This is my hobby project by using System Verilog. I worked on this project continuously for about 4-5 weeks, only dedicating evenings and weekends to it. I wrote approximately 2000+ lines of SV design code and 1900+ testbench code in total. It will cost 97000+ LUT and 51000+ FF in FPGA implementation(Vivado).
This work is based on LeViT: a Vision Transformer in ConvNet’s Clothing for Faster Inference.
But I've simplified the original large network into a smaller one, so I call it Tiny_LeViT.
All design file are in src folder and testbench in sim folder, include:
Completed:
- finishied Tiny LeViT Hardware Accelerator.
- finished Convolutional layer and Attention layer.
- finished Tanh function and divider module.
- finished Average pooling module.
Of course, due to the complexity of hardware accelerators and network functions, many problems arise during the simplification process, some of which are yet to be resolved or will be addressed in the future.
Problem:
- It not support float-point number and arithmetic operation.
- It not support multi-channel.
- It can be synthesized but I didn't verify the post-synthesize timing simulation.
- It has wrong connection in multi-head block because I don't understand multi-head attention when I make it (Multi-head results should be spliced together into a matrix instead of being added.).
- Divider is not good and some module will have overflow problem.
Anyway, if you have questions or improvements, just tell me. Thanks!
src/Tiny_LeViT_top.svis the top level of Tiny_LeViT. It contain three convolutional layer(16,8,4), four stage1(2-head attention and MLP) and stage2(4-head attention and MLP). In the end, it has e average pooling module.- Define every parameter in
src/definition.sv. - Input number is 8-bit, but it will change in later module.
- Most of module have two signals or flags:
endwhich indicate output result andenwhich enable the module.

- This is synchronizer which have two D flip-flop.

- This module can generate enable signal accroding to last module's end signal and their own end signal. It seems like handshake.
- Use row stationary (RS) to get max parallel computing. Every PE can compting 1D row convolution, all PEs can parallel in same time.
src/Conv_core_sa.svandsrc/PE_ROW_SystolicArry.svis normal version of convolution layer which delay is only 3 cycle from input data to first output data.- Other convolutional core aim to accelerate the convolutional layer when stride=2 and padding=1. Delay:
src/Conv16_core.sv: 10 cycle,src/Conv8_core.sv: 6 cycle,src/Conv4_core.sv: 4 cycle.

- Use 1D Systolic array to do 1D convolution. Use FSM to control the data flow.

- The basic PE which can only support multiply and accumulate operation.

- Stage module contain 2-head attention or 4-head attention and then 2 MLP layer.

src/Stage_2head.svhave 2 attention core and 1 MLP.src/Stage_4head.svhave 4 attention core and 1 MLP.

- For attention layer, use Tanh instead of softmax and use ReLU instead of Hardswish to simplify that difficulty of hardware calculation.
- Tanh function is a complex module in this core.
- We need buffer to store the data and do matrix multiplication.
- Delay is 34 cycle.
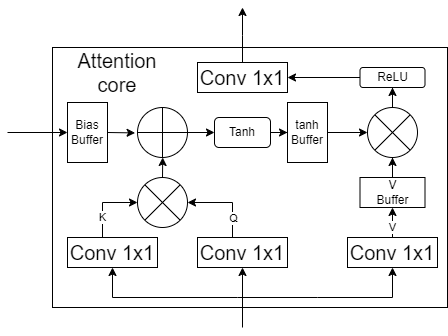

- Use 2D Systolic array to do 2D matrix multiplication.

- formula of tanh is
$\frac{e^x - e^{(-x)}}{e^x+e^{(-x)}}$ . - This module contain two Exp module and 1 divider.

- Divider is a basic module which is combinational logic.
i_upandi_boindicate the two input(up and down).coutis the result andremis remainder.
- In order to calculate the exponential function, we use the expansion to approximate the fourth order.
- The formula is
$exp(x)=1+x(1+\frac{x}{2} (1+\frac{x}{3}(1+\frac{x}{4})))$ . - This module also use 1 divider.

- MLP layer only use 1x1 convolution, so it is very easy. You can extend it to multi channel in the future.
- Now, it can only support caculate value's average number, not a real pooling.
