公众号:超级王登科
文章链接:https://greatdk.com/1513.html
为了写一篇关于疾病的数据分析,我爬取了150万疾病问答数据,并使用python做了数据分析,在这里记录整个过程,并给出代码和数据
爬虫文件为:health.py 和 m.py
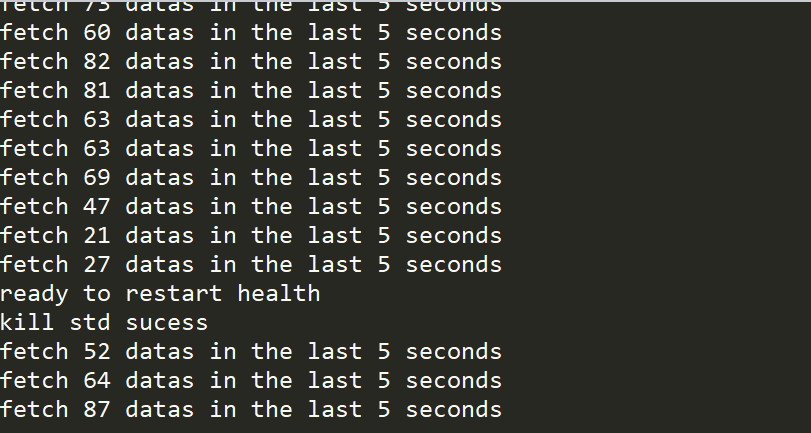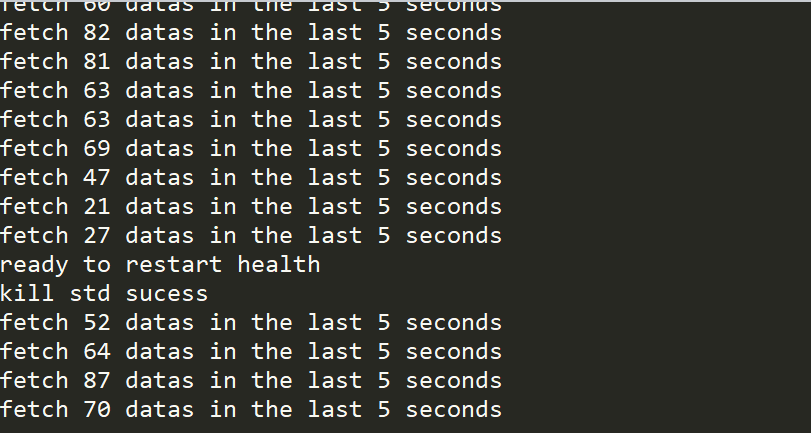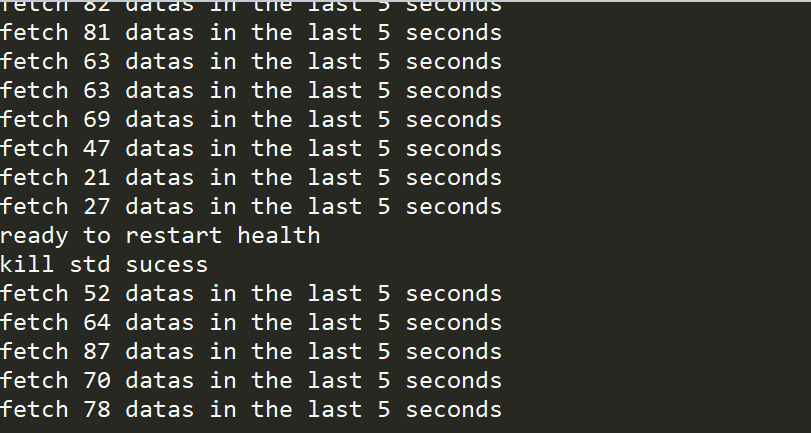
爬虫没什么好说的,基本的看代码就行,不过有一点,加入多线程后,爬虫隔一段时间效率会下降,甚至卡死,研究了半天也没什么好办法,所以又写了一个监控程序,也就是m.py ,它会每隔五秒钟看一下新增的数据,如果低于一定数量,就重启一次爬虫
一开始我习惯性的使用 jieba ,后来我发现我的目的其实只是按照给定字典做词频统计,这个不需要 jieba 就能实现,但既然已经引入了,我就顺便用 jieba 实现了,虽然越到后面发现坑越多,但最后还是实现了,我对比了一下,发现速度也不错。
jieba 词频统计的函数是 jieba.analyse.extract_tags ,所以我一开始就直接用的这个函数
jieba.analyse.set_idf_path('dic_for_idf.txt') #配置自定义字典
tags = jieba.analyse.extract_tags(content, topK=200, withWeight=True)但这样出现的结果很混乱,因为虽然配置了词频的字典,但是分词的时候会产生许多字典之外的词,他们也有权重,而且这些通用词出现频率更高,会完全压制自定义字典里的词,导致做词频统计,统计到的都不是自定义字典中的
所以我接下来加了一行代码,也同时配置了 jieba 分词的字典
jieba.set_dictionary('dic_for_use.txt') #配置自定义字典
jieba.analyse.set_idf_path('dic_for_idf.txt') #配置自定义字典
tags = jieba.analyse.extract_tags(content, topK=200, withWeight=True)但还是不行,网上找了资料,发现 jieba 其实还有新词发现功能,需要关闭隐马尔科夫模型,虽然jieba.cut可以配置隐马尔科夫模型的开关,但我调用的jieba.analyse.extract_tags却并没有这个参数,因此我只能修改 jieba 的源码,手动把 隐马尔科夫模型(HMM)给关闭了,修改的地方在 jieba库目录/posseg/init.py,搜索HMM就能找到许多,都改成False即可
为了保险起见,我还在词频统计的核心文件中加了一行判断,103行附近
if w not in self.idf_freq:
continue这样一来就可以完全过滤掉自定义字典之外的词
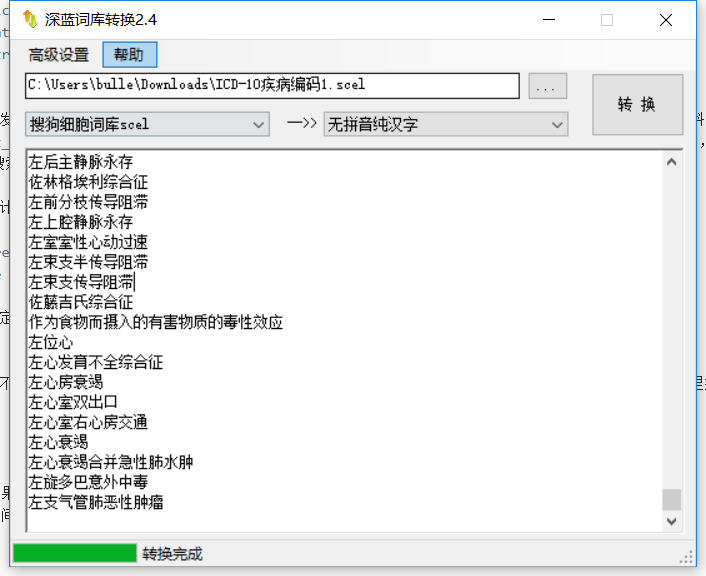
我发现搜狗的词库真的是个很不错的地方,有太多医疗相关的语料,不过要注意的是,下载下来不能直接使用,需要使用工具解码,这里推荐『深蓝词库转换』,使用非常方便
- dict 比 list 快,但是如果不做其他操作,仅仅是读出来,不要用 for 循环
- 过滤掉一些停用词,节省时间
- 各种中文编码问题