


Nextflow pipeline for somatic variant calling with mutect with Mutect1 or 2, gatk3 or gatk4
- Nextflow: for common installation procedures see the IARC-nf repository.
- Mutect and its dependencies (Java 1.7 and Maven 3.0+), or gatk4 that now includes Mutect2
- bedtools and move the executable file in your path.
- python and package pysam
- bedops
A conda receipe, and docker and singularity containers are available with all the tools needed to run the pipeline (see "Usage")
With GATK4, a list of known_snps can be provided to mutect2 to improve the variant classification, for example file af-only-gnomad.hg38.vcf.gz from the bundle best practices from the broad institute GATK somatic calling bundle.
When the estimate contamination mode is chosen, one needs to provide a list of known snps; we recommend the file small_exac_common_3.hg38.vcf.gz from the best practices broad institute bundle.
| Type | Description |
|---|---|
| --tumor_bam_folder | a folder with tumor bam files |
| --normal_bam_folder | a folder with normal bam files |
| --tn_file | input tabulation-separated values file with columns sample (sample name), tumor (full path to tumor bam), normal (full path to matched normal bam); optionally (for --genotype mode), columns preproc (is the bam RNAseq needing preprocessing: yes or no) and vcf (full path to vcf file containing alleles to genotype) |
Note that there are two input methods: separate tumor_bam_folder and normal_bam_folder, and tn_file.
The method assumes that normal and tumor bam files are in these respective folder, and uses parameters suffix_tumor and suffix_normal to detect them (the rest of the file name needs to be identical.
The tumor bam file format must be (sample suffix_tumor .bam) with suffix_tumor as _T by default and customizable in input (--suffix_tumor). (e.g. sample1_T.bam)
The normal bam file format must be (sample suffix_normal .bam) with suffix_normal as _N by default and customizable in input (--suffix_normal). (e.g. sample1_N.bam).
BAI indexes have to be present in the same location than their BAM mates, with the extension bam.bai.
The method uses a tabulation-separated values format file with columns sample, tumor, and normal (in any order); it does not use parameters suffix_tumor and suffix_normal and does not require file names to match. When the genotype mode is active, additional columns are expected: preproc, specifying if preprocessing of RNA-seq bam file is required (yes or no) and vcf, indicating the location of the vcf file containing the alleles to genotype. preproc includes splitting spanning reads, correcting CIGAR string with NDN pattern, and changing mapping quality of uniquely mapped reads from 255 to 60(gatk4's splitNCigarReads and a custom python script). The tn_file method is necessary for joint multi-sample calling, in which case the sample name is used to group files, and to specify preprocessing of some RNA-seq samples.
BAI indexes have to be present in the same location than their BAM mates, with the extension bam.bai.
| Name | Example value | Description |
|---|---|---|
| --ref | ref.fa | reference genome fasta file |
| Name | Default value | Description |
|---|---|---|
| --cpu | 4 | number of CPUs |
| --mem | 8 | memory for mapping |
| --suffix_tumor | _T | suffix for tumor file |
| --suffix_normal | _N | suffix for matched normal file |
| --output_folder | mutect_results | output folder for aligned BAMs |
| --bed | Bed file containing intervals | |
| --region | A region defining the calling, in the format CHR:START-END | |
| --known_snp | VCF file with known variants and frequency (e.g., from gnomad) | |
| --mutect_args | Arguments you want to pass to mutect. WARNING: form is " --force_alleles " with spaces between quotes | |
| --nsplit | 1 | Split the region for calling in nsplit pieces and run in parallel |
| --java | java | Name of the JAVA command |
| --snp_contam | VCF file with known germline variants to genotype for contamination estimation (requires --estimate_contamination) | |
| --PON | path to panel of normal VCF file used to filter calls | |
| --gatk_version | 4 | gatk version |
| --ref_RNA | fasta reference for preprocessing RNA (required when preproc column contains yes in input tn_file) |
NOTE: if neither --bed or --region, will perform the calling on whole genome, based on the faidx file.
These options are not needed if gatk4 is used
| Name | Default value | Description |
|---|---|---|
| --cosmic | Cosmic VCF file required by mutect; not in gatk4 | |
| --mutect_jar | path to jar file of mutect1 | |
| --mutect2_jar | path to jar file of mutect2 |
| Name | Description |
|---|---|
| --help | print usage and optional parameters |
| --estimate_contamination | run extra step of estimating contamination by normal and using the results to filter calls; only for gatk4 |
| --genotype | use genotyping from vcf mode instead of usual variant calling requires tn_file with vcf column and gatk4, and if RNA-seq included, requires preproc column |
| --filter_readorientation | Run extra step learning read orientation model and using it to filter reads |
To run the pipeline on a series of matched tumor normal files (with suffixes _T and _N) in folders tumor_BAM normal_BAM, a reference genome with indexes ref, and a bed file ref.bed, one can type:
nextflow run IARCbioinfo/mutect-nf -r v2.2b -profile singularity --tumor_bam_folder tumor_BAM/ --normal_bam_folder normal_BAM/ --ref ref_genome.fa --gtf ref.gtf To run the pipeline without singularity just remove "-profile singularity". Alternatively, one can run the pipeline using a docker container (-profile docker) the conda receipe containing all required dependencies (-profile conda). Note that we provide similar support when using gatk3 (profiles conda_gatk3, singularity_gatk3, and docker_gatk3) or gatk2 (profiles conda_gatk2, singularity_gatk2, and docker_gatk2).
To use gatk3, set --gatk_version 3and provide option --mutect2_jar for mutect version 2 (GATK executable jar, which integrate mutect2) and possibly specify -profile singularity_gatk3, and set --mutect_jar for mutect version 1 and possibly specify -profile singularity_gatk2.
You can print the help manual by providing --help in the execution command line:
nextflow run iarcbioinfo/mutect-nf --helpThis shows details about optional and mandatory parameters provided by the user.
| Type | Description |
|---|---|
| sample.vcf.gz and sample.vcf.gz.tbi | filtered VCF files and their indexes |
| stats/ | gatk stats files from mutect |
| intermediate_calls/raw_calls/sample.vcf | unfiltered VCF files |
The output_folder directory contains two subfolders: stats and intermediate_calls
Outputs are based on the SM field of the BAM file; when multiple files have the same SM, only one is outputed.
Check that the input is tab-separated. When parsing the input file, if a line is not tab separated, nextflow will ignore it without returning an error.
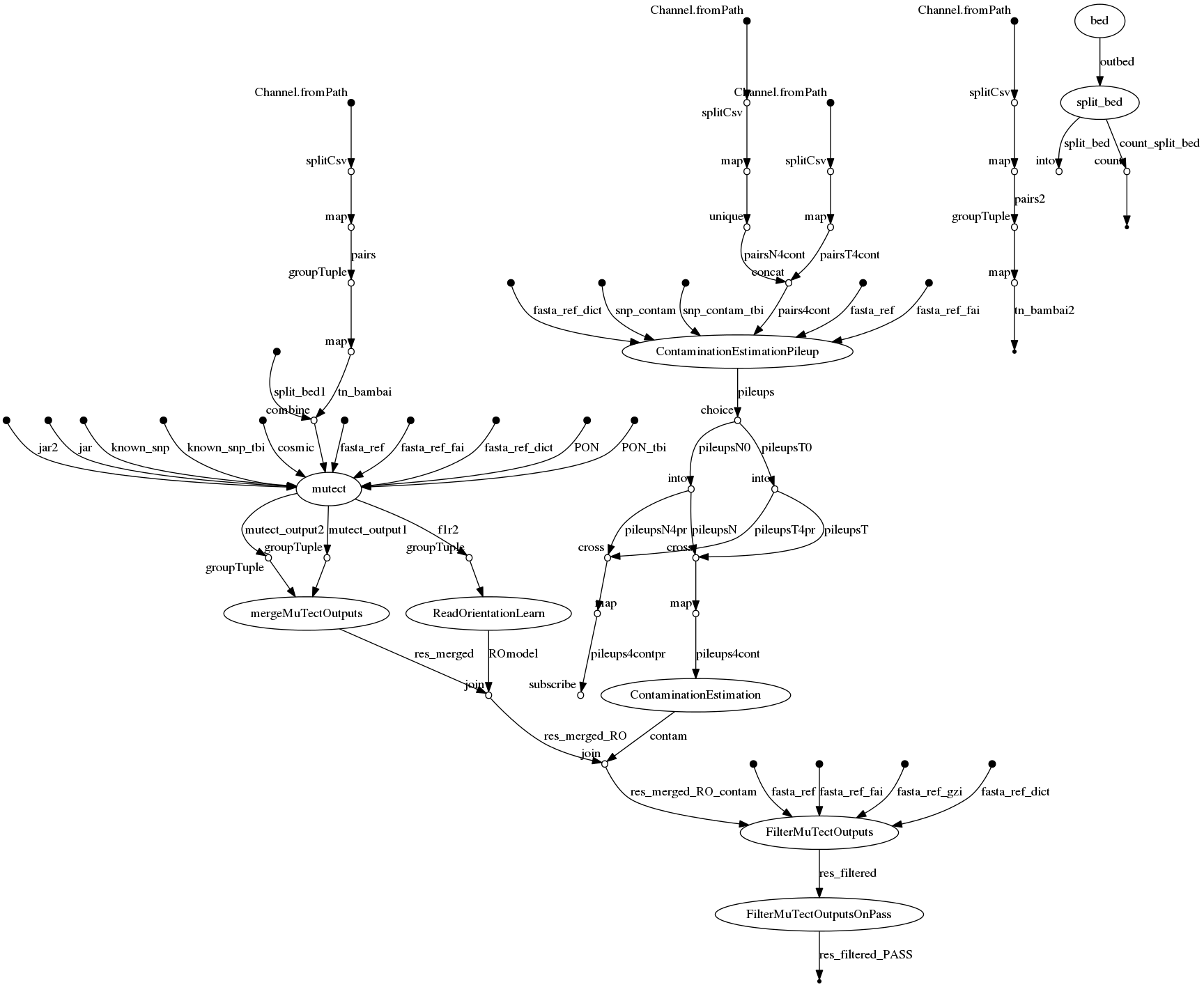
| Name | Description | |
|---|---|---|
| Nicolas Alcala* | AlcalaN@iarc.fr | Developer to contact for support |
| Tiffany Delhomme | Developer |