NVIDIA-accelerated DNN model inference ROS 2 packages using NVIDIA Triton/TensorRT for both Jetson and x86_64 with CUDA-capable GPU.


Learn how to use this package by watching our on-demand webinar: Accelerate YOLOv5 and Custom AI Models in ROS with NVIDIA Isaac
Isaac ROS DNN Inference contains ROS 2 packages for performing DNN inference, providing AI-based perception for robotics applications. DNN inference uses a pre-trained DNN model to ingest an input Tensor and output a prediction to an output Tensor.
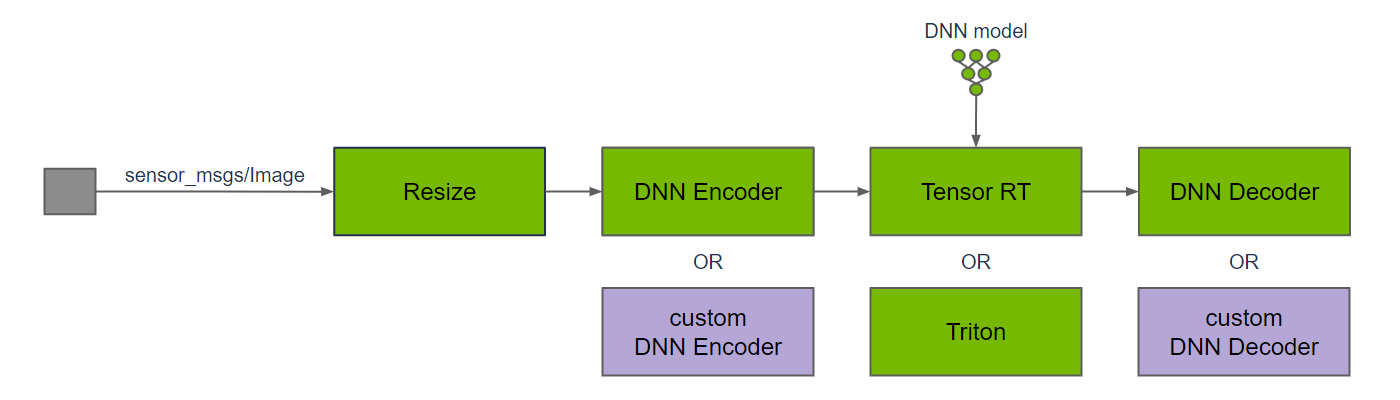
Above is a typical graph of nodes for DNN inference on image data. The input image is resized to match the input resolution of the DNN; the image resolution may be reduced to improve DNN inference performance ,which typically scales directly with the number of pixels in the image. DNN inference requires input Tensors, so a DNN encoder node is used to convert from an input image to Tensors, including any data pre-processing that is required for the DNN model. Once DNN inference is performed, the DNN decoder node is used to convert the output Tensors to results that can be used by the application.
TensorRT and Triton are two separate ROS nodes to perform DNN inference. The TensorRT node uses TensorRT to provide high-performance deep learning inference. TensorRT optimizes the DNN model for inference on the target hardware, including Jetson and discrete GPUs. It also supports specific operations that are commonly used by DNN models. For newer or bespoke DNN models, TensorRT may not support inference on the model. For these models, use the Triton node.
The Triton node uses the Triton Inference Server, which provides a compatible frontend supporting a combination of different inference backends (e.g. ONNX Runtime, TensorRT Engine Plan, TensorFlow, PyTorch). In-house benchmark results measure little difference between using TensorRT directly or configuring Triton to use TensorRT as a backend.
Some DNN models may require custom DNN encoders to convert the input data to the Tensor format needed for the model, and custom DNN decoders to convert from output Tensors into results that can be used in the application. Leverage the DNN encoder and DNN decoder node(s) for image bounding box detection and image segmentation, or your own custom node(s).
Note
DNN inference can be performed on different types of input data, including audio, video, text, and various sensor data, such as LIDAR, camera, and RADAR. This package provides implementations for DNN encode and DNN decode functions for images, which are commonly used for perception in robotics. The DNNs operate on Tensors for their input, output, and internal transformations, so the input image needs to be converted to a Tensor for DNN inferencing.
This package is powered by NVIDIA Isaac Transport for ROS (NITROS), which leverages type adaptation and negotiation to optimize message formats and dramatically accelerate communication between participating nodes.
| Sample Graph |
Input Size |
AGX Orin |
Orin NX |
Orin Nano Super 8GB |
x86_64 w/ RTX 4090 |
|---|---|---|---|---|---|
| TensorRT Node DOPE |
VGA |
30.8 fps 37 ms @ 30Hz |
15.5 fps 55 ms @ 30Hz |
20.8 fps 51 ms @ 30Hz |
298 fps 5.3 ms @ 30Hz |
| Triton Node DOPE |
VGA |
31.2 fps 340 ms @ 30Hz |
15.5 fps 55 ms @ 30Hz |
22.2 fps 490 ms @ 30Hz |
277 fps 4.7 ms @ 30Hz |
| TensorRT Node PeopleSemSegNet |
544p |
489 fps 4.6 ms @ 30Hz |
258 fps 7.1 ms @ 30Hz |
269 fps 6.2 ms @ 30Hz |
619 fps 2.2 ms @ 30Hz |
| Triton Node PeopleSemSegNet |
544p |
216 fps 5.5 ms @ 30Hz |
143 fps 8.2 ms @ 30Hz |
– |
585 fps 2.5 ms @ 30Hz |
| DNN Image Encoder Node |
VGA |
339 fps 13 ms @ 30Hz |
375 fps 12 ms @ 30Hz |
– |
480 fps 6.0 ms @ 30Hz |
Please visit the Isaac ROS Documentation to learn how to use this repository.
Update 2024-12-10: Update to be compatible with JetPack 6.1