
🔥🔥 A new version (VideoCrafter-v0.9) is now on Discord/Floor33 for high-resolution and high-fidelity video generation. Please Join us and create your own film.

🔆 Introduction (Showcases)
🤗🤗🤗 VideoCrafter is an open-source video generation and editing toolbox for crafting video content.
It currently includes the following THREE types of models:
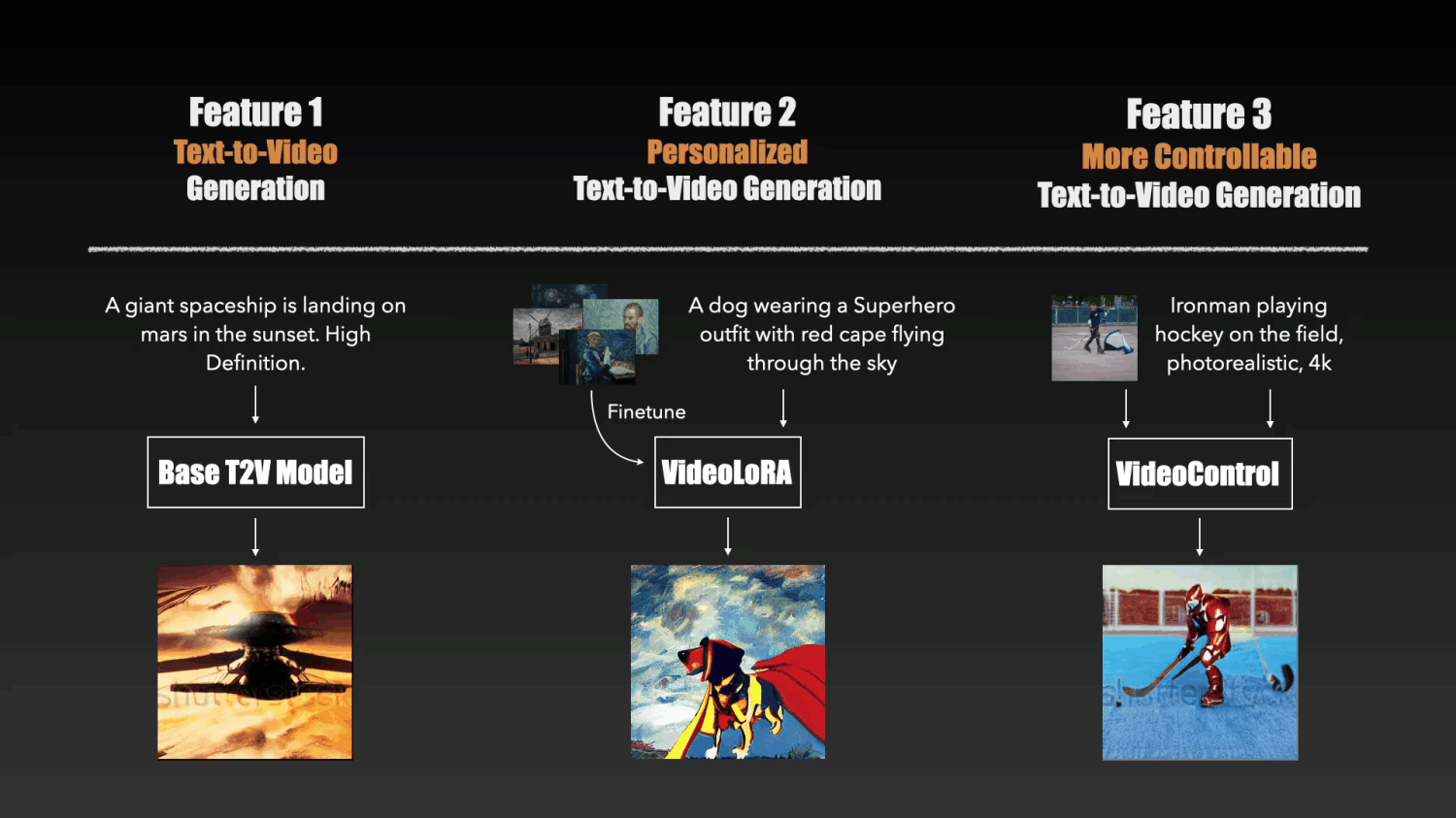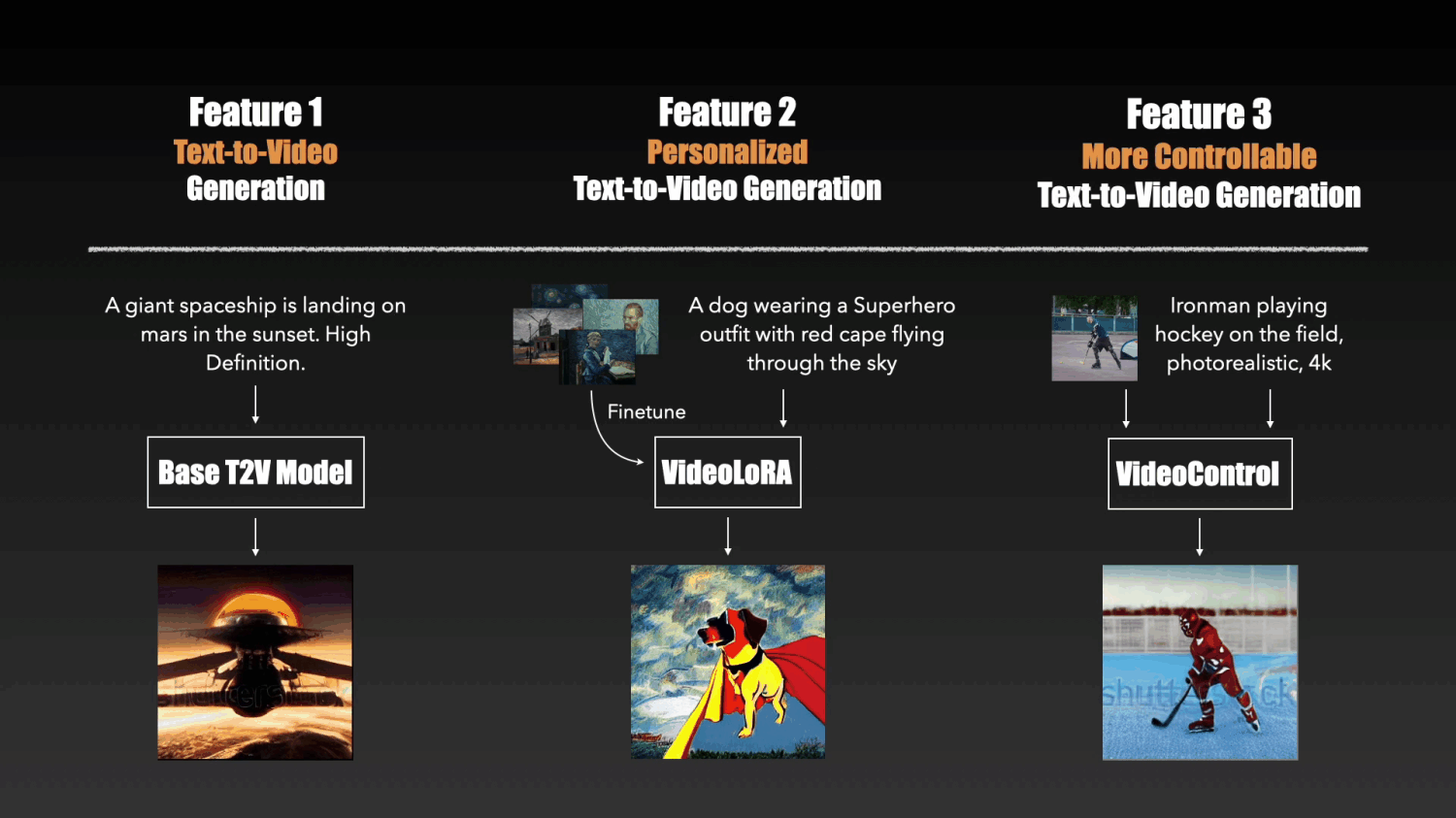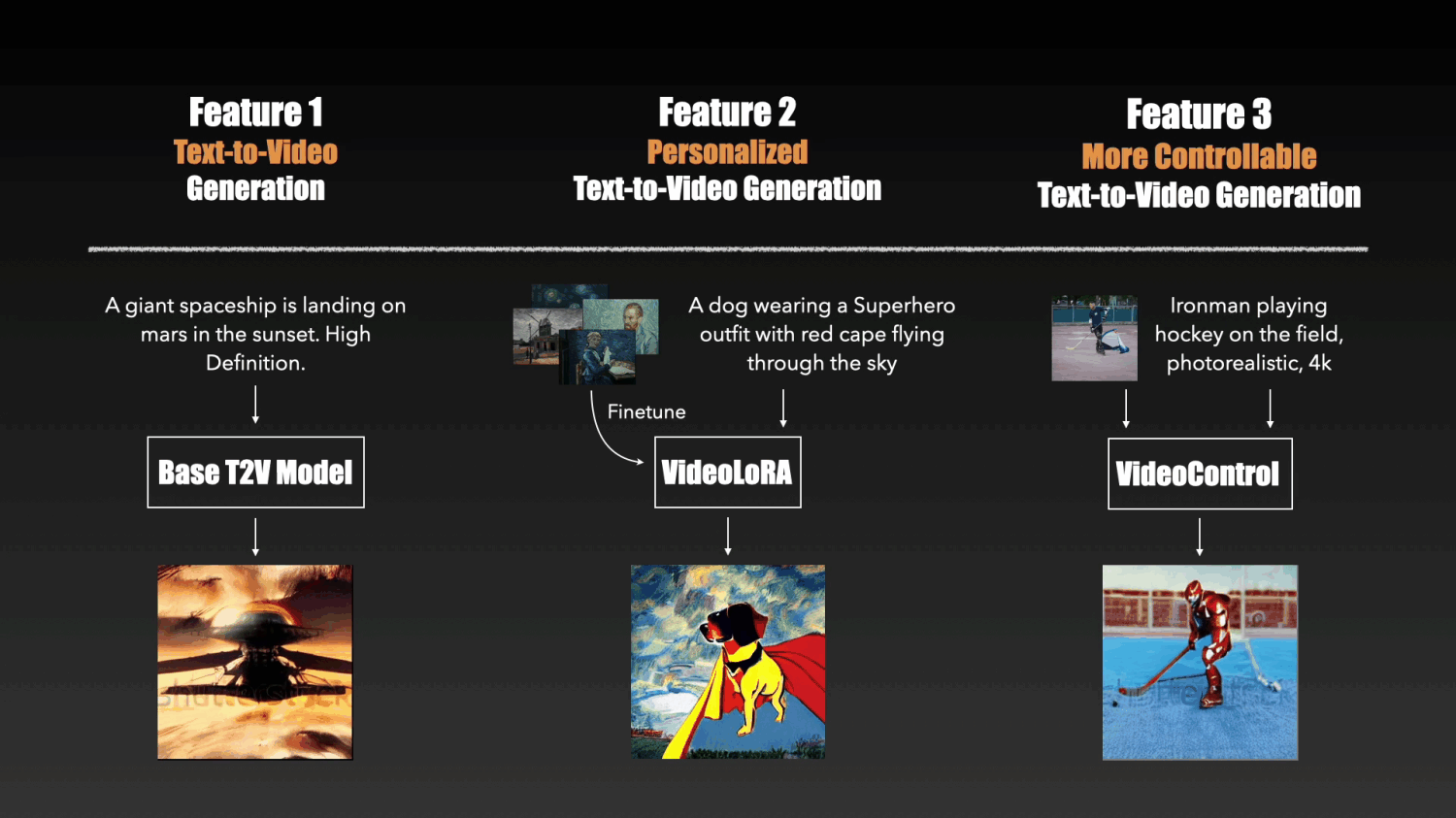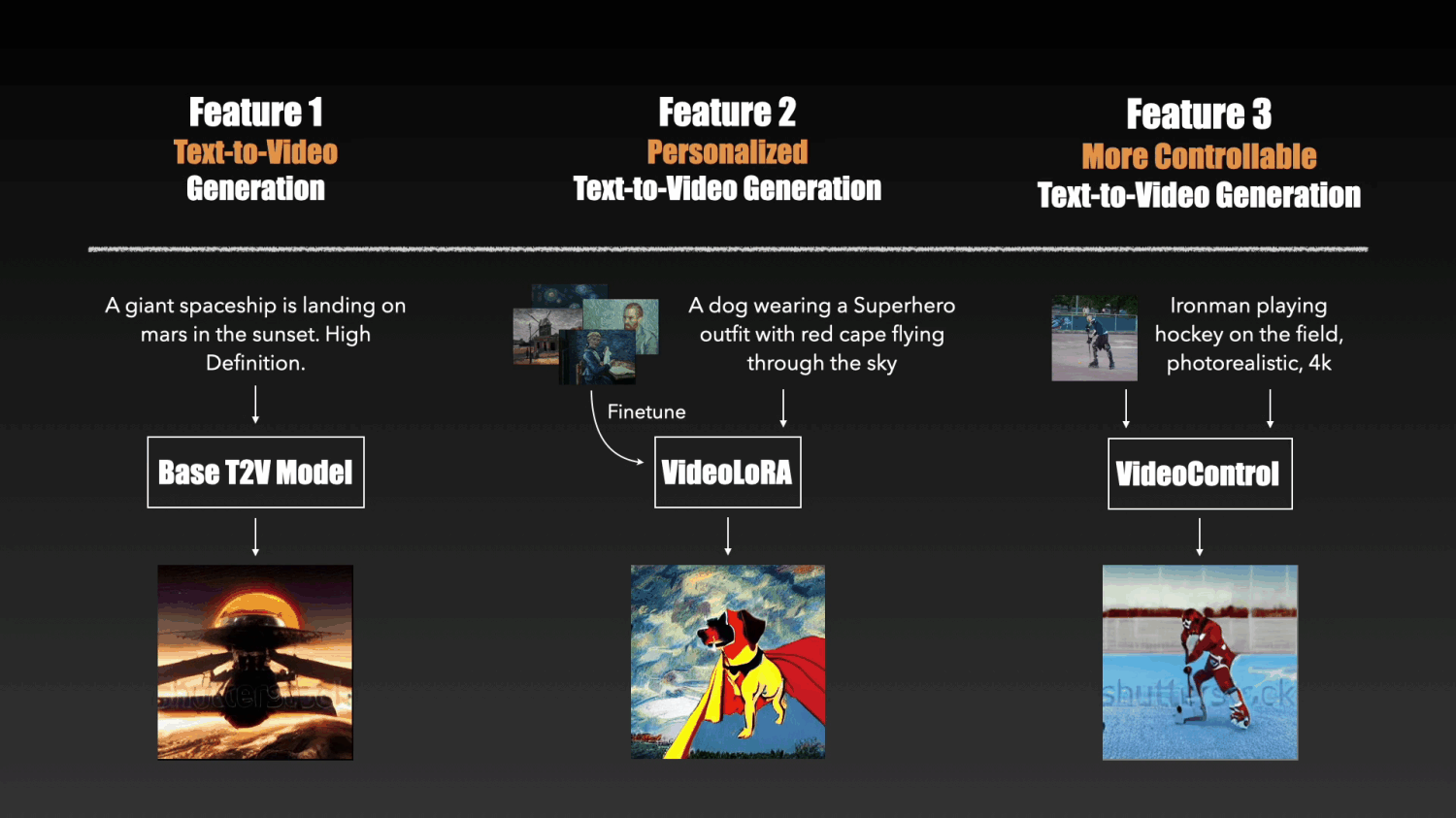
We provide a base text-to-video (T2V) generation model based on the latent video diffusion models (LVDM). It can synthesize realistic videos based on the input text descriptions.
| "Campfire at night in a snowy forest with starry sky in the background." | "Cars running on the highway at night." | "close up of a clown fish swimming. 4K" | "astronaut riding a horse" |
 |
 |
 |
 |
Based on the pretrained LVDM, we can create our own video generation models by finetuning it on a set of video clips or images describing a certain concept.
We adopt LoRA to implement the finetuning as it is easy to train and requires fewer computational resources.
Below are generation results from our four VideoLoRA models that are trained on four different styles of video clips.
By providing a sentence describing the video content along with a LoRA trigger word (specified during LoRA training), it can generate videos with the desired style(or subject/concept).
Results of inputting A monkey is playing a piano, ${trigger_word} to the four VideoLoRA models:
 |
 |
 |
 |
| "Loving Vincent style" | "frozenmovie style" | "MakotoShinkaiYourName style" | "coco style" |
To enhance the controllable abilities of the T2V model, we developed conditional adapter inspired by T2I-adapter. By pluging a lightweight adapter module to the T2V model, we can obtained generation results with more detailed control signals such as depth.
input text: Ironman is fighting against the enemy, big fire in the background, photorealistic, 4k
 |
 |
 |
 |
 |
🤗🤗🤗 We will keep updating this repo and add more features and models. Please stay tuned!
- [2023.04.05]: Release pretrained Text-to-Video models, VideoLora models, and inference code.
- [2023.04.07]: Hugging Face Gradio demo and Colab demo released.
- [2023.04.11]: Release the VideoControl model for depth-guided video generation.
- [2023.04.12]: VideoControl is on Hugging Face now!
- [2023.04.13]: VideoControl supports different resolutions and up to 8-second text-to-video generation.
- [2023.04.18]: Release a new base T2V model and a VideoControl model with most of the watermarks removed! The LoRA models can be directly combined with the new T2V model.
- [2023.08.14]: 🔥 Release a new version of VideoCrafter on Discord/Floor33. Please join us to create your own film!
- Hugging Face Gradio demo & Colab
- Release the VideoControl model for depth
- Release new base model with NO WATERMARK
- Release VideoControl models for other types, such as canny and pose
- Technical report
- Release training code for VideoLoRA
- Release 512x512 high-resolution version of VideoControl model
- More customized models
Choose one of the following three approaches.
conda create -n lvdm python=3.8.5
conda activate lvdm
pip install -r requirements.txtCLICK ME to show details
conda create -n lvdm python=3.8.5
conda activate lvdm
pip install torch==1.12.1+cu113 torchvision==0.13.1+cu113 -f https://download.pytorch.org/whl/torch_stable.html
pip install pytorch-lightning==1.8.3 omegaconf==2.1.1 einops==0.3.0 transformers==4.25.1
pip install opencv-python==4.1.2.30 imageio==2.9.0 imageio-ffmpeg==0.4.2
pip install av moviepy
pip install -e .Useful for saving GPU memory
conda create -n lvdm python=3.8.5
conda activate lvdm
pip install -r requirements_xformer.txtCLICK ME to check the cost of GPU memory and sampling time
We tested the sampling_text2video.sh on RTX 3090 and A100 GPUs in two environments. The minimum requirement for GPU memory is at least 7GB.| GPU Name | CUDA Version | Environment | GPU Memory | Sampling Time (s) |
| RTX 3090 | 10.1 | no xformer | 8073M | 30 |
| ↑ | ↑ | with xformer | 6867M | 20 |
| A100 | 11.3 | no xformer | 9140M | 19 |
| ↑ | ↑ | with xformer | 8052M | 17 |
- Download pretrained T2V models via Google Drive / Hugging Face, and put the
model.ckptinmodels/base_t2v/model.ckpt. - Input the following commands in terminal, it will start running in the GPU 0.
PROMPT="astronaut riding a horse"
OUTDIR="results/"
BASE_PATH="models/base_t2v/model.ckpt"
CONFIG_PATH="models/base_t2v/model_config.yaml"
python scripts/sample_text2video.py \
--ckpt_path $BASE_PATH \
--config_path $CONFIG_PATH \
--prompt "$PROMPT" \
--save_dir $OUTDIR \
--n_samples 1 \
--batch_size 1 \
--seed 1000 \
--show_denoising_progressCLICK ME for more options
Set device:--gpu_id: specify the gpu index you want to use--ddp: better to enable it if you have multiple GPUs- We also provide a reference shell script for using multiple GPUs via PyTorch DDP in
sample_text2video_multiGPU.sh
Change video duration:
--num_frames: specify the number of frames of output videos, such as 64 frames
-
Same with 1-1: Download pretrained T2V models via Google Drive / Hugging Face, and put the
model.ckptinmodels/base_t2v/model.ckpt. -
Download pretrained VideoLoRA models via this Google Drive / Hugging Face (can select one videolora model), and put it in
models/videolora/${model_name}.ckpt. -
Input the following commands in terminal, it will start running in the GPU 0.
PROMPT="astronaut riding a horse"
OUTDIR="results/videolora"
BASE_PATH="models/base_t2v/model.ckpt"
CONFIG_PATH="models/base_t2v/model_config.yaml"
LORA_PATH="models/videolora/lora_001_Loving_Vincent_style.ckpt"
TAG=", Loving Vincent style"
python scripts/sample_text2video.py \
--ckpt_path $BASE_PATH \
--config_path $CONFIG_PATH \
--prompt "$PROMPT" \
--save_dir $OUTDIR \
--n_samples 1 \
--batch_size 1 \
--seed 1000 \
--show_denoising_progress \
--inject_lora \
--lora_path $LORA_PATH \
--lora_trigger_word "$TAG" \
--lora_scale 1.0CLICK ME for the TAG of all lora models
LORA_PATH="models/videolora/lora_001_Loving_Vincent_style.ckpt"
TAG=", Loving Vincent style"
LORA_PATH="models/videolora/lora_002_frozenmovie_style.ckpt"
TAG=", frozenmovie style"
LORA_PATH="models/videolora/lora_003_MakotoShinkaiYourName_style.ckpt"
TAG=", MakotoShinkaiYourName style"
LORA_PATH="models/videolora/lora_004_coco_style.ckpt"
TAG=", coco style"-
If your find the lora effect is either too large or too small, you can adjust the
lora_scaleargument to control the strength.CLICK ME for the visualization of different lora scales
The effect of LoRA weights can be controlled by the
lora_scale.local_scale=0indicates using the original base model, whilelocal_scale=1indicates using the full lora weights. It can also be slightly larger than 1 to emphasize more effect from lora.scale=0.0 scale=0.25 scale=0.5 


scale=0.75 scale=1.0 scale=1.5 








- Same with 1-1: Download pretrained T2V models via Google Drive / Hugging Face, and put the
model.ckptinmodels/base_t2v/model.ckpt. - Download the Adapter model via Google Drive / Hugging Face and put it in
models/adapter_t2v_depth/adapter.pth. - Download the MiDas, and put in
models/adapter_t2v_depth/dpt_hybrid-midas.pt. - Input the following commands in terminal, it will start running in the GPU 0.
PROMPT="An ostrich walking in the desert, photorealistic, 4k"
VIDEO="input/flamingo.mp4"
OUTDIR="results/"
NAME="video_adapter"
CONFIG_PATH="models/adapter_t2v_depth/model_config.yaml"
BASE_PATH="models/base_t2v/model.ckpt"
ADAPTER_PATH="models/adapter_t2v_depth/adapter.pth"
python scripts/sample_text2video_adapter.py \
--seed 123 \
--ckpt_path $BASE_PATH \
--adapter_ckpt $ADAPTER_PATH \
--base $CONFIG_PATH \
--savedir $OUTDIR/$NAME \
--bs 1 --height 256 --width 256 \
--frame_stride -1 \
--unconditional_guidance_scale 15.0 \
--ddim_steps 50 \
--ddim_eta 1.0 \
--prompt "$PROMPT" \
--video $VIDEOCLICK ME for more options
Set device:- Use multiple GPUs:
bash sample_adapter_multiGPU.sh
Change video duration:
--num_frames: specify the number of frames of output videos, such as 64 frames
- We provide a gradio-based web interface for convenient inference, which currently supports the pretrained T2V model and several VideoLoRA models. After installing the environment and downloading the model to the appropriate location, you can launch the local web service with the following script.
python gradio_app.py - The online version is available on Hugging Face.
| "A blue unicorn flying over a mystical land" | "A teddy bear washing the dishes" | "Flying through an intense battle between pirate ships in a stormy ocean" | "a rabbit driving a bicycle, in Tokyo at night" |
 |
 |
 |
 |
| "A fire is burning on a candle." | "A giant spaceship is landing on mars in the sunset. High Definition." | "A bear dancing and jumping to upbeat music, moving his whole body." | "Face of happy macho mature man smiling." |
 |
 |
 |
 |
| "A man playing a saxophone with musical notes flying out." | "Flying through an intense battle between pirate ships in a stormy ocean" | "Horse drinking water." | "Woman in sunset." |
 |
 |
 |
 |
| "Humans building a highway on mars, highly detailed" | "A blue unicorn flying over a mystical land" | "Robot dancing in times square" | "A 3D model of an elephant origami. Studio lighting." |
 |
 |
 |
 |
| "A camel walking on the snow field, Miyazaki Hayao anime style" | ||||
 |
 |
 |
 |
 |
| "Ironman playing hockey on the field, photorealistic, 4k" | ||||
 |
 |
 |
 |
 |
| "An ostrich walking in the desert, photorealistic, 4k" | ||||
 |
 |
 |
 |
 |
| "A car turning around on a countryside road, snowing heavily, ink wash painting" | ||||
 |
 |
 |
 |
 |
⏳⏳⏳ Comming soon. We are still working on it.💪
The technical report is currently unavailable as it is still in preparation. You can cite the paper of our base model, on which we built our applications.
@article{he2022lvdm,
title={Latent Video Diffusion Models for High-Fidelity Long Video Generation},
author={Yingqing He and Tianyu Yang and Yong Zhang and Ying Shan and Qifeng Chen},
year={2022},
eprint={2211.13221},
archivePrefix={arXiv},
primaryClass={cs.CV}
}
If your have any comments or questions, feel free to contact Yingqing He, Haoxin Chen or Menghan Xia.
Our codebase builds on Stable Diffusion, LoRA, T2I-Adapter, and MiDaS. Thanks the authors for sharing their awesome codebases!
We develop this repository for RESEARCH purposes, so it can only be used for personal/research/non-commercial purposes.