Upper body image synthesis from skeleton(Keypoints). Pose2Img module in the ICCV-2021 paper "Speech Drives Templates: Co-Speech Gesture Synthesis with Learned Templates". [arxiv / github]
This is a modified implementation of Synthesizing Images of Humans in Unseen Poses.
To install dependencies, run
pip install -r requirements.txtTo run this module, you need two NVIDIA gpus with at least 11 GB respectively. Our code is tested on Ubuntu 18.04LTS with Python3.6.
- We provide the dataset and pretrained models of Oliver at here.
- According to
$ROOT/configs/yaml/Oliver.yaml:
- Unzip and put the data to
$ROOT/data/Oliver - Put the pretrained model to
$ROOT/ckpt/Oliver/ckpt_final.pth
- Train Script:
python main.py \
--name Oliver \
--config_path configs/yaml/Oliver.yaml \
--batch_size 1 \- Run Tensorboard for training visualization.
tensorboard --logdir ./log --port={$Port} --bind_allGenerate a realistic video for Oliver from {keypoints}.npz.
python inference.py \
--cfg_path cfg/yaml/Oliver.yaml \
--name demo \
--npz_path target_pose/Oliver/varying_tmplt.npz \
--wav_path target_pose/Oliver/varying_tmplt.mp4- In the result directory, you can find
jpgfiles which correspond to the npz.
-
For your own dataset, you need to modify custom config.yaml.
-
Prepare the keypoints using OpenPose.
-
The raw keypoints for each frame is of shape (3, 137) which is composed of
[pose(3,25), face(3,70), left_hand(3,21),right_hand(3,21)]The definition is as follows:
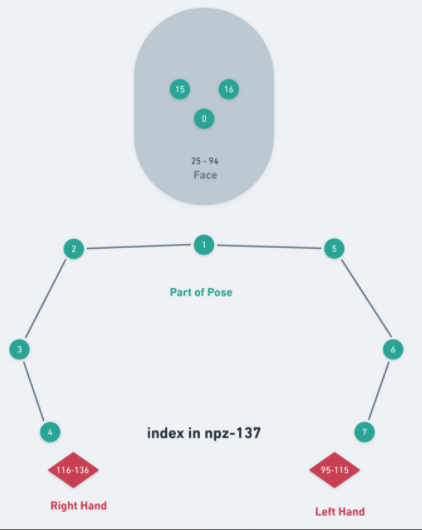

If you find this code useful for your research, please use the following BibTeX entry.
@inproceedings{qian2021speech,
title={Speech Drives Templates: Co-Speech Gesture Synthesis with Learned Templates},
author={Qian, Shenhan and Tu, Zhi and Zhi, YiHao and Liu, Wen and Gao, Shenghua},
journal={International Conference on Computer Vision (ICCV)},
year={2021}
}