Paper: https://arxiv.org/pdf/2002.08945.pdf
@inproceeding{liu2020spatiotemporal,
title={Spatiotemporal Relationship Reasoning for Pedestrian Intent Prediction},
author={Bingbin Liu and Ehsan Adeli and Zhangjie Cao and Kuan-Hui Lee and Abhijeet Shenoi and Adrien Gaidon and Juan Carlos Niebles},
year={2020},
booktitle={IEEE Robotics and Automation Letters (IEEE RA-L) and International Conference on Robotics and Automation (ICRA)},
publisher={IEEE}
}
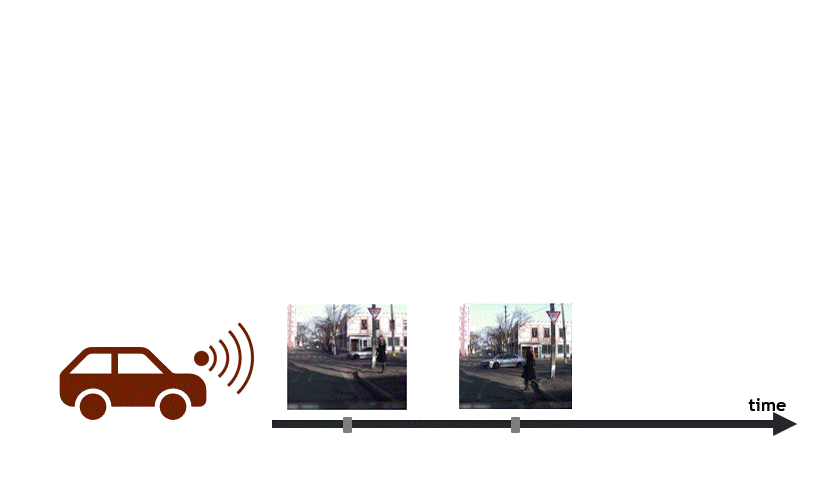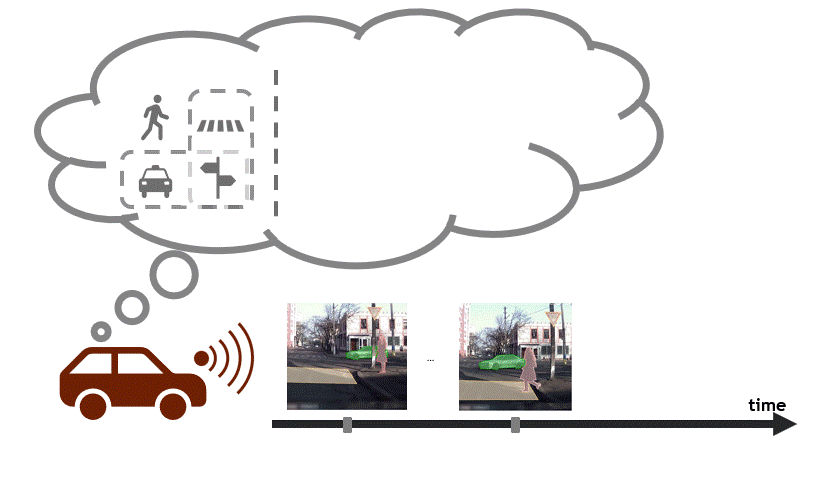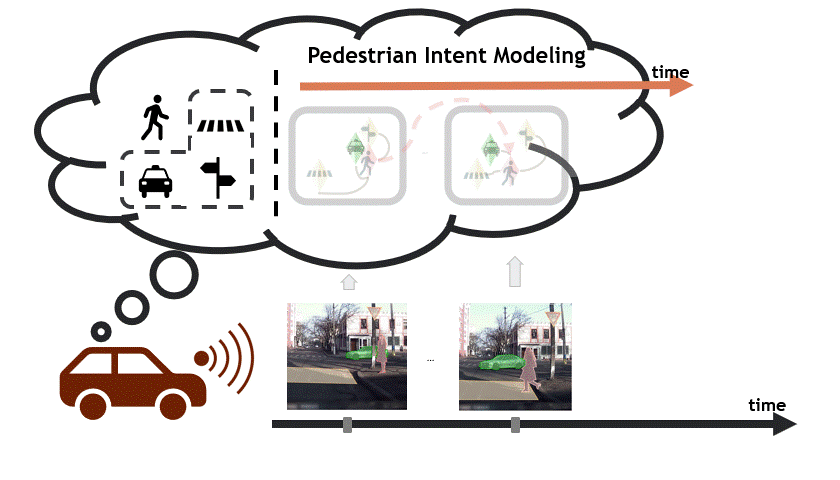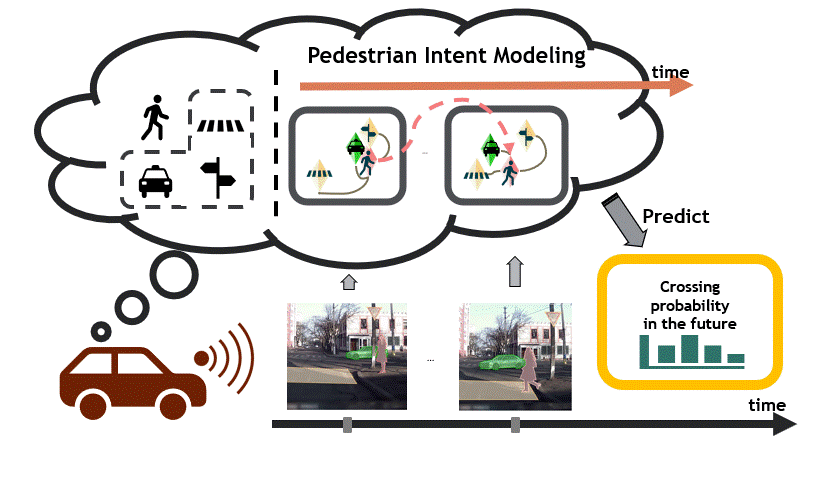
Reasoning over visual data is a desirable capability for robotics and vision-based applications. Such reasoning enables forecasting the next events or actions in videos. In recent years, various models have been developed based on convolution operations for prediction or forecasting, but they lack the ability to reason over spatiotemporal data and infer the relationships of different objects in the scene. In this paper, we present a framework based on graph convolution to uncover the spatiotemporal relationships in the scene for reasoning about pedestrian intent. A scene graph is built on top of segmented object instances within and across video frames. Pedestrian intent, defined as the future action of crossing or not-crossing the street, is very crucial piece of information for autonomous vehicles to navigate safely and more smoothly. We approach the problem of intent prediction from two different perspectives and anticipate the intention-to-cross within both pedestrian-centric and location-centric scenarios. In addition, we introduce a new dataset designed specifically for autonomousdriving scenarios in areas with dense pedestrian populations: the Stanford-TRI Intent Prediction (STIP) dataset. Our experiments on STIP and another benchmark dataset show that our graph modeling framework is able to predict the intention-to-cross of the pedestrians with an accuracy of 79.10% on STIP and 79.28% on Joint Attention for Autonomous Driving (JAAD) dataset up to one second earlier than when the actual crossing happens. These results outperform baseline and previous work. Please refer to https://stip.stanford.edu for the dataset and code.

STIP includes over 900 hours of driving scene videos of front, right, and left cameras, while the vehicle was driving in dense areas of five cities in the United States. The videos were annotated at 2fps with pedestrian bounding boxes and labels of crossing/not-crossing the street, which are respectively shown with green/red boxes in the above videos. We used the JRMOT (JackRabbot real-time Multi-Object Tracker) platform to track the pedestrian and interpolate the annotations for all 20 frame per second.
Dataset Code: https://github.com/StanfordVL/STIP
Dataset Information: https://stip.stanford.edu/dataset.html
Request Access to Dataset: here
JAAD is a dataset for studying joint attention in the context of autonomous driving. The focus is on pedestrian and driver behaviors at the point of crossing and factors that influence them. To this end, JAAD dataset provides a richly annotated collection of 346 short video clips (5-10 sec long) extracted from over 240 hours of driving footage. Bounding boxes with occlusion tags are provided for all pedestrians making this dataset suitable for pedestrian detection. Behavior annotations specify behaviors for pedestrians that interact with or require attention of the driver. For each video there are several tags (weather, locations, etc.) and timestamped behavior labels from a fixed list (e.g. stopped, walking, looking, etc.). In addition, a list of demographic attributes is provided for each pedestrian (e.g. age, gender, direction of motion, etc.) as well as a list of visible traffic scene elements (e.g. stop sign, traffic signal, etc.) for each frame.
Annotation Data: https://github.com/ykotseruba/JAAD
Full Dataset: http://data.nvision2.eecs.yorku.ca/JAAD_dataset
This training code is setup to be ran on a 16GB GPU. You may have to make some adjustments if you do not have this hardware available.
conda create --name crossing python=3.7
conda activate crossing
pip install torchvision==0.5.0
pip install opencv-python
pip install pycocotools
pip install pickle
pip install numpy
pip install wandb
export PYTHONPATH=$PYTHONPATH:[path-to-repo]
git clone https://github.com/StanfordVL/STR-PIP.git
cd STR-PIP
Running "scripts_dir/train_concat.sh"
In order to generate "annot_test_ped_withTag_sanityNoPose.pkl", you will need to run utils/data_proc.py. Specifically, we will run the function prepare_data() inside data_proc.py.
- With the correct pre-processing, STIP training/testing works.
- We are looking for some specific artifacts to train on JAAD. We are very close to generating the correct files.
- This code base is in the process of clean-up, doc, and re-factor. There may be sudden changes. We will publish a new release when it is a more ready state.