🌐 Homepage | 🤗 Dataset | 📖 Paper | 💻 Evaluation
- 🔥 Todo: Coming, integrate MRAG-Bench to LMMs-Eval and VLMEvalKit, enabling rapid evaluation on Large Vision Language Models.
- 🔥 [2024-10-10] MRAG-Bench evaluation code is released.
- 🔥 [2024-10-10] MRAG-Bench is released.
MRAG-Bench consists of 16,130 images and 1,353 human-annotated multiple-choice questions across 9 distinct scenarios, providing a robust and systematic evaluation of Large Vision Language Model (LVLM)’s vision-centric multimodal retrieval-augmented generation (RAG) abilities.
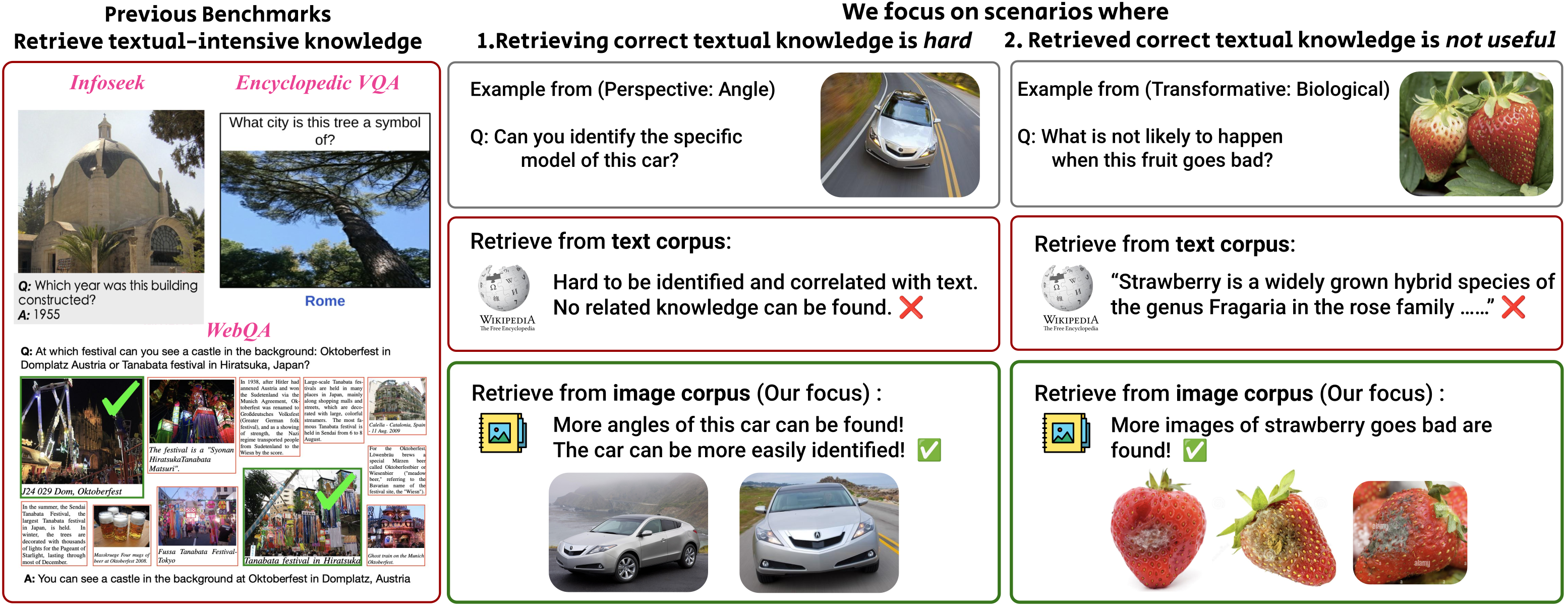
Evaluated upon 10 open-source and 4 proprietary LVLMs, our results show that all LVLMs exhibit greater improvements when augmented with images compared to textual knowledge. Notably, the top-performing model, GPT-4o, faces challenges in effectively leveraging retrieved knowledge, achieving only a 5.82% improvement with ground-truth information, in contrast to a 33.16% improvement observed in human participants. These findings highlight the importance of MRAG-Bench in encouraging the community to enhance LVLMs' ability to utilize retrieved visual knowledge more effectively.

from datasets import load_dataset
mrag_bench = load_dataset("uclanlp/MRAG-Bench", split="test")We provide an example evaluation code for LLaVA-OneVision-7B. First, install llava-onevision environment following here. Please refer to our scripts for setting the model output path, use rag option and use retrieved examples option. By default, use rag means use ground-truth rag examples. Then run,
bash eval/models/run_model.sh With model's results file, then please run
python eval/score.py -i "path to results file"For most models, our automatic pipeline can handle the answer extraction job. However, in cases when gpt based answer extration is needed, please set your openai api key here. We use openai==0.28.1 version for sending request.
- Wenbo Hu: whu@cs.ucla.edu
@article{hu2024mragbench,
title={MRAG-Bench: Vision-Centric Evaluation for Retrieval-Augmented Multimodal Models},
author={Hu, Wenbo and Gu, Jia-Chen and Dou, Zi-Yi and Fayyaz, Mohsen and Lu, Pan and Chang, Kai-Wei and Peng, Nanyun},
journal={arXiv preprint arXiv:2410.08182},
year={2024}
}