Code for paper Document-Level Paraphrase Generation with Sentence Rewriting and Reordering by Zhe Lin, Yitao Cai and Xiaojun Wan. This paper is accepted by Findings of EMNLP'21.
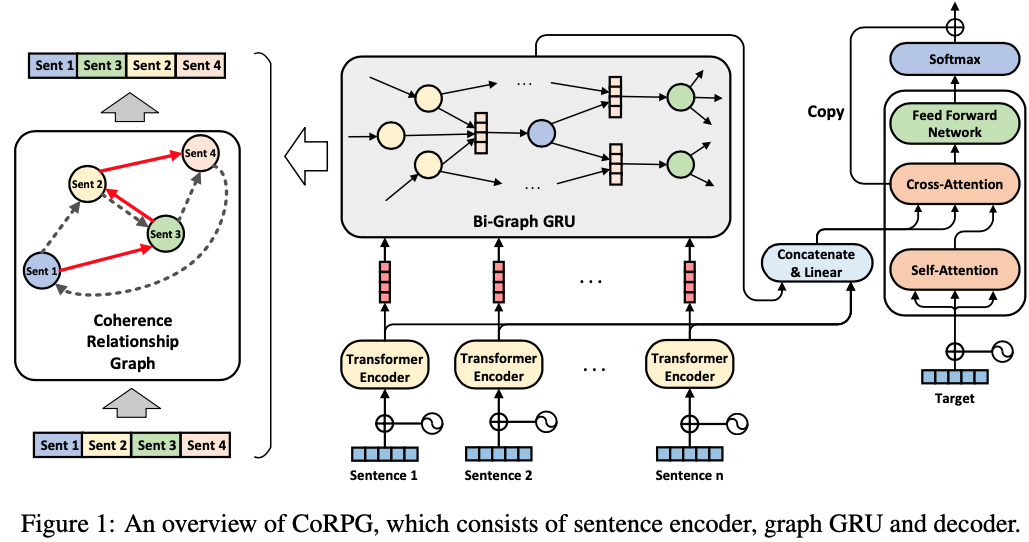
We leverage ParaNMT to train a sentence-level paraphrasing model. We select News-Commentary as document corpora, and we employ sentence-level paraphrasing model to generate a pseudo document-level paraphrase and use ALBERT to generate its coherence relationship graph. All these data are released at here.
If you are looking for system output and don't bother to install dependencies and train a model (or run a pre-trained model), the all-system-output folder is for you.
PyTorch >= 1.4
Transformers == 4.1.1
nltk == 3.5
tqdm
torch_optimizer == 0.1.0
We release the dataset we used in data folder. If you want to use your own dataset, you need to follow the following procedure.
First, you should train a sentence-level paraphrase model to generate pseudo documen paraphrase dataset (We leverage paraNMT and fairseq to train this model).
Then, you should download the ALBERT model and fine-tuning it with your own dataset with the following script:
python eval/coherence.py --train
--pretrain_model [pretrain_model file]
--save_file [the path to save fine-tune model]
--text_file [the corpora used to fine-tune the pretrain_model] We also provide our fine-tune model in here.
Finally, you can leveraged ALBERT to generate the coherence relationship graph:
python eval/coherence.py --inference
--pretrain_model [pretrain_model file]
--text_file [generate the coherence relationship graph of this corpora]NOTE: Our code only supports to generate the paraphrasing of documents with 5 sentences. If you want to generate longer or variable length document paraphrase, you need to make some modifications to the code.
Create Vocabulary:
python createVocab.py --file ./data/news-commentary/data/bpe/train.split.bpe \
./data/news-commentary/data/bpe/train.pesu.split.bpe\
--save_path ./data/vocab.shareProcessing Training Dataset:
python preprocess.py --source ./data/news-commentary/data/bpe/train.pesu.comb.bpe \
--graph ./data/news-commentary/data/train.pesu.graph \
--target ./data/news-commentary/data/bpe/train.comb.bpe \
--vocab ./data/vocab.share \
--save_file ./data/para.pairProcessing Test Dataset:
python preprocess.py --source ./data/news-commentary/data/bpe/test.comb.bpe \
--graph ./data/news-commentary/data/test.graph \
--vocab ./data/vocab.share \
--save_file ./data/sent.ptpython train.py --cuda_num 0 1 2 3\
--vocab ./data/vocab.share\
--train_file ./data/para.pair\
--checkpoint_path ./data/model \
--batch_print_info 200 \
--grad_accum 1 \
--graph_eps 0.5 \
--max_tokens 5000python generator.py --cuda_num 4 \
--file ./data/sent.pt\
--ref_file ./data/news-commentary/data/test.comb \
--max_tokens 10000 \
--vocab ./data/vocab.share \
--decode_method greedy \
--beam 5 \
--model_path ./data/model.pkl \
--output_path ./data/output \
--max_length 300We release our pretrained model at here.
We evaluate our model in three aspects: relevancy, diversity, coherence.
We leverage BERTScore to evaluate the semantic relevancy between paraphrase and original sentence.
We employ self-TER and self-WER to evaluate the diversity of our model.
We raise COH and COH-p to evaluate the coherence of paraphrase as follows:

where
python eval/coherence.py --coh
--pretrain_model [the pretrain albert file]
--text_file [the corpora to be evaluated]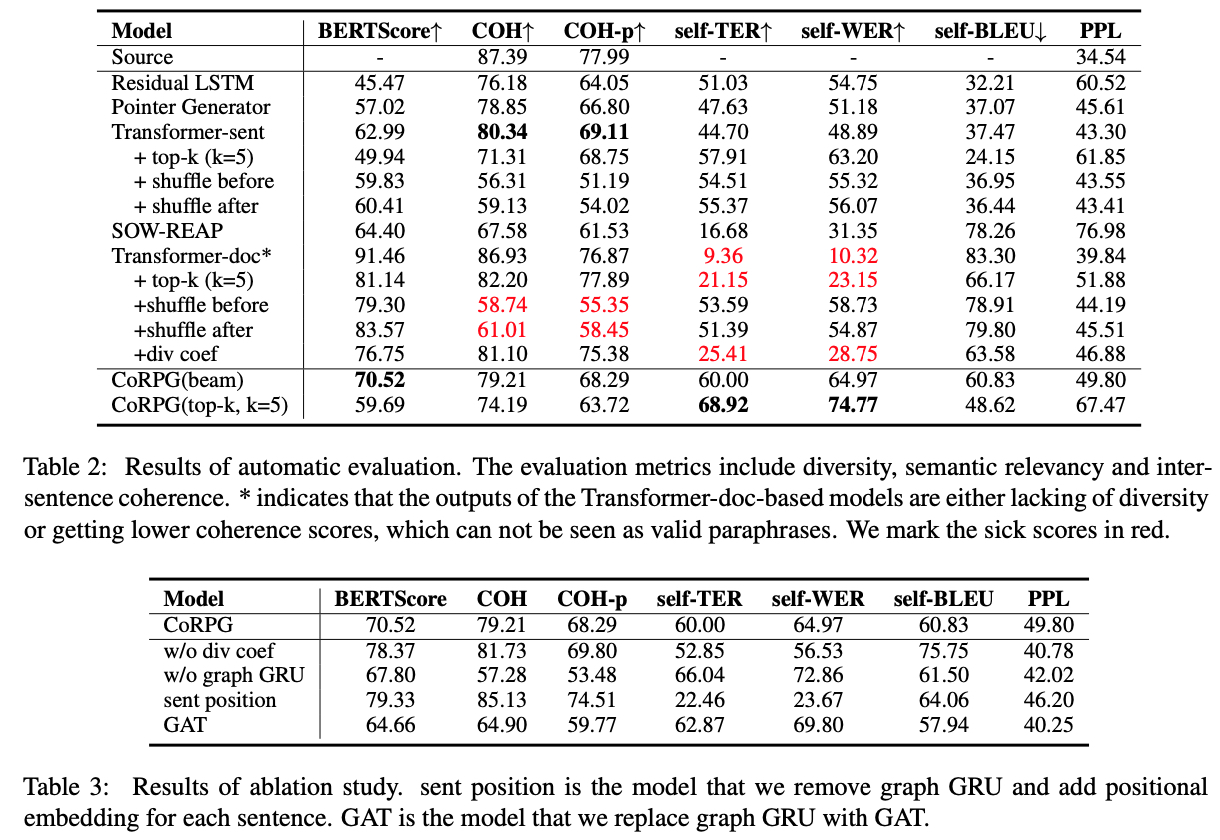
If you use any content of this repo for your work, please cite the following bib entry:
@inproceedings{lin-wan-2021-document,
title = "Document-Level Paraphrase Generation with Sentence Rewriting and Reordering",
author = "Lin, Zhe and Cai, Yitao and Wan, Xiaojun",
booktitle = "Findings of EMNLP",
year={2021}
}