中心度,中心度可以来判断这个预测框好不好。 $$ cenerness = \sqrt{\frac{min(l,r)}{max(l,r)} \times \frac{min(t,b)}{max(t,b)}} $$
-
l,r,t,b是这个点到框的距离
-
-
Loss
-
分类用focal loss
-
前景边界框回归用IOU loss,IOU loss 不会受预测尺度的影响,无论是大物体还是小物体,如果预测完全正确都是0,完全不正确都是正无穷。
- $$ IOULOSS = -ln(IOU) $$
-
中心度用BCE loss
-
-
FCOS 解决了 单阶段的 样本不均衡(focal loss),以及无锚框算法对于物体重叠问题(金字塔)
-
- 可以根据人眼,24fps人就认为是联系的出发,大于24fps可以理解为实时。
- 在和下采样卷计算量相同的情况下,保持更大的特征图,也就是特征图的分辨率更高
-
TF表示是否被正确分类
-
PN代表原本是正样本负样本
-
根据不同的置信度阈值,某个类别会得到不同 的 PR,P和R为横纵坐标绘制的曲线的面积叫AP,所有类别AP平均值为mAP
-
如何绘制PR曲线:
- 给一个置信度的阈值,比如0.3,如何大于这个置信度的box,按照置信度从大到小排序,假设有K个box,计算[1,k] ,k <= K,区间的recall 和 precision,得到K个点,绘制成曲线,就是PR曲线。
-
因此在检测算法中, $$ precesion = \frac{正确结果总数(TP)}{检测框总数(TP+FP)} ,
recall = \frac{正确结果总数}{GT框总数(TP+FN)} $$
-
在检测算法中,只需要计算 TP和FP,就可以计算precision和recall,recall可以用GT总数和TP计算,和算法无关。
-
检测算法AP 完整过程
- 设置一个confidence阈值,取得前K个 预测Box,(也可以不设置阈值,直接取前K个,没有区别)
- 判断每一个预测 Box 是 TP 还 FP,判断方法: 和GT框匹配的大于IOU阈值(如0.5), 并且置信度最高的那个Box,为TP,其他都是为FP。
- 将K个Box按照置信度排序,计算[1,1],[1,2],[1,k]....[1,K],区间的Recall 和 precision,绘制成PR曲线,计算PR曲线的面积就是AP
- precision 如何计算:
- ([1,k] 区间的 TP个数)/ ([1,k] 区间的检测框总数)
- recall 如何计算:
- ([1,k] 区间的 TP个数)/ (整个区间的GT框总数)
- 注意:recall的分母不会随着 [1,k] 区间发生变化,一直是整个数据集 GTbox的总数
- ([1,k] 区间的 TP个数)/ (整个区间的GT框总数)
- AP描述的是在不同Recall下的precision的表现
- 由于一些pooling操作,使得CNN有一定的旋转不变性
- 卷积+ pooling
-
高通滤波 高频信息通过,低频信息不要,增加锐度
-
低通与高通相反,使图像模糊
import cv2 # 仅用于读取图像矩阵
import matplotlib.pyplot as plt
import numpy as np
gray_level = 256 # 灰度级
def pixel_probability(img):
"""
计算像素值出现概率
:param img:
:return:
"""
assert isinstance(img, np.ndarray)
prob = np.array([np.sum(img == i) for i in range(256)])
r, c = img.shape
prob = prob / (r * c)
return prob
def probability_to_histogram(img, prob):
"""
根据像素概率将原始图像直方图均衡化
:param img:
:param prob:
:return: 直方图均衡化后的图像
"""
prob = np.cumsum(prob) # 累计概率
img_map = [int(i * prob[i]) for i in range(256)] # 像素值映射
# print(img_map)
# 像素值替换
assert isinstance(img, np.ndarray)
r, c = img.shape
for ri in range(r):
for ci in range(c):
img[ri, ci] = img_map[img[ri, ci]]
return img
def plot(y, name):
"""
画直方图,len(y)==gray_level
:param y: 概率值
:param name:
:return:
"""
plt.figure(num=name)
plt.bar([i for i in range(gray_level)], y, width=1)
if __name__ == '__main__':
img = cv2.imread('imgs/wild.jpeg', 0) # 1. 读取灰度图
prob = np.array([np.sum(img == i) for i in range(256)])
r, c = img.shape
# 2. 得到每一个像素出现的概率
prob = prob / (r * c)
plot(prob, "原图直方图")
# 3. 直方图均衡化
prob = np.cumsum(prob) # 3.1 累计概率
img_map = [int(i * prob[i]) for i in range(256)] # 3.2 像素值映射(要记住!)
# 3.3 像素值替换
for ri in range(r):
for ci in range(c):
img[ri, ci] = img_map[img[ri, ci]]
prob = np.array([np.sum(img == i) for i in range(256)])
r, c = img.shape
prob = prob / (r * c)
plot(prob, "直方图均衡化结果")
plt.figure()
plt.imshow(cv2.cvtColor(img, cv2.COLOR_BGR2RGB))
plt.show()# 直方图均衡化
import numpy as np
import cv2 as cv
ori_img = cv.imread("pic.jpg")
arr = ori_img.flatten()
List = [np.sum(arr==i) for i in range(256)]
List = np.array(List)
pr = List / List.sum()
cul=[pr[0]]
for i in range(1, 256):
cul.append(cul[i-1]+pr[i])
new_img = np.array([cul[j]*255 for j in arr])
new_img = new_img.reshape(ori_img.shape)R0.3 G0.59 B0.11
# 手动卷积 (Sobel算子)
import cv2
import matplotlib.pyplot as plt
import numpy as np
img = cv2.imread(r"C:\Users\Jeffin_\Desktop\pic.jpg", 0)
img = cv2.resize(img, (256,256), cv2.INTER_LINEAR)
cv2.imshow('test', img)
def sobel_x(img):
h, w = img.shape
Newimg_X = np.zeros_like(img)
sobel_X = np.array([[-1, 0, 1], [-2, 0, 2], [-1, 0, 1]])
for j in range(w-2):
for i in range(h-2):
Newimg_X[i+1, j+1] = abs(np.sum(img[i:i+3, j:j+3] * sobel_X))
return np.uint8(Newimg_X)
def sobel_y(img):
h, w = img.shape
Newimg_Y = np.zeros_like(img)
sobel_Y = np.array([[-1, -2, -1], [0, 0, 0], [1, 2, 1]])
for j in range(w-2):
for i in range(h-2):
Newimg_Y[i+1, j+1] = abs(np.sum(img[i:i+3, j:j+3] * sobel_Y))
return np.uint8(Newimg_Y)
new_img_x = sobel_x(img)
new_img_y = sobel_y(img)
cv2.imshow('new_img_x', new_img_x)
cv2.imshow('new_img_y', new_img_y)import numpy as np
def nms(det, thres):
# [] x1, y1, x2, y2, score
x1, y1, x2, y2 = det[:, 0], det[:, 1], det[:, 2], det[:, 3]
scores = det[:, 4]
# 计算每个框的面积
areas = (x2 - x1 + 1) * (y2 - y1 + 1)
# 按照分数排序 降序
idx_order = scores.argsort()[::-1]
keep = []
while idx_order.size > 0:
#每次都从置信度最高的开始 current
cur_idx = idx_order[0]
keep.append(cur_idx)
# 用于计算 intersaction, 左下,右上,x1,y1 都是越大,x2,y2 都是越小,因为求的是交集
_x1 = np.maximum(x1[cur_idx], x1[idx_order[1:]])
_y1 = np.maximum(y1[cur_idx], y1[idx_order[1:]])
_x2 = np.minimum(x2[cur_idx], x2[idx_order[1:]])
_y2 = np.minimum(y2[cur_idx], y2[idx_order[1:]])
interaction = np.maximum((_y2 - _y1) * (_x2 - _x1), 0)
iou = interaction / (areas[cur_idx] + areas[idx_order[1:]] - interaction + 1e-6)
_keep = iou <= thres
_keep = np.where(_keep > 0)[0]
idx_order = idx_order[_keep]
return keep-
context.set_context ,设置静态图,动态图模式
-
nn.cell == nn.Module
-
callback 一些工具比如 lossmonitor,timemonitor。
-
model.train() 输入 epoch,dataset,callbacks,datasink
-
optimizer 写到了模型的forward(construct)里面
-
对数据集的操作,如数据增强
dataset.map(operations=trans, input_columns=["image"], python_multiprocessing=use_multiprocessing, num_parallel_workers=num_parallel_workers) # trans 是数据增强的list,input columns 是 对应的处理内容
-
from mindspore.ops import composite as C ;C.GradOperation 求梯度函数
-
optim = nn.Momentum(net.trainable_params(), 0.1, 0.9)
-
model = Model(net, loss_fn=loss, optimizer=optim) #Model 类把 net loss opt都包起来,内部实现,也可以自己实现一个 net,包含这些,然后用Model套起来,之后就可以train model.train(args_opt.epoch_size, dataset, callbacks=callback, dataset_sink_mode=dataset_sink_mode)
n.WithLossCell接口可以将前向网络与损失函数连接起来
-
用来避免过拟合
-
常用的正则方法
-
L1/L2正则化,在loss函数后面直接加正则项,是为了将权重参数限制到一个比较小的范围,防止过拟合。
-
L1正则: $$ Loss = L(w)+\lambda\sum_1^n \left|w_i\right| $$
-
L2 正则: $$ Loss = L(w)+\lambda\sum_1^n w_i^2 $$
-
dropout
-
-
如图假设优化参数有2个,可以画出二维的参数w1 w2的取值范围,绿色的线可以理解为loss项的w1w2绘制的线,黑色线是正则项的取值范围,可以看出L1容易得到一个w为0,另一个不为0的解,也就是稀疏解,而L2容易得到w1w2都是很小的数的解。
-

- from sklearn.svm import svc , svm分类器
- 核函数:SVM 的 kernel 一般有三种, linear, poly(多项式),rbf(高斯)
- 软间隔:
- 模型训练结果收 偏差 bias ,方差 v, 噪声三个因素影响
- 准对于降低偏差,boosting stacking,如
- 针对于降低方差,bagging,stacking 如 随机森林,base learner没那么稳定的时候,它对于下降方差的效果会好。
- 降低噪声,用更好的数据
- bagging: bagging就是训练多个模型,每个模型就是通过在训练数据中通过bootstrap采样训练而来; bootstrap就是每一次用m个样本,随机在训练数据中采样m个样本,且会放回继续采样,bagging的主要效果是能够降低方差,特别是当整个用来做bagging的模型是不稳定的模型的时候效果最佳(随机森林)
- boosting: Boosting是说把n个弱一点的模型组合在一起变成一个比较强的模型,用于降低偏差, 所以boosting要使用弱一点的模型来做,太强的模型会过拟合。Gradient boosting 是boosting的一种,每一次弱的模型是去拟合 在标号上的残差,可以认为是每次去拟合给定损失函数的负梯度方向 。 boosting 每个小模型的标签是前一个模型的结果与gt的残差。
- stacking: 将多个不同的模型组合起来,bagging是多个相同的模型,继承学习
- 梯度消失
- 主要是网络层数过多,导致的每层激活函数都会缩放到一个-1,1的区间,都乘以这个数字,因此会越乘越小
- 使用残差网络,relu激活函数,等都可以改善这个问题
- 梯度爆炸
- 主要由初始化权重参数较大导致,也有可能是除以0。
- 使用参数初始化和梯度裁剪
- 反传过程中,是 loss 对 参数求偏导,乘以-的lr,加上原来的参数,也就是说,如果给loss 加一个权重,如果给一个大权重,最终这个权重相当于乘到了lr上,也就是加大了lr。需要lr大的可以加大的loss权重,需要学的慢一点就加小的权重。
- 前背景二分类+检测框
- 多标签分类和 二分类,用sigmod+bceloss
- 多分类用 softmax + crossentropyloss
- 多分类一般人为分类的目标只有一个,而多标签分类用于分类的目标多个,如在yolov3中将多分类loss 改成了多标签分类loss,考虑到在同一个框中的物体,可能会属于多个类别。
- 在reid 任务中,将一个batch包含P个人,每个人K张图片,P*K = batchsize,然后和P的id相同的为positive ,和 P的id不同为negetive。by the way,这种P * K的sample方式叫做pksampler,也可以有助于reid涨点。
- 表征学习:代表 softmax ,arcface学习一个表示来处理任务。
- 度量学习:代表triplet,学习距离,拉近拉远。
- 训练的时候
- 用每个batch的均值和方差
- 测试的时候
- 用之前所有batch的平均的 均值和方差
- 如果只想冻住batchnorm 不冻住其他参数,则需要 F.batch_norm(training=False), 如果是 nn.Batchnorm2d的话他是module类的 ,也有 training 参数。
- 有的模型会在使用预训练模型的时候,把batchnorm设置为 training=False,也就是冻住了,因为有的时候新训练的模型batchsize小,batchnorm可能会收到不好的影响,如果给预训练模型的batchnorm 冻住,就可以使用预训练模型的均值和方差。这样有助于训练,并且可以提高运算速度。
- batchnorm 里面可以学习的东西是 beta 和 gamma
- affine 参数为True 可学习
- track_running_stats=True表示跟踪整个训练过程中的batch的统计特性,得到方差和均值,而不只是仅仅依赖与当前输入的batch的统计特性。相反的,如果track_running_stats=False那么就只是计算当前输入的batch的统计特性中的均值和方差了
- num_features
- C of N C H W
- [1] https://blog.csdn.net/qq_39777550/article/details/108038677
- 归一化:
- 标准化:
def cal_dx(func,x,eps=1e-8):
d_func = func(x+eps) - func(x)
dx = d_func / eps
return dx
def solve(func,x,lr=0.01,num_iters=10000):
print('init x:', x)
for i in range(num_iters):
dx = cal_dx(func,x)
d_func = func(x)-0
grad_x = d_func*dx
x = x - grad_x*lr
# print('iter{.4d}: x={.4f}'.format(i,x))
return x
def check(func,x,eps=1e-8):
if func(x) < eps:
print('done')
else:
print('failed')
if __name__ == '__main__':
init = 3
func = lambda x: 2*x**2+2*x-12
x = solve(func,init)
print(x)
check(func,x)class MaxPooling2D:
def __init__(self, kernel_size=(2, 2), stride=2):
self.kernel_size = kernel_size
self.w_height = kernel_size[0]
self.w_width = kernel_size[1]
self.stride = stride
self.x = None
self.in_height = None
self.in_width = None
self.out_height = None
self.out_width = None
# 要记录下在当前的滑动窗中最大值的索引,反向求导要用到
self.arg_max = None
def __call__(self, x):
self.x = x
self.in_height = np.shape(x)[0]
self.in_width = np.shape(x)[1]
self.out_height = int((self.in_height - self.w_height) / self.stride) + 1
self.out_width = int((self.in_width - self.w_width) / self.stride) + 1
out = np.zeros((self.out_height, self.out_width))
self.arg_max = np.zeros_like(out, dtype=np.int32)
for i in range(self.out_height):
for j in range(self.out_width):
start_i = i * self.stride
start_j = j * self.stride
end_i = start_i + self.w_height
end_j = start_j + self.w_width
out[i, j] = np.max(x[start_i: end_i, start_j: end_j])
self.arg_max[i, j] = np.argmax(x[start_i: end_i, start_j: end_j])
self.arg_max = self.arg_max
return out
def backward(self, d_loss):
dx = np.zeros_like(self.x)
for i in range(self.out_height):
for j in range(self.out_width):
start_i = i * self.stride
start_j = j * self.stride
end_i = start_i + self.w_height
end_j = start_j + self.w_width
# 将索引展开成二维的
index = np.unravel_index(self.arg_max[i, j], self.kernel_size)
dx[start_i:end_i, start_j:end_j][index] = d_loss[i, j] #
return dxclass AvgPooling2D:
def __init__(self, kernel_size=(2, 2), stride=2):
self.stride = stride
self.kernel_size = kernel_size
self.w_height = kernel_size[0]
self.w_width = kernel_size[1]
def __call__(self, x):
self.x = x
self.in_height = x.shape[0]
self.in_width = x.shape[1]
self.out_height = int((self.in_height - self.w_height) / self.stride) + 1
self.out_width = int((self.in_width - self.w_width) / self.stride) + 1
out = np.zeros((self.out_height, self.out_width))
for i in range(self.out_height):
for j in range(self.out_width):
start_i = i * self.stride
start_j = j * self.stride
end_i = start_i + self.w_height
end_j = start_j + self.w_width
out[i, j] = np.mean(x[start_i: end_i, start_j: end_j])
return out
def backward(self, d_loss):
dx = np.zeros_like(self.x)
for i in range(self.out_height):
for j in range(self.out_width):
start_i = i * self.stride
start_j = j * self.stride
end_i = start_i + self.w_height
end_j = start_j + self.w_width
dx[start_i: end_i, start_j: end_j] = d_loss[i, j] / (self.w_width * self.w_height)
return dx-
测试
np.set_printoptions(precision=4, suppress=True, linewidth=120) x_numpy = np.random.random((1, 1, 6, 9)) x_tensor = torch.tensor(x_numpy, requires_grad=True) max_pool_tensor = torch.nn.AvgPool2d((2, 2), 2) max_pool_numpy = AvgPooling2D((2, 2), stride=2) out_numpy = max_pool_numpy(x_numpy[0, 0]) out_tensor = max_pool_tensor(x_tensor) d_loss_numpy = np.random.random(out_tensor.shape) d_loss_tensor = torch.tensor(d_loss_numpy, requires_grad=True) out_tensor.backward(d_loss_tensor) dx_numpy = max_pool_numpy.backward(d_loss_numpy[0, 0]) dx_tensor = x_tensor.grad # print('input \n', x_numpy) print("out_numpy \n", out_numpy) print("out_tensor \n", out_tensor.data.numpy()) print("dx_numpy \n", dx_numpy) print("dx_tensor \n", dx_tensor.data.numpy())
import numpy as np
def conv_naive(x, out_c, ksize, padding=0, stride=1):
# x = [b, h, w, in_c]
b, in_c, h, w = x.shape
kernel = np.random.rand(ksize, ksize, in_c, out_c)
if padding > 0:
pad_x = np.zeros((b, in_c, h+2*padding, w+2*padding))
pad_x[:,:,padding:-padding,padding:-padding] = x
else:
pad_x = x
out_h = (h+2*padding-ksize)//stride+1
out_w = (w+2*padding-ksize)//stride+1
out = np.zeros((b, out_c, out_h, out_w))
for i in range(out_h):
for j in range(out_w):
roi_x = pad_x[:,:,i*stride:i*stride+ksize,j*stride:j*stride+ksize]
# roi_x = [b, in_c, ksize, ksize, in_c] -> [b, in_c, ksize, ksize, out_c]
# kernel = [ksize, ksize, in_c, out_c]
# conv = [b, ksize, ksize, in_c, out_c] -> [b, 1, 1, out_c]
conv = np.tile(np.expand_dims(roi_x, -1), (1,1,1,1,out_c))* np.transpose(kernel, axes=(2,0,1,3))
out[:,:,i,j] = np.squeeze(np.sum(conv, axis=(1,2,3), keepdims=True), axis=1)
return out
if __name__ == '__main__':
x = np.random.rand(1,3,10,10)
out = conv_naive(x, 15, ksize=3, padding=1, stride=2)
print(out.shape)import torch
from torch import nn
def batch_norm(X, gamma, beta, moving_mean, moving_var, eps, momentum):
# 通过is_grad_enabled来判断当前模式是训练模式还是预测模式
if not torch.is_grad_enabled():
# 如果是在预测模式下,直接使用传入的移动平均所得的均值和方差
X_hat = (X - moving_mean) / torch.sqrt(moving_var + eps)
else:
assert len(X.shape) in (2, 4)
if len(X.shape) == 2:
# 使用全连接层的情况,计算特征维上的均值和方差
mean = X.mean(dim=0)
var = ((X - mean) ** 2).mean(dim=0)
else:
# 使用二维卷积层的情况,计算通道维上(axis=1)的均值和方差。
# 这里我们需要保持X的形状以便后面可以做广播运算
mean = X.mean(dim=(0, 2, 3), keepdim=True)
var = ((X - mean) ** 2).mean(dim=(0, 2, 3), keepdim=True)
# 训练模式下,用当前的均值和方差做标准化
X_hat = (X - mean) / torch.sqrt(var + eps)
# 更新移动平均的均值和方差
moving_mean = momentum * moving_mean + (1.0 - momentum) * mean
moving_var = momentum * moving_var + (1.0 - momentum) * var
Y = gamma * X_hat + beta # 缩放和移位
return Y, moving_mean.data, moving_var.data
class BatchNorm(nn.Module):
# num_features:完全连接层的输出数量或卷积层的输出通道数。
# num_dims:2表示完全连接层,4表示卷积层
def __init__(self, num_features, num_dims):
super().__init__()
if num_dims == 2:
shape = (1, num_features)
else:
shape = (1, num_features, 1, 1)
# 参与求梯度和迭代的拉伸和偏移参数,分别初始化成1和0
self.gamma = nn.Parameter(torch.ones(shape))
self.beta = nn.Parameter(torch.zeros(shape))
# 非模型参数的变量初始化为0和1
self.moving_mean = torch.zeros(shape)
self.moving_var = torch.ones(shape)
def forward(self, X):
# 如果X不在内存上,将moving_mean和moving_var
# 复制到X所在显存上
if self.moving_mean.device != X.device:
self.moving_mean = self.moving_mean.to(X.device)
self.moving_var = self.moving_var.to(X.device)
# 保存更新过的moving_mean和moving_var
Y, self.moving_mean, self.moving_var = batch_norm(
X, self.gamma, self.beta, self.moving_mean,
self.moving_var, eps=1e-5, momentum=0.9)
return Y-
sorted 函数有3个参数可调,cmp , key, reverse
-
cmp 是比较函数 和 cpp中类似,cmp=func,func有两个参数a,b可以自定义比较的操作
-
key 也是传入一个函数func,这个函数的有一个参数,代表比较数组中的一个item,return 比较需要参照的元素即可
-
a = [(123,1),(1212,33),(12,3)] # 按照 第二个数排队 b = sorted(a,key = lambda x:x[1])
-
import itertools for item in itertools.product([1,2,3,4],[100,200]): print(item) ''' (1, 100) (1, 200) (2, 100) (2, 200) (3, 100) (3, 200) (4, 100) (4, 200) '''
-
自带 ord() 函数
a = 'a' print(ord(a)) # 97
- 生成器只能遍历一次
- 可变类型:dict list set,只是改变了变量值,不会新建一个对象,变量引用的对象的地址不会变化
- 不可变 : Number( float int) str tuple, 不允许值发生变化,若改变了变量的值,相当于新建了一个对象,对于相同值的对象,内存中只有一个对象
- python 6 个标准类型:Number String List Tuple Set Dict
- 可变类型不可以哈希,不可变类型可以哈希
- dict 也是哈希,为什么可以存 list 这种可变类型呢,因为dict 哈希的是key 不是value
- 为什么会这样呢?原因就在于create是go的父函数,而go被赋给了一个全局变量,这导致go始终在内存中,而go的存在依赖于create,因此create也始终在内存中,不会在调用结束后,被垃圾回收机制(garbage collection)回收。https://zhuanlan.zhihu.com/p/453787908
- 闭包的作用:读取函数内部的变量和让函数内部的局部变量始终保持在内存中
- with a_class as a
- 在这个过程中需要给 a_class 实现两个方法 _ _enter __和 _ _exit __, 这样在使用with的时候 就会在开始和结束调用这两个函数。
- 顾名思义,就是给函数在他外面装饰一下,这里用到了闭包的**。装饰器分为有参数的装饰器和无参数的装饰器,无参数的装饰器定义是,函数(函数())。有参数的是 函数(函数(函数())),第一层可以输入参数,第二层是 要装饰的func。
- 常见装饰器 @wraps(funca), 它接受一个函数来进行装饰,并加入了复制函数名称、注释文档、参数列表等等的功能。这可以让我们在装饰器里面访问在装饰之前的函数的属性。如 加完 wraps之后,函数的 ._ __name _ __会变成funca的名字
from functools import wraps
def a_new_decorator(a_func):
@wraps(a_func)
def wrapTheFunction():
print("I am doing some boring work before executing a_func()")
a_func()
print("I am doing some boring work after executing a_func()")
return wrapTheFunction
@a_new_decorator
def a_function_requiring_decoration():
"""Hey yo! Decorate me!"""
print("I am the function which needs some decoration to "
"remove my foul smell")
print(a_function_requiring_decoration.__name__)
# Output: a_function_requiring_decoration
# 不加wraps
# Output: wrapTheFunction- python 的进程中的线程不能并行,因为 GIL,每个线程实际上是在伪并行(交替执行),每次只有一个线程拿到GIL可以执行程序。
- 如果想并行 需要并行进程,而不是并行线程。
- torch.utils.data.DataLoader()中,如果设置了sampler参数,那么,shuffle参数的值应该设置为FALSE,这两个参数是互斥的。
- sampler是用来处理dataset里面的数据以一个什么样的或者顺序方式通过dataloader输出, init 函数接收 datasoruce 以及batchsize等参数,DataSource就是处理的整个dataset,在 iter函数中,迭代的返回每个batch的对应样本的index,这个index指的就是在dataset中的index。
- pin_memory : 锁页内存,可以从磁盘读取不重叠的数据。
- torch的dataset中的get item 函数的 参数 index,是由 sampler的iter 函数迭代产生的
- 数据并行与模型并行
-
在Reid 项目中,要实现一个将不同数据集分开的计算loss的操作,这个操作怎么实现呢?比如,我有a张图片和a对应的生产图片,想让两种图片都参与训练,并且最终计算loss分开计算。
-
主要是两个问题:1是数据怎么保证是n倍数据量,并且每个batch中都有生产图和原图。2是有了这些图把结果分开计算loss。
-
实现一个可循环生产数据的dataloader
-
class IterLoader: """ Wrapper for repeating dataloaders """ def __init__(self, loader, length=None): self.loader = loader self.length = length self.iter = None def __len__(self): if self.length is not None: return self.length return len(self.loader) # dont change self.loader ,just change self.iter def new_epoch(self, epoch): self.loader.sampler.set_epoch(epoch) self.iter = iter(self.loader) # 不迭代loader ,只迭代 iter,如果iter迭代完了一个轮,就重新用loader给他赋值,又可以重新迭代了 def next(self): try: return next(self.iter) except Exception: self.iter = iter(self.loader) return next(self.iter) # from github-openunreid
-
-
每个epoch 设置一个 iter次数,这个次数*batchsize 是实际数据集大小
-
当一个index的图片来了之后,用一个随机概率处理成原图还是处理成生成图,这样就保证了每个batch里都有原图和生成图
-
在计算loss 时候怎么分开呢,在dataset生成的时候,每一个数据是传回来的字典,字典中存入 flag关键字,用01表示原图和生成图,训练过程中得到一个batch的图片,通过flag得到两种图片的索引信息,利用索引信息将图片和gt标签分成两组,将分好的两组图片在拼合成一个batch,将分好的gt label 也拼合成一个batch,并返回两种数组拼合位置的index。最终根据index就可以重新找到拼合位置与gt计算loss