CuSync is a framework to synchronize tile-based CUDA kernels in a fine-grained manner. With CuSync, a programmer can write policies to synchronize dependent tiles, i.e. thread blocks, of a chain of producer and consumer kernels. Synchronizing thread blocks instead of kernels allows concurrent execution of independent thread blocks, thereby, improving the utilization during the last thread block waves on the GPU. More details are available at https://arxiv.org/abs/2305.13450.
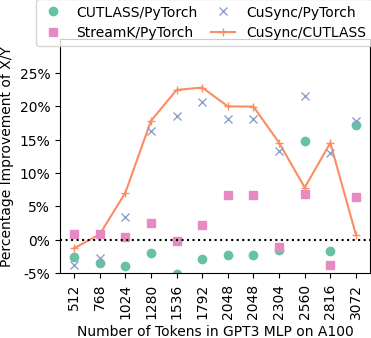
The graphs below shows percentage improvement over GPT3 and LLAMA MLPs using optimized NVIDIA CUTLASS GeMMs on NVIDIA Tesla A100 and NVIDIA Tesla V100 GPUs for 8 way model parallelism GPT3 175B (H=12288 FP16) and LLAMA 65.2B (H=8192 FP16). NVIDIA CUTLASS StreamK is another method to optimize the utilization during the last thread block wave. PyTorch in the below experiments only performs GeMM and not the pointwise computations like GeLU, while CUTLASS implementations fuse these computations with the first GeMM.



Clone the repo and its submodules using
git clone --recurse-submodules https://github.com/parasailteam/cusync.git
If already cloned and want to clone submodules, use
git submodule update --init --recursive
An example of synchronizing two dependent GeMMs is provided in the src/example/. Moreover, there are small tests in tests/ that can be used as examples.
The repo also provides CUTLASS GeMM structs augmented with CuSync structures in src/include/cusync-cutlass/.
The MLP code in src/ml-bench/transformer provides a good way to use CUTLASS cusync.
Run tests using make tests
Instructions are in src/ml-bench/README.md.