官网:https://pytorch.org/tutorials/beginner/pytorch_with_examples.html#id14
- 在训练过程中绘制图像
使用 visdom:https://github.com/fossasia/visdom
-
使用随机梯度下降
-
性能和复杂度折中,小批量方式mini-batch
-
训练失败可能是学习率太大
-
一般我们选择随机梯度下降
-
矩阵的求导:http://www.math.uwaterloo.ca/~hwolkowi/matrixcookbook.pdf
-
要及时对梯度清零
- 使用模板
- 分类问题的思路
离散,求出每一个类的概率,然后取其中分类概率最大的类属作为分类结果
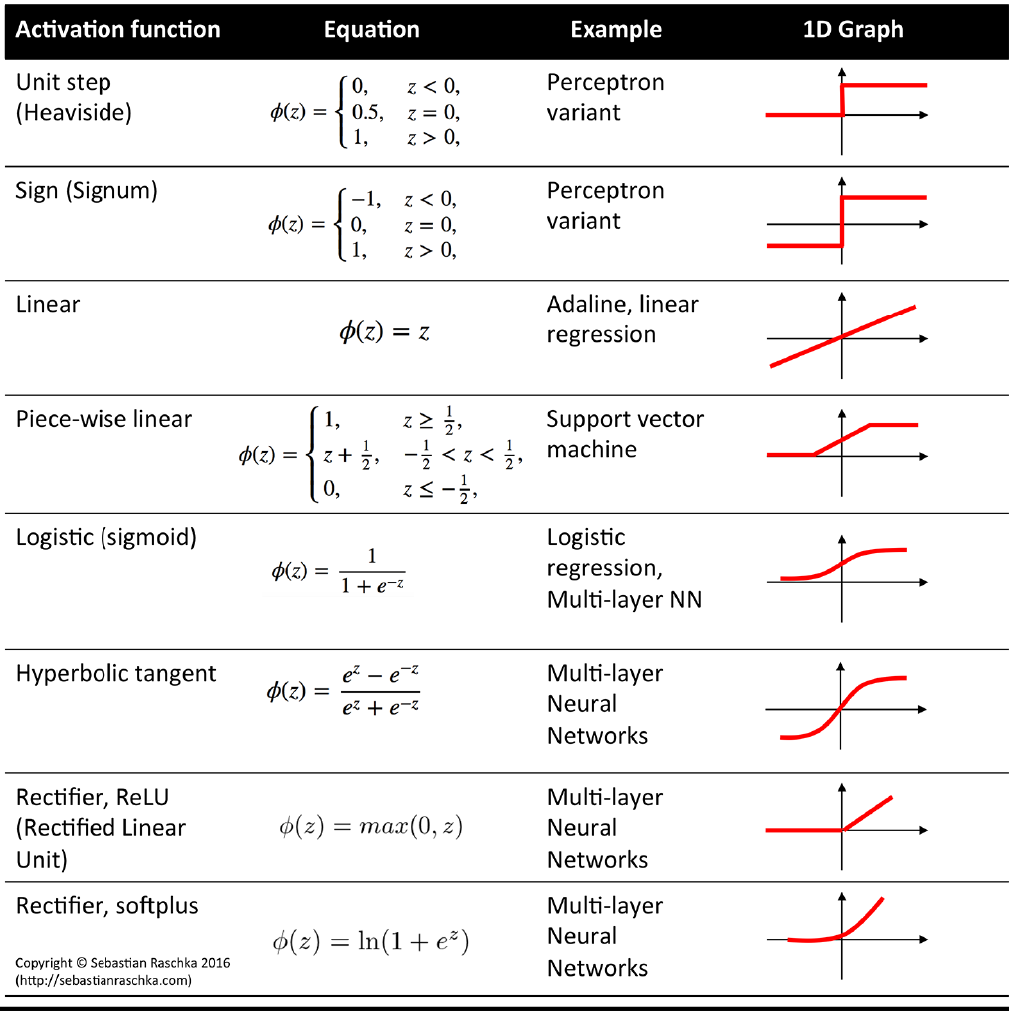
- 几类sigmod函数
- 逻辑回归需要新增激活函数
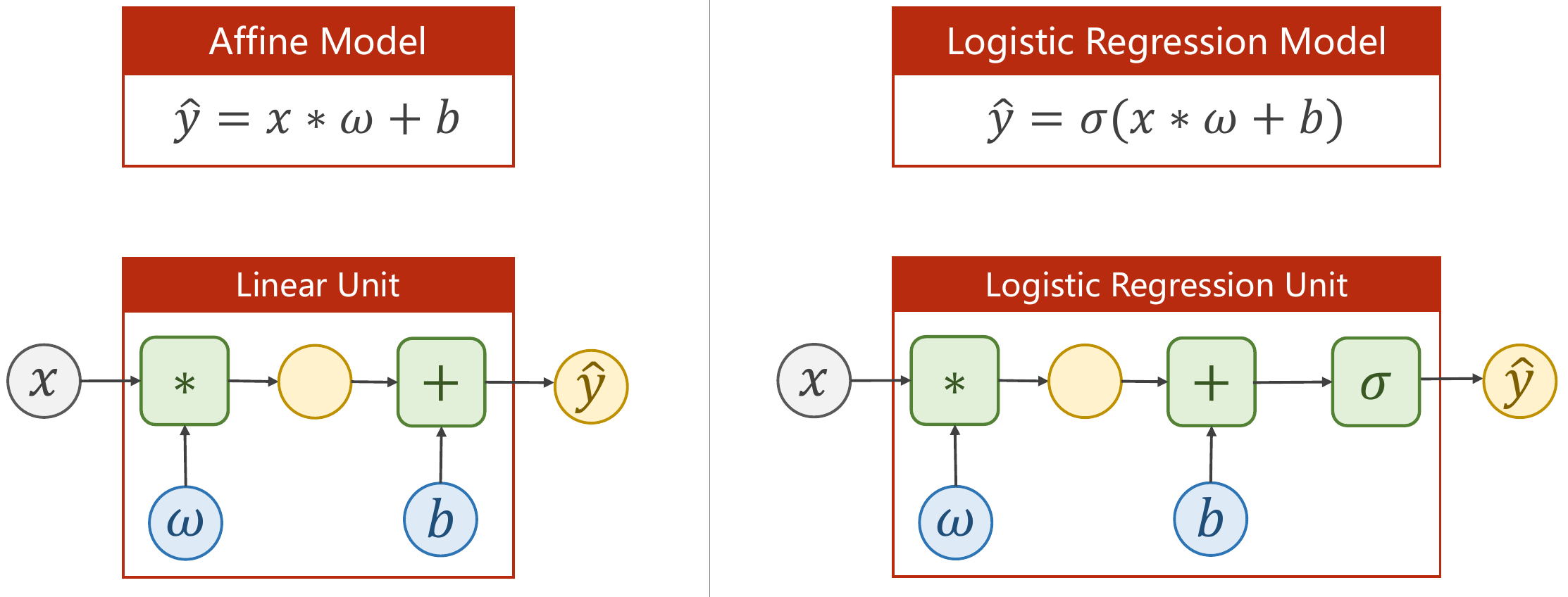
- 相应损失函数书的计算有所变化

-
BCELoss - Binary CrossEntropyLoss (二维)
BCELoss 是CrossEntropyLoss的一个特例,只用于二分类问题,而CrossEntropyLoss可以用于二分类,也可以用于多分类。 如果是二分类问题,建议BCELoss
- 数据输入
# prepare dataset
xy = np.loadtxt('../data/diabetes.csv', delimiter=',', dtype=np.float32)
x_data = torch.from_numpy(xy[:, :-1]) # 取出前-1列 Feature
y_data = torch.from_numpy(xy[:, [-1]]) # 取最后一列 label,一定要使用[-1],否则取出的不是一个矩阵,而是一个list- 层的输入关系
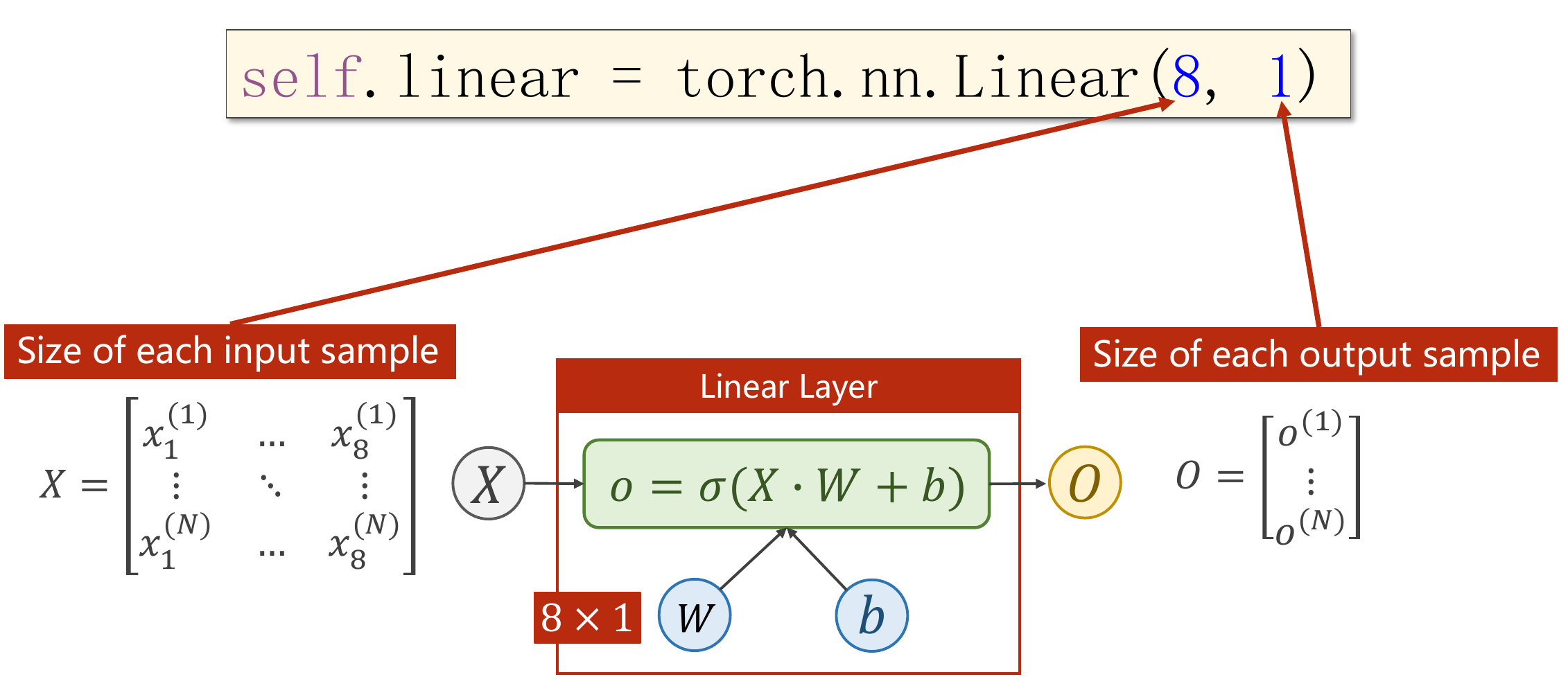
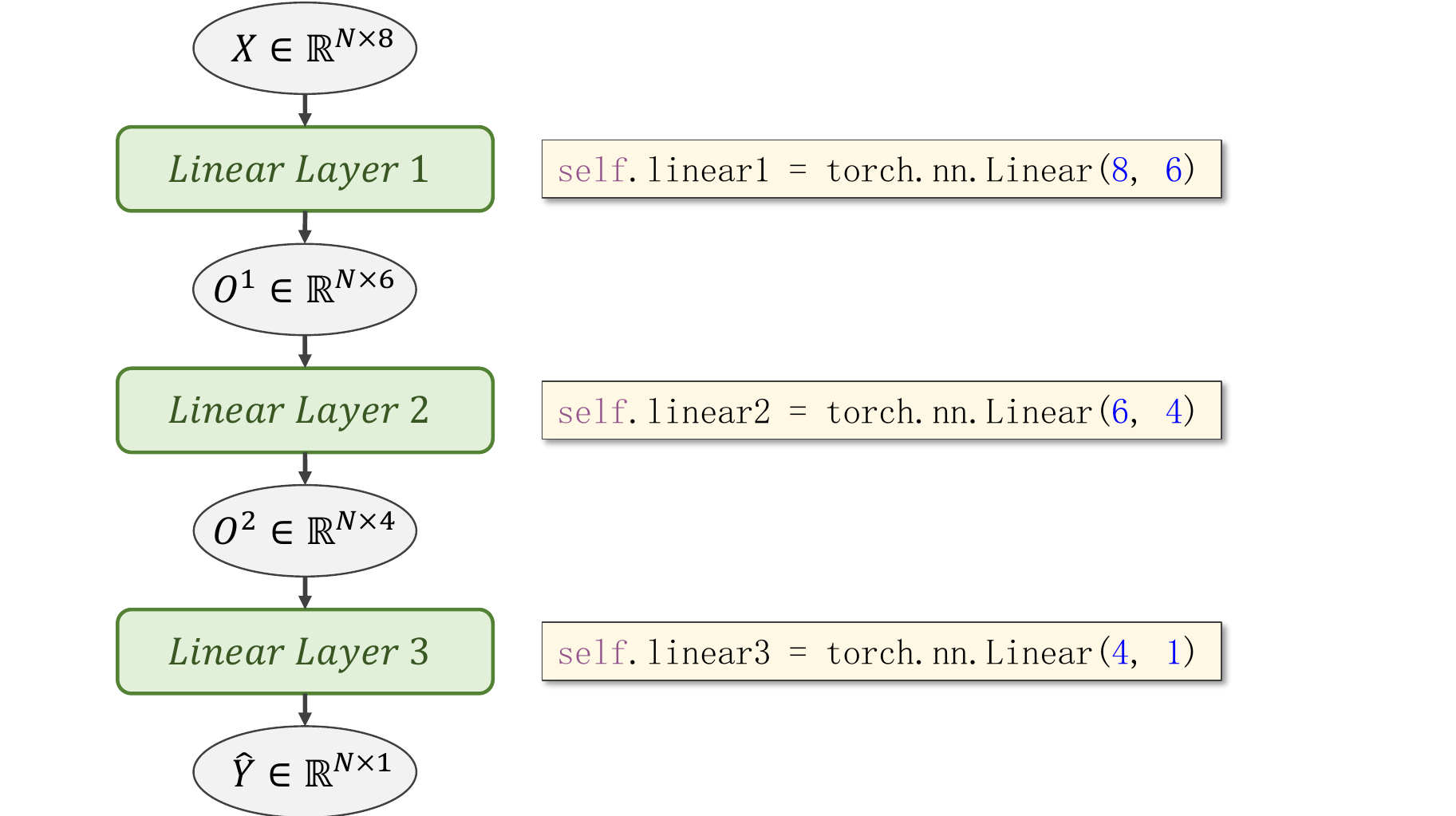
- DataSet 是抽象类,不能实例化对象,主要是用于构造我们的数据集
- DataLoader 需要获取DataSet提供的索引[i]和len;用来帮助我们加载数据,比如说做shuffle(提高数据集的随机性),batch_size,能拿出Mini-Batch进行训练。它帮我们自动完成这些工作。DataLoader可实例化对象。
- 使用min-batch可以利用并行性,提高训练效率,但是准确率不如一次性加载。
代码说明
1、需要mini_batch 就需要import DataSet和DataLoader
2、继承DataSet的类需要重写init,getitem,len魔法函数。分别是为了加载数据集,获取数据索引,获取数据总量。
3、DataLoader对数据集先打乱(shuffle),然后划分成mini_batch。
4、len函数的返回值 除以 batch_size 的结果就是每一轮epoch中需要迭代的次数。
5、inputs, labels = data中的inputs的shape是[32,8],labels 的shape是[32,1]。也就是说mini_batch在这个地方体现的
# 准备数据集
class DiabetesDataset(Dataset): # 抽象类DataSet
def __init__(self, filepath):
xy = np.loadtxt(filepath, delimiter=',', dtype=np.float32)
self.len = xy.shape[0] # shape(多少行,多少列)
self.x_data = torch.from_numpy(xy[:, :-1])
self.y_data = torch.from_numpy(xy[:, [-1]])
def __getitem__(self, index):
return self.x_data[index], self.y_data[index]
def __len__(self):
return self.len
# dataset对象
dataset = DiabetesDataset('../data/diabetes.csv')
# 使用DataLoader加载数据
train_loader = DataLoader(dataset=dataset, # dataSet对象
batch_size=32, # 每个batch的条数
shuffle=True, # 是否打乱
num_workers=4) # 多线程一般设置为4和8- 处理多分类问题的时候,由于各Feature的分类概率很大,我们要引入一个
Softmax进行归一化
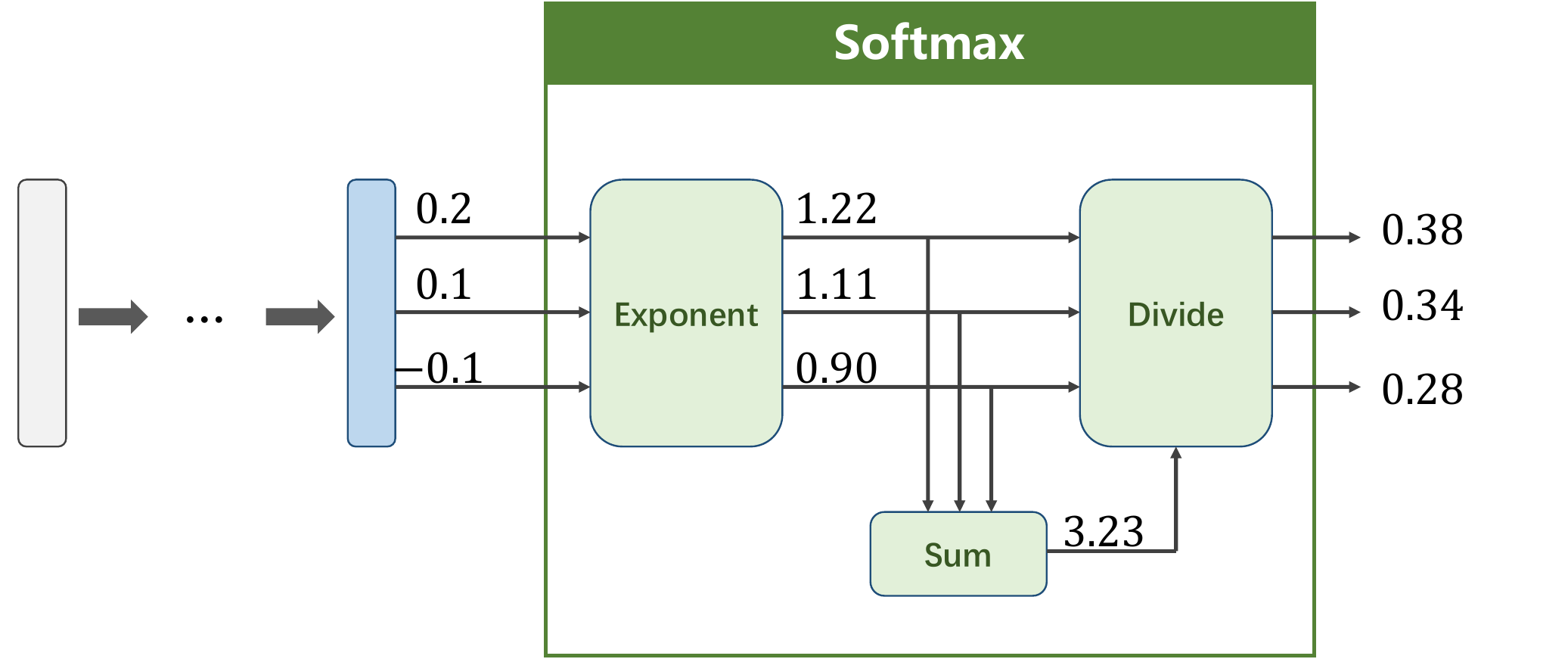
y_pred = np.exp(z) / np.exp(z).sum()CrossEntropyLoss <==> LogSoftmax + NLLLoss
- 计算交叉熵
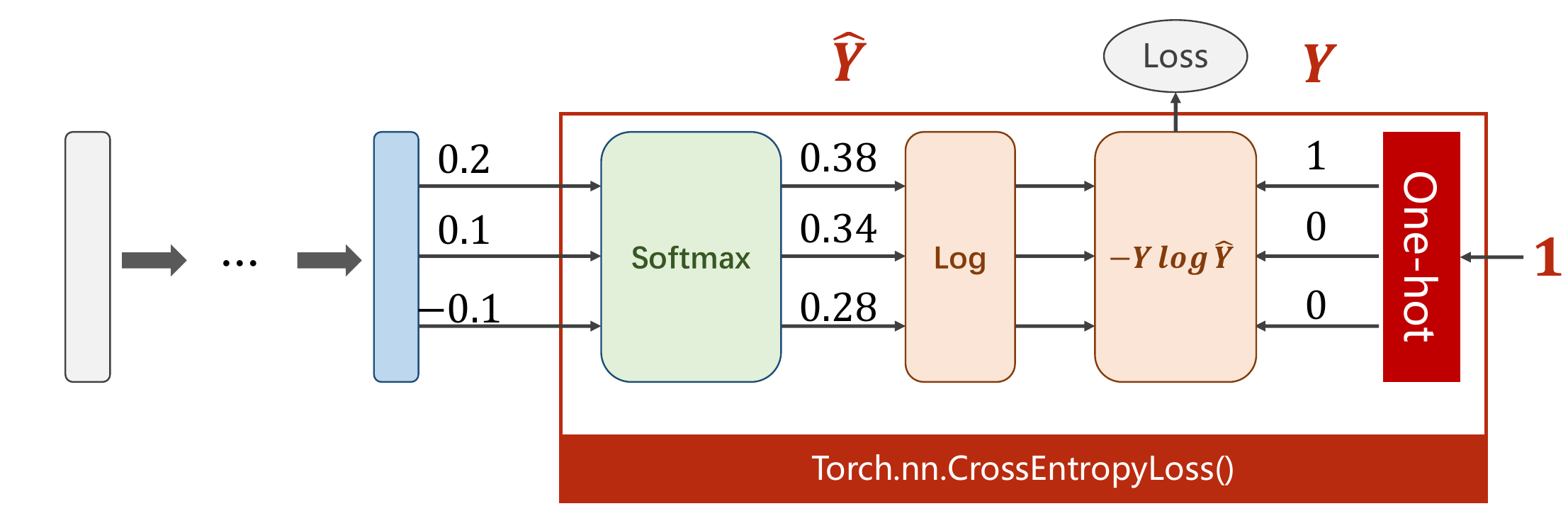
import torch
y = torch.LongTensor([0]) # 必须要用LongTensor
z = torch.Tensor([[0.2, 0.1, -0.1]])
criterion = torch.nn.CrossEntropyLoss()
loss = criterion(z, y)
print(loss)手写数字
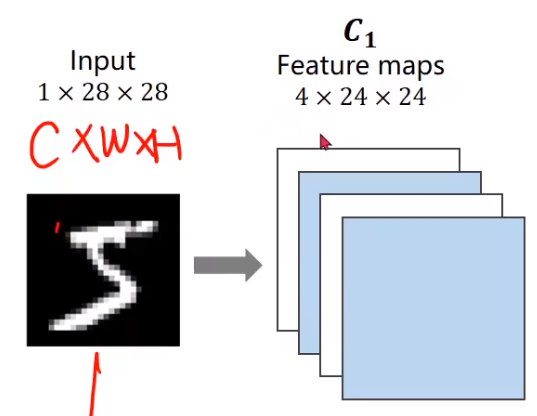
如果没有卷积神经网络保存,我们这里使用的是全连接的方法,直接将其转化为一长串的一维张量
- 图像描述
图像描述:C×W×H
左上角为o 上侧为W, 左侧为H
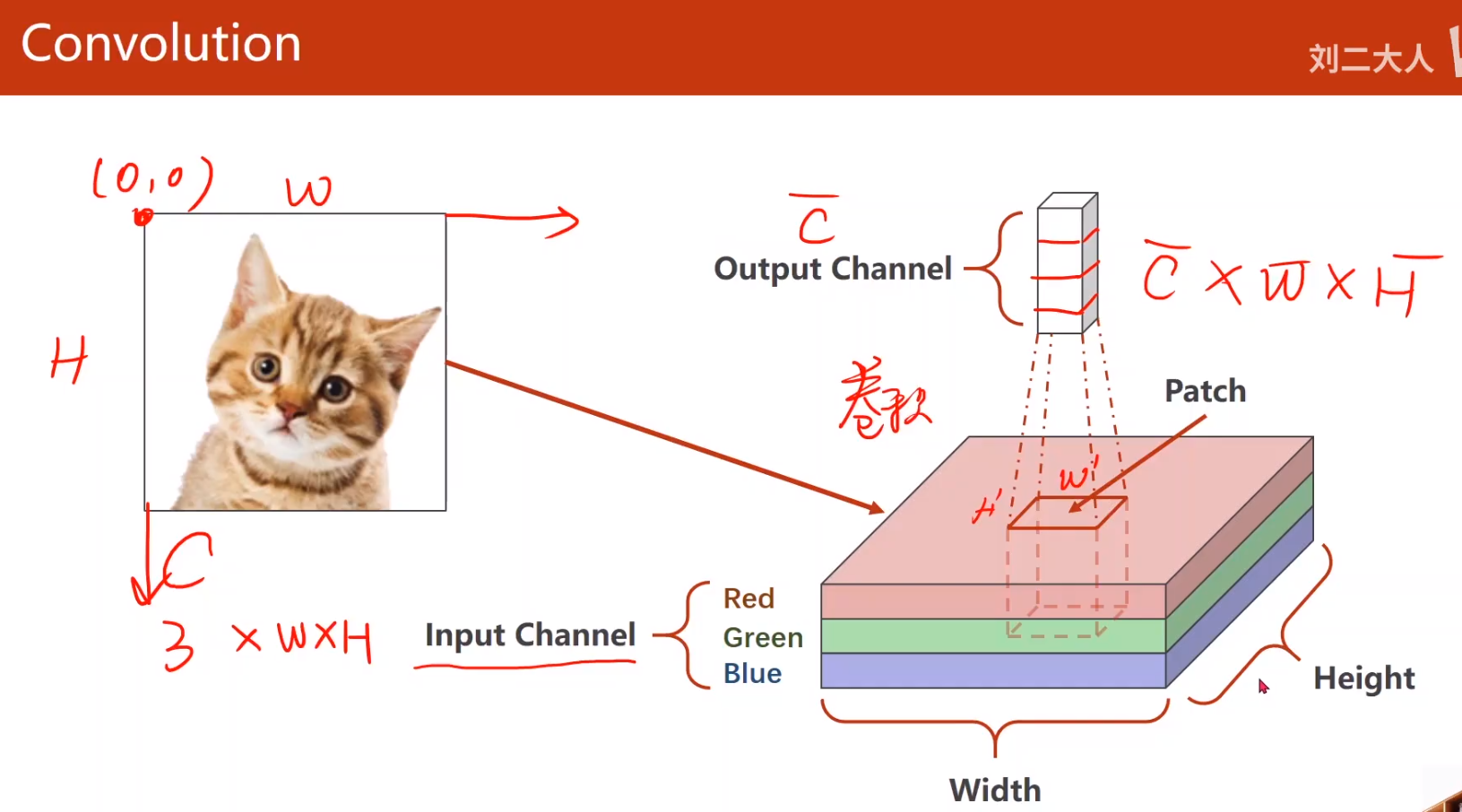
- 卷积运算
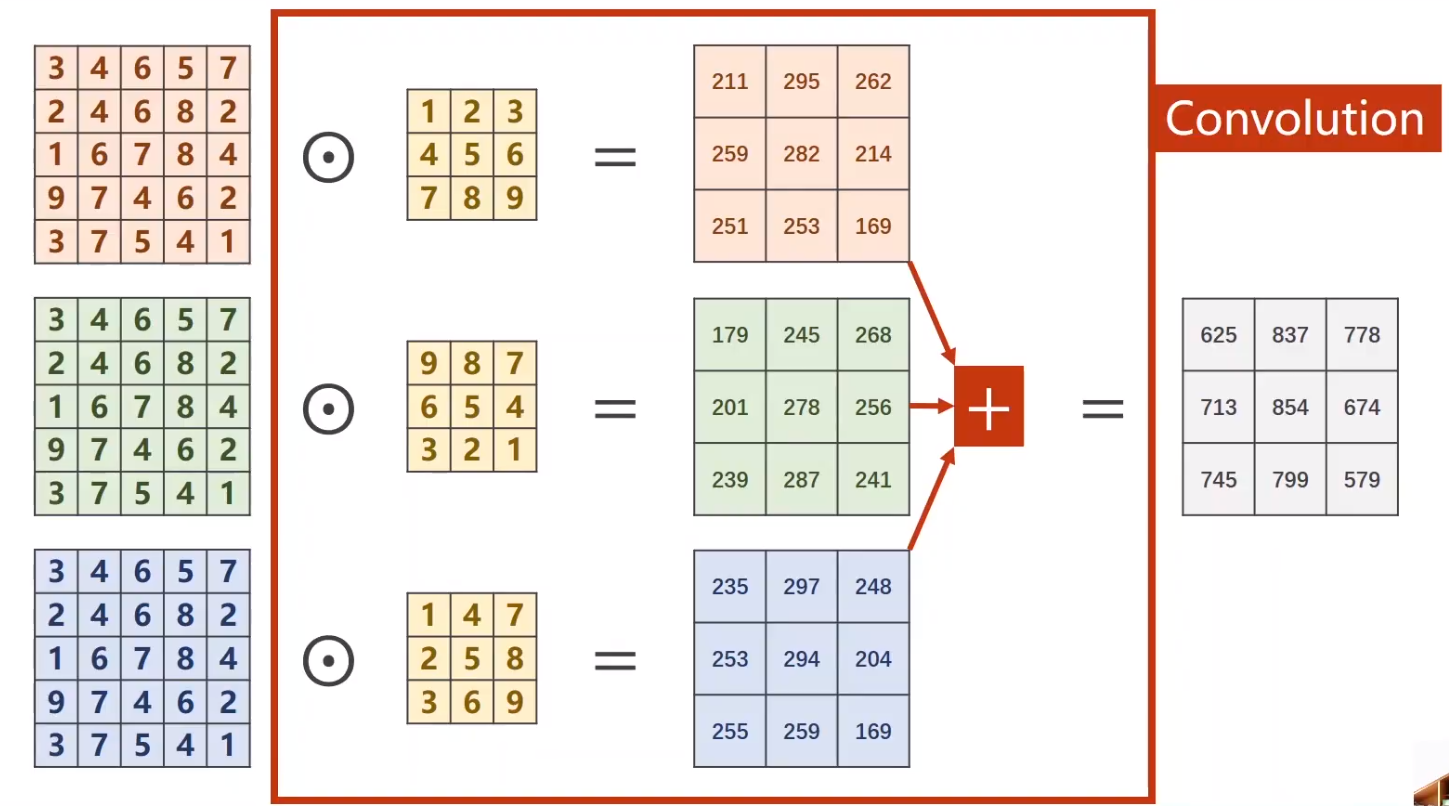
- 通过卷积核得到m×W×H的输出
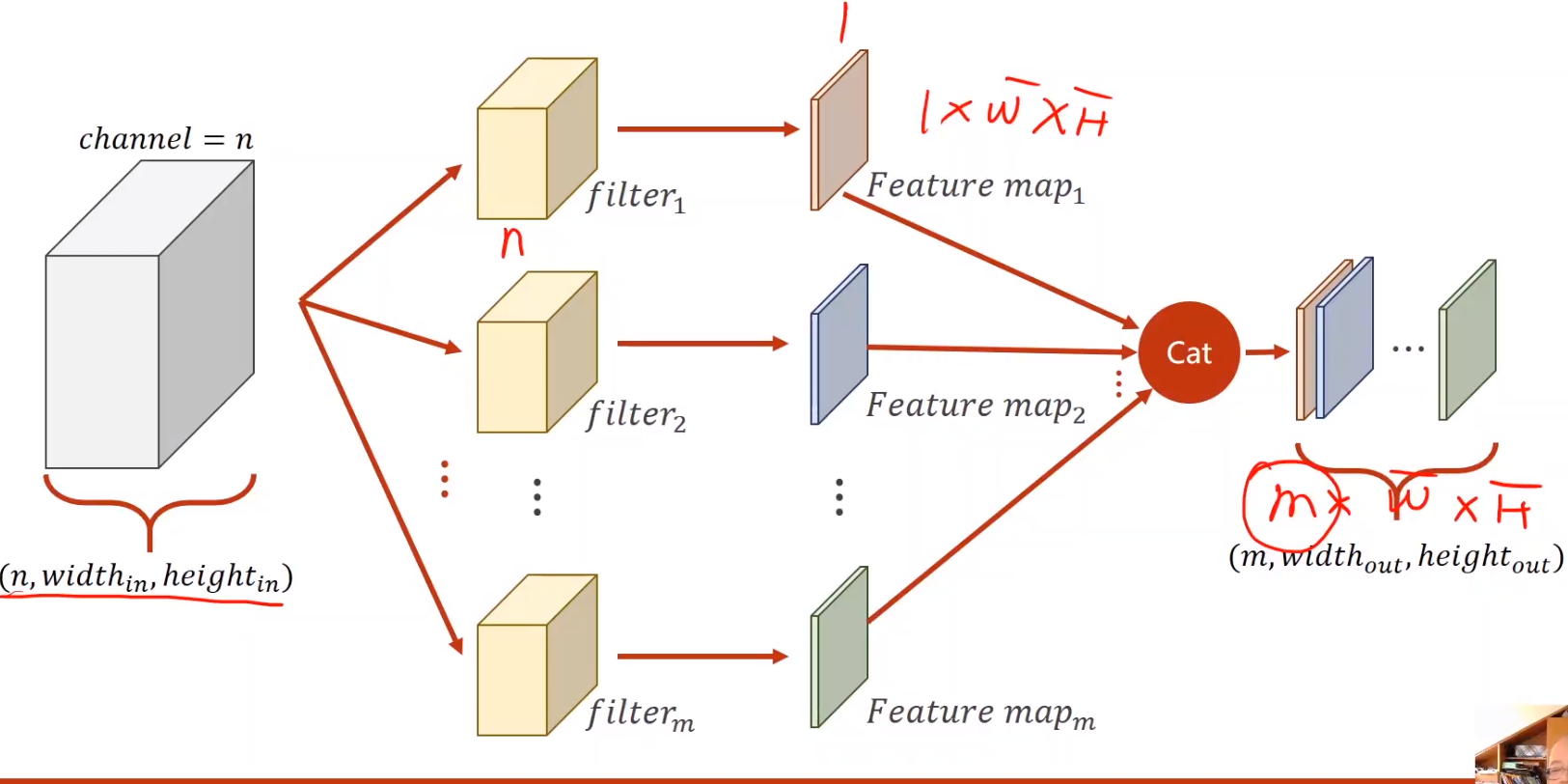
- 实例
import torch
in_channels, out_channels= 5, 10 # 输入输出通道
width, height = 100, 100 # 输入图像的宽高
kernel_size = 3 # 卷积核的大小
batch_size = 1 # batch的个数
# 输入
# [B×C×W×H]
input = torch.randn(batch_size, # 随机生成一个张量输入,模拟图像
in_channels, # input = (1,5,100,100)
width, # 对输入没有要求,除了in_channels必须要为5 否则卷积层不起作用
height)
# 定义卷积
conv_layer = torch.nn.Conv2d( in_channels, # 输入通道
out_channels, # 输出通道
kernel_size=kernel_size)# 卷积核
output = conv_layer(input) # 做卷积
print(input.shape)
print(output.shape)
print(conv_layer.weight.shape)
>>
torch.Size([1, 5, 100, 100])
torch.Size([1, 10, 98, 98])
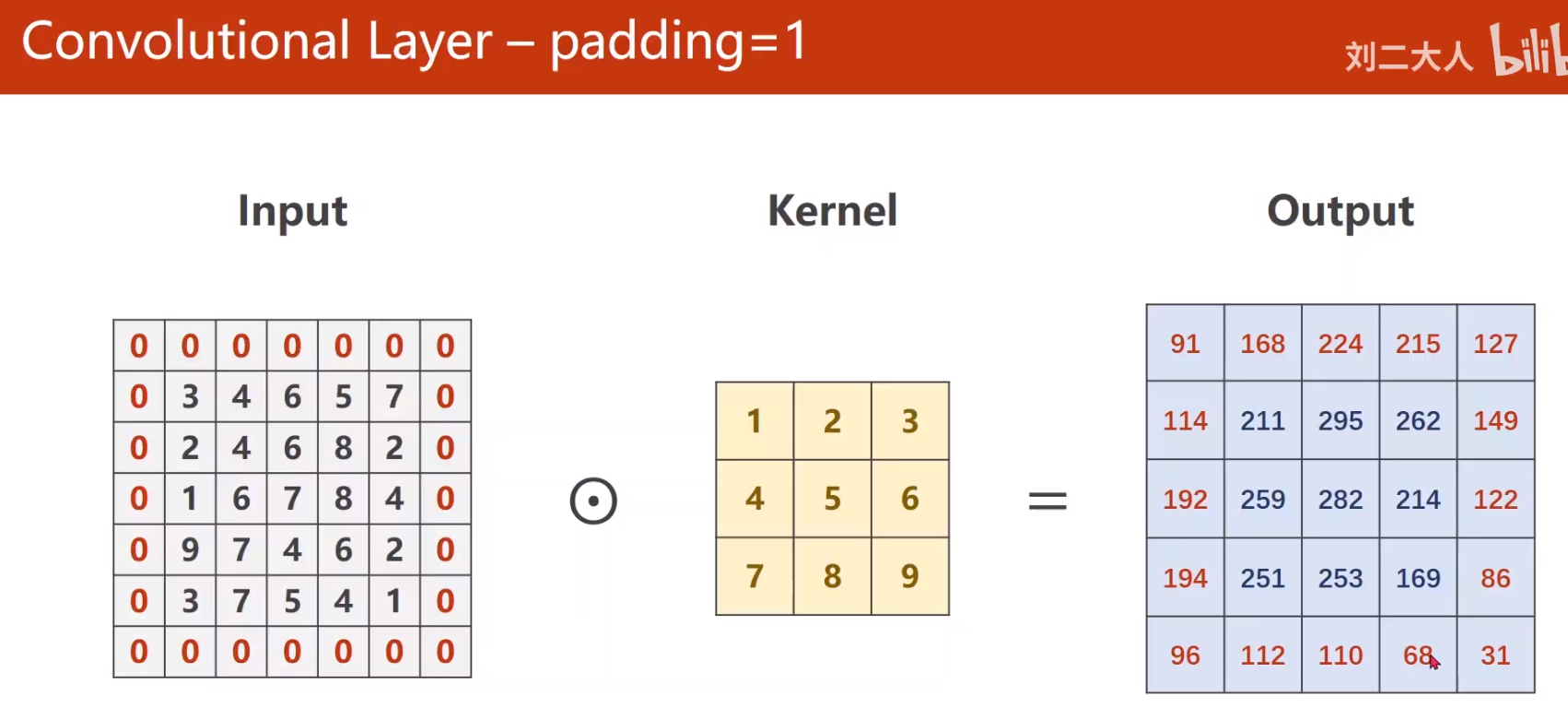
torch.Size([10, 5, 3, 3])- padding
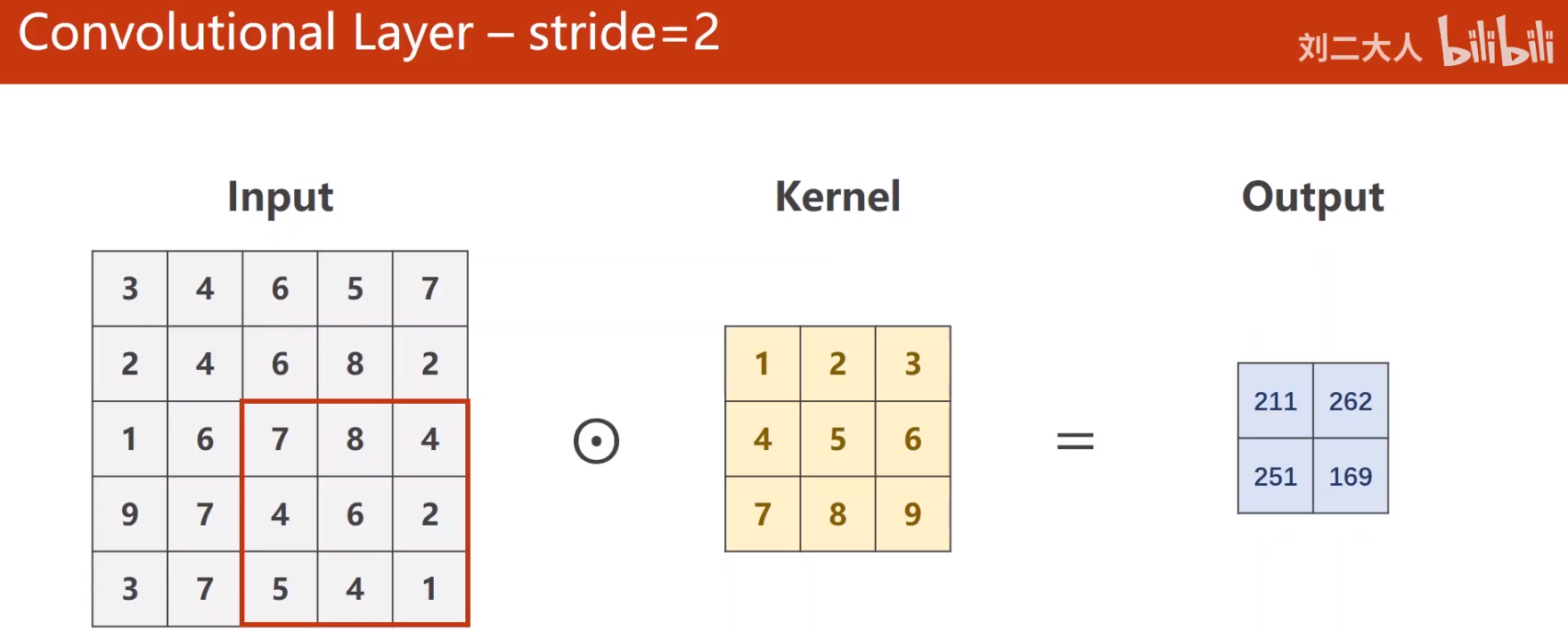
- stride
- maxpooling

maxpooling_layer = torch.nn.MaxPool2d(kernel_size=2)- 一个卷积神经网络样例
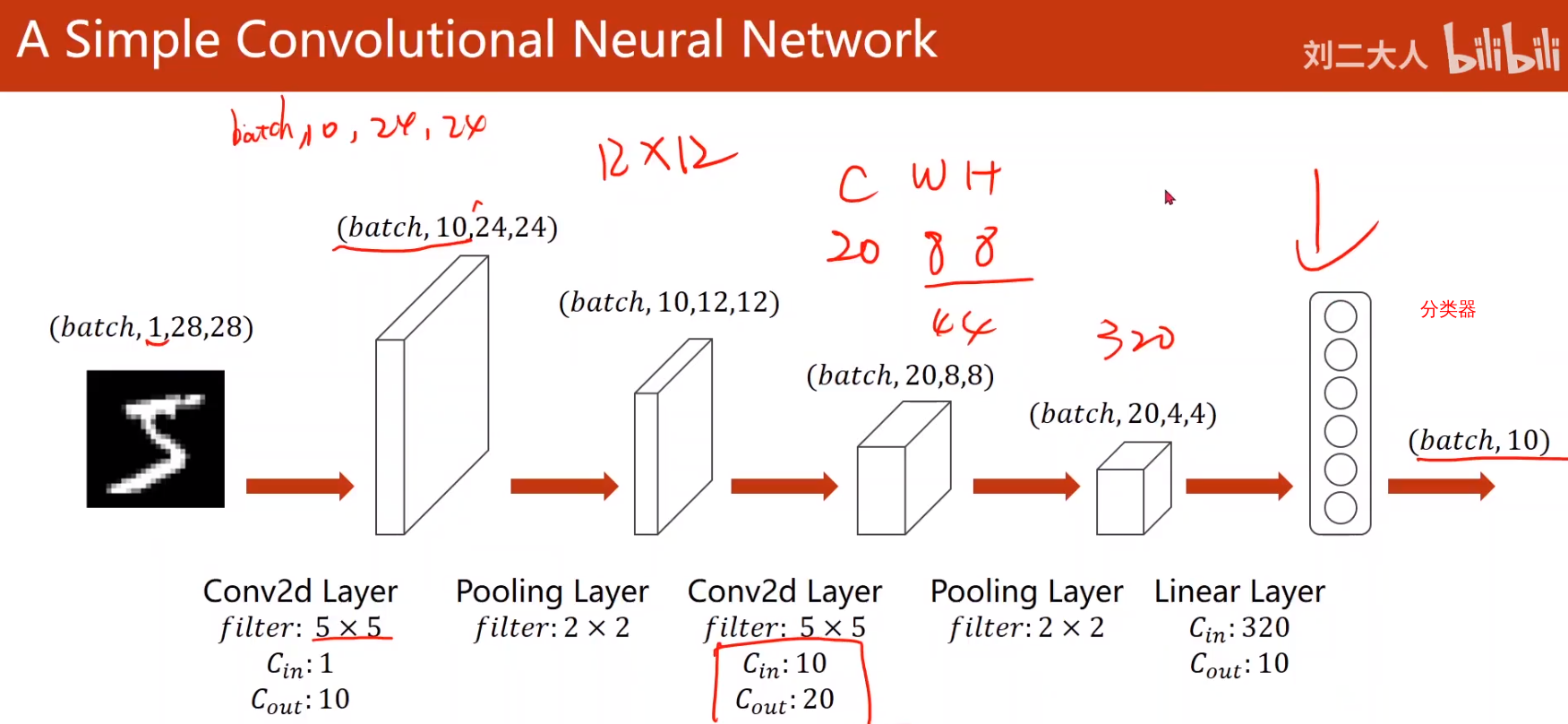
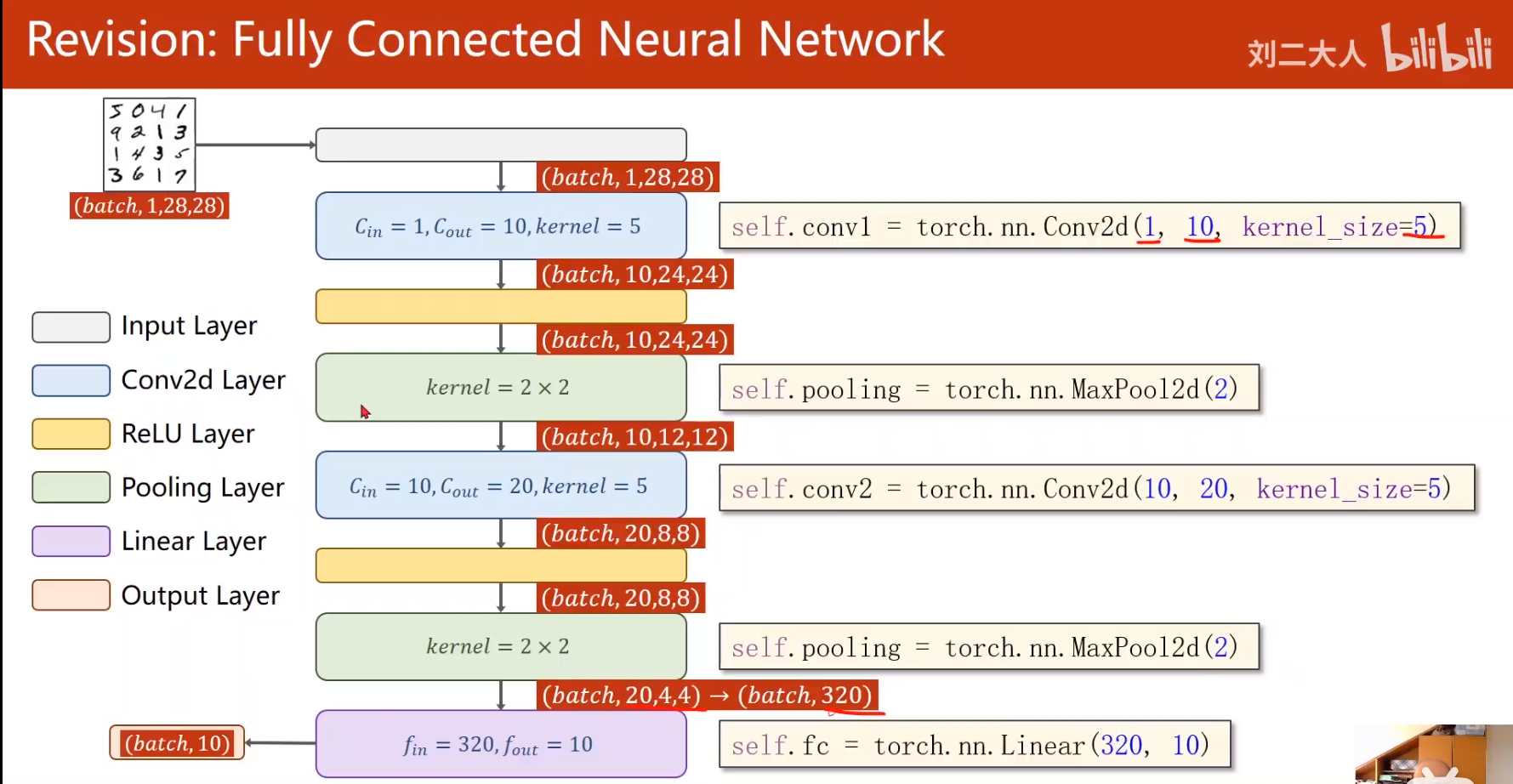
- 全连接神经网络
迁移GPU
- 指定device

- 迁移输入:

- 梯度消失
梯度趋近于0,权重无法得到有效更新
- 对于很复杂的网络,我们可以用新的类去封装它
- 如果有不同的运行分支,我们可以用cat拼接它
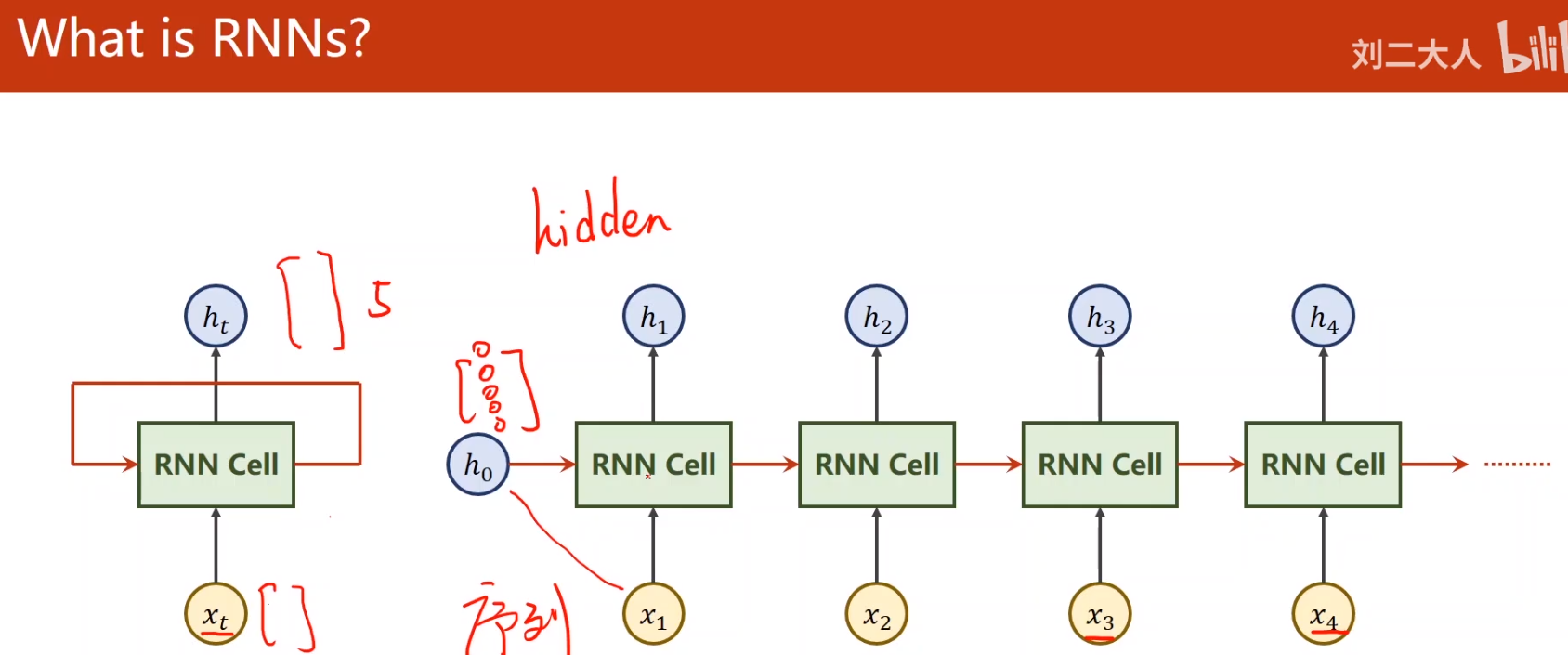
- 常常用于处理具有序列关系的问题
天气预测
自然语言
- what ‘s RNN