![]()


The International Personality Item Pool (IPIP) is a public domain collection of items for use in personality tests. It is managed by the Oregon Research Institute.
This project assesses a person's personality based on an inventory of questions. The project uses the Big Five theory using the IPIP-NEO-300 model created by Lewis R. Goldberg and IPIP-NEO-120 the shorter version developed by Professor Dr. John A. Johnson, this is a free representation of the NEO PI-R™.
👉 "The IPIP-NEO is not identical to the original NEO PI-R, but in my opinion it is close enough to serve as a good substitute. More and more people are beginning to use it in published research, so its acceptance is growing." - Dr. Johnson
The main idea of the project is to facilitate the use of Python developers who want to use IPIP-NEO in their projects. The project is also done in pure Python, it doesn't have any dependencies on other libraries.
👉 "That is wonderful, ...! Thank you for developing the Python version of the IPIP-NEO and making it publicly available. It looks like a great resource." - Dr. Johnson
Note 🚩: The project is based on the work of Dhiru Kholia, and is an adaptation of NeuroQuestAI for a version that can be reused in other projects of the company.
A little theory, The Big Five or Five Factor is made up of 5 great human personalities also known as the 🌊 O.C.E.A.N. Are they:
- Openness
- Conscientiousness
- Extraversion
- Agreeableness
- Neuroticism
To compose each great personality there are 6 traits or facets, totaling 30 traits. The user must answer a questionnaire of 120 or 300 single choice questions with 5 options:
- Very Inaccurate
- Moderately Inaccurate
- Neither Accurate Nor Inaccurate
- Moderately Accurate
- Very Accurate
For more information to demystify the Big Five, please see the article: Measuring the Big Five Personality Domains.
User-selected answers follow the position:
| Option | Array |
|---|---|
| Very Inaccurate | 1 |
| Moderately Inaccurate | 2 |
| Neither Accurate Nor Inaccurate | 3 |
| Moderately Accurate | 4 |
| Very Accurate | 5 |
Note 🚩: Some answers have the order of the score reversed, the algorithm treats the questions with the score inverted by (question_id).
News about each version please look here:
From PyPI:
python3 -m pip install --upgrade five-factor-eFrom source:
git clone https://github.com/NeuroQuestAi/five-factor-e.git ; cd five-factor-e
python3 -m pip install .or Poetry:
git clone https://github.com/NeuroQuestAi/five-factor-e.git ; cd five-factor-e
poetry shell && poetry installThe construtor requires the questions model, whether it is the 300 model or short model with 120 questions. It also has the version to do simulations with the questions that are reversed. For this, you must turn the test variable from false to true, for more details on reverse scoring tests see section Experiments with reverse scoring questions.
| Parameters | Type | Description |
|---|---|---|
| question | int | Question type, 120 or 300. |
| test | boolean | Used to simulate reverse scoring questions, only used for studies. |
Example:
from ipipneo import IpipNeo
ipip = IpipNeo(question=120)The 120 item version is a short version of the inventory, but you can use the full 300 item version. Example:
from ipipneo import IpipNeo
ipip = IpipNeo(question=300)The answers must be in a standardized json, you can insert this template in the data folder of the project. This dictionary contains random answers, used for testing purposes only. As an example, you can load the file with the 120 test responses:
import json, urllib.request
data = urllib.request.urlopen("https://raw.githubusercontent.com/NeuroQuestAi"\
"/five-factor-e/main/data/IPIP-NEO/120/answers.json").read()
answers120 = json.loads(data)For the long inventory version with 300 items.
import json, urllib.request
data = urllib.request.urlopen("https://raw.githubusercontent.com/NeuroQuestAi"\
"/five-factor-e/main/data/IPIP-NEO/300/answers.json").read()
answers300 = json.loads(data)The compute method is used to evaluate the answers, see the table below with the parameters:
| Parameters | Type | Description |
|---|---|---|
| sex | string | Sex assigned at birth (M or F). |
| age | int | Age (in years between 10 and 110 years old). |
| answers | dict | Standardized dictionary with answers. |
| compare | boolean | If true, it shows the user's answers and reverse score. |
Calculate the Big Five for a 40-year-old man:
IpipNeo(question=120).compute(sex="M", age=40, answers=answers120)For the long version of the inventory just change the parameters question to 300.
IpipNeo(question=300).compute(sex="M", age=40, answers=answers300)Calculating the Big Five for a 25-year-old woman:
IpipNeo(question=120).compute(sex="F", age=25, answers=answers120)An example of the output of the results:
{
"personalities":[
{
"openness":{
"O":24.29091080263288,
"score": "low",
"traits":[
{
"trait":1,
"imagination":21.43945888481437,
"score":"low"
},
{
"trait":2,
"artistic_interests":4.344187760272675,
"score":"low"
},
{
"trait":3,
"emotionality":8.379530297432893,
"score":"low"
},
{
"trait":4,
"adventurousness":30.805235884673323,
"score":"low"
},
{
"trait":5,
"intellect":47.84680512022845,
"score":"average"
},
{
"trait":6,
"liberalism":84.95164346200181,
"score":"high"
}
]
}
}
]
}Example of the complete output check here: Big 5️⃣ Output
For the tests it is necessary to download the repository. To run the unit tests use the command below:
$ ./run-testIf you want to make an assessment by answering the inventory of questions, just run:
$ ipipneo-quizIn this program you take an assessment for the short version with 120 items as well as the 300 item version, just follow the program's instructions. It is possible to see the basic graphs of your Big-Five via terminal, if you want to see the graphs at the end of the questionnaires you need to run the installation command:
$ pip install five-factor-e[quiz]Example output with graphics:
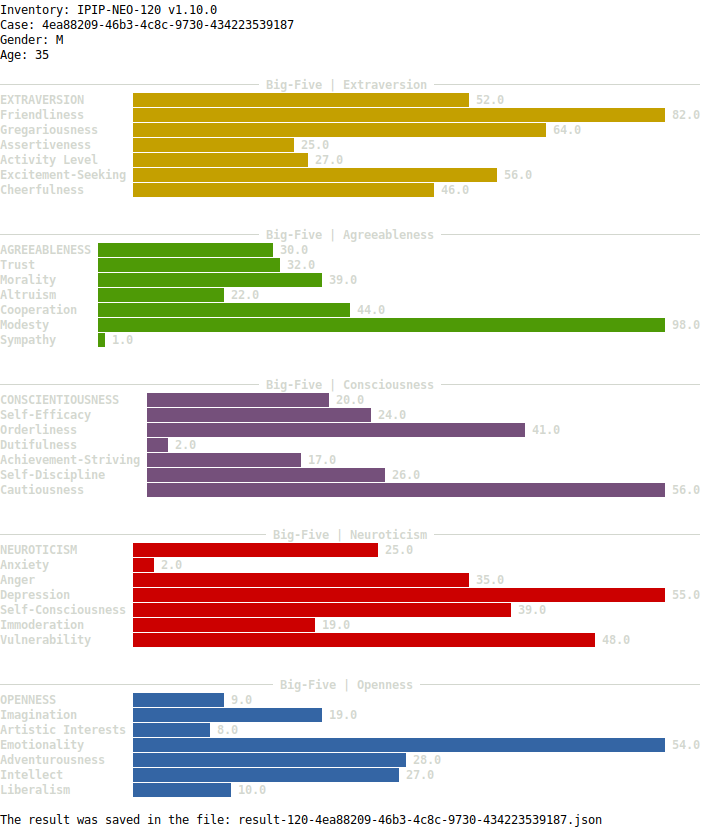
The complete result is saved in the run folder in json format.
Inside the data data directory, there are examples of questions and answers. The most important is the response data entry which must follow the pattern of this file. Example:
{
"answers":[
{
"id_question":50,
"id_select":5
},
{
"id_question":51,
"id_select":2
}
]
}The id question field refers to the question in this file. Obviously if you want you can change the translation of the question, but don't change the ID of the question.
Note 🚩:
- The order of answers does not affect the result;
- You can rephrase the questions to your need, but don't change the question IDs, they are used by the algorithm.
- Dr John A. Johnson
- Dhiru Kholia
- Chris Hunt