In this project, I implemented an ETL (Extract, Transform, Load) pipeline using Python, Pandas, and PostgreSQL. The goal was to import data from an Excel file, transform it to CSV files, and load the CSV files into a PostgreSQL database.
- Created Category and Subcategory DataFrames
- Imported data from crowdfunding.xlsx using
pd.read_excel. - Created a category DataFrame with "category_id" and "category" columns using str.split and list comprehension.
- Created a subcategory DataFrame with "subcategory_id" and "subcategory" columns using str.split and list comprehension.
- Imported data from crowdfunding.xlsx using

-
Created the Campaign DataFrame
- Renamed and dropped unnecessary columns.
- Changed data types (e.g., string to float, datetime).
- Performed a SQL left join on category and subcategory tables to create a merged dataframe.
-
Created the Contacts DataFrame
- Transformed data from contacts.xlsx into a contacts dataframe using Python dictionary methods.
- Split the "name" column into first and last names.
- Cleaned and exported the DataFrame as contacts.csv.
-
Created the Crowdfunding Database
- Designed the database schema based on the ERD generated using Quick DBD.
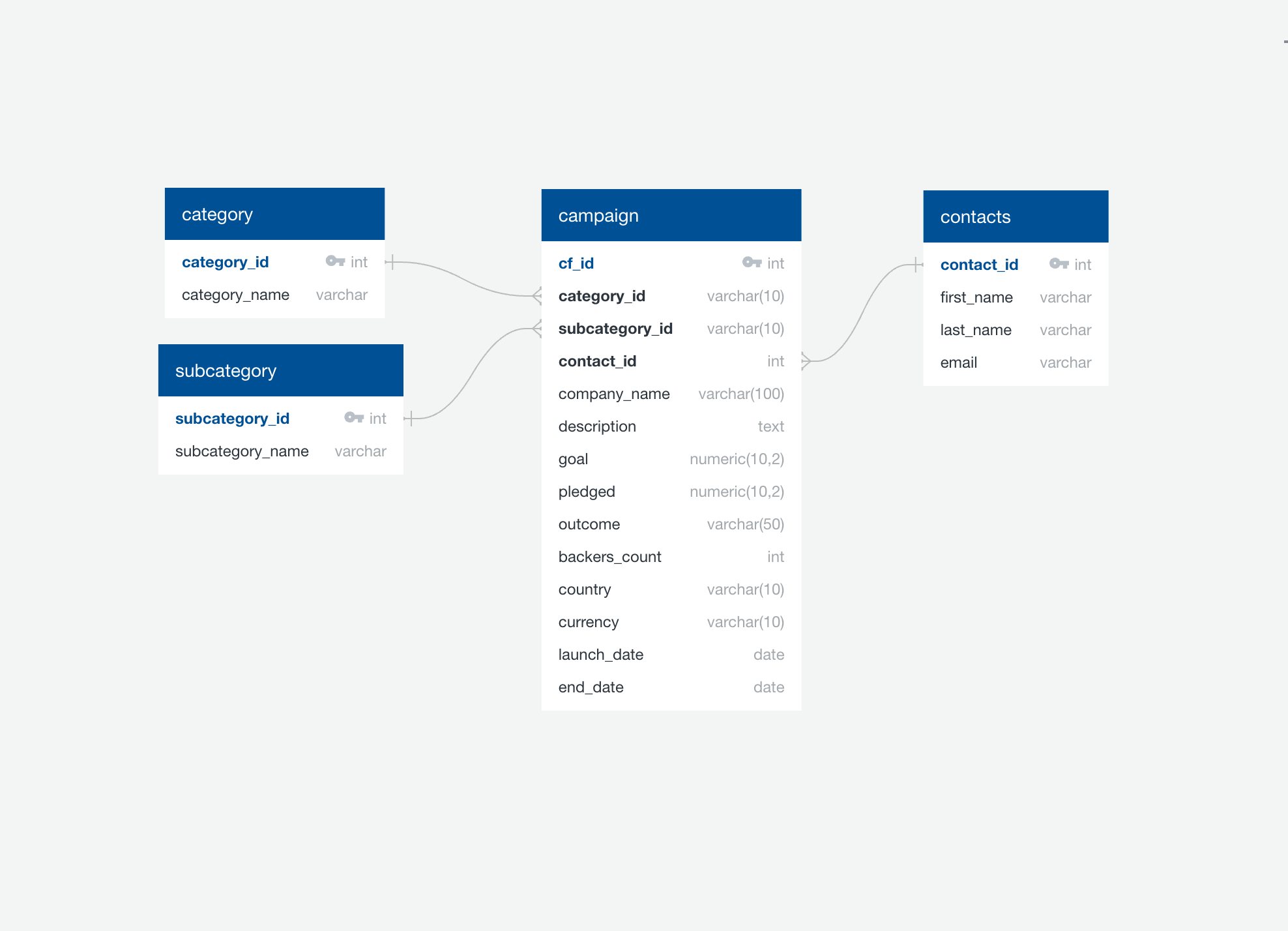
- Created tables with appropriate data types, primary keys, and foreign keys.
- Imported data from CSV files into the PostgreSQL database.
- Verified data integrity by running SELECT statements.


Subcategory Table

Contacts Table

Campaign Table
