测试环境:python3.7
项目简介:
基于selenium的各大电商(淘宝、京东、拼多多等)平台商品爬取。
目前已经完成:
淘宝/京东商品爬取
接下来开发:
1.拼多多等各大电商平台。
2.对比、分析同类商品。
3.敬请期待
安装:
1. pip install -r requirements
2. 修改webdriver,具体请查看这边文章:https://www.jianshu.com/p/368be2cc6ca1,感谢大佬的分享。
3. 或者获取本目录下已经修改好的webdriver 版本V70.0.3809.100(64 位)
特点:
支持设置爬取速度
支持设置爬取页数
支持爬取自定义页数
支持滑块认证
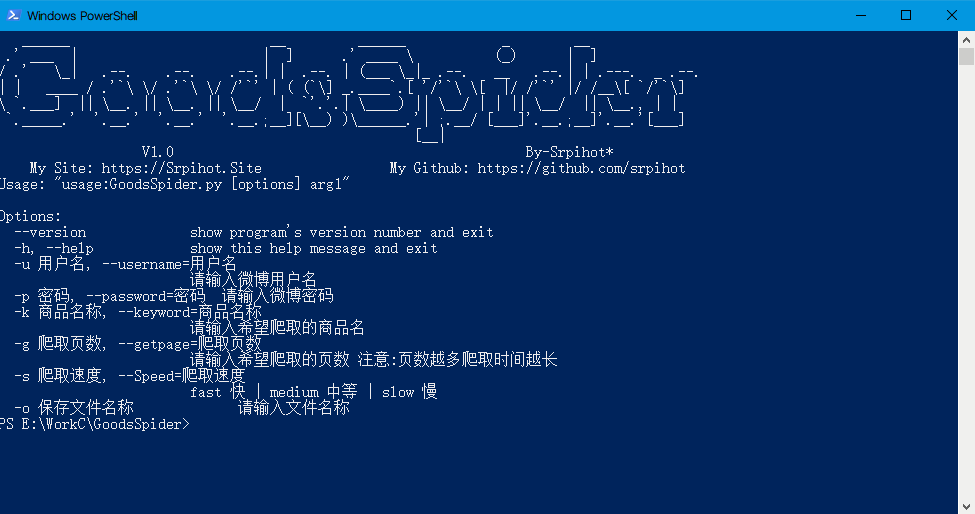
用法:
Usage: "usage:GoodsSpider.py [options] arg1"
Options:
--version show program's version number and exit
-h, --help show this help message and exit
-u 用户名, --username=用户名
请输入微博用户名
-p 密码, --password=密码 请输入微博密码
-k 商品名称, --keyword=商品名称
请输入希望爬取的商品名
-g 爬取页数, --getpage=爬取页数
请输入希望爬取的页数 注意:页数越多爬取时间越长
-s 爬取速度, --Speed=爬取速度
fast 快 | medium 中等 | slow 慢
-o 保存文件名称 请输入文件名称
--site=站点名称 请输入想要爬取的站点 | taobao 淘宝 | jingdong 京东
-q 爬取的商品数量, --quantity=爬取的商品数量 请输入想要爬取的商品数量
--page=具体某一页 请输入想要爬取的具体一页
--attr=生成文件格式 请输入生成的文件格式 | csv/xlsx
ex: python ./GoodsSpider.py -u username -p password -k Python --site=taobao
python ./GoodsSpider.py -u username -p password -k java书籍 --page=4 --attr=xlsx
python ./GoodsSpider.py -k python书籍 --site=jingdong
更新:
2020-3-27 V1.0 完成淘宝商品爬取
2020-3-30 V1.1 修改部分bug
滑块认证方案解决
爬取相比以前效率up+
添加爬取具体某一页功能
添加生成文件格式功能支持csv与xlsx
2020-03-31 V1.2 完成京东商品爬取
修改部分bug
添加可设置爬取商品的数量
优化部分代码 支持不同平台
与我联系:
QQ:619443458 备注:GoodsSpider
注意事项:
淘宝爬取需要登陆账户,因为开发方便所以需要提前绑定淘宝账户与微博。
--site 默认淘宝 必须跟用户名与密码 京东随便
感谢以下大佬们的打赏:
| 赞助名单 | 赞助费用 | 赞助方式 |
|---|---|---|
| sh****0 | ¥6.66 | 微信红包 |
| P*k | ¥66.6 | 微信红包 |
| 爱上你的笑容 | ¥18.88 | QQ红包 |