


Welcome to the 2022 AI2-THOR Rearrangement Challenge hosted at the CVPR'22 Embodied-AI Workshop. The goal of this challenge is to build a model/agent that move objects in a room to restore them to a given initial configuration. Please follow the instructions below to get started.
If you have any questions please file an issue
or post in the #rearrangement-challenge channel on our Ask PRIOR slack.
- 🔥🆕🔥 What's New in the 2022 Challenge?
- 💻 Installation
- 📝 Rearrangement Task Description
- 🛤️ Challenge Tracks and Datasets
- 🛤️ Submitting to the Leaderboard
- 🖼️ Allowed Observations
- 🏃 Allowed Actions
- 🍽️ Setting up Rearrangement
- 📄 Citation
Our 2022 AI2-THOR Rearrangement Challenge has several upgrades distinguishing it from the 2021 version:
- New AI2-THOR version. We've upgraded the version of AI2-THOR we're using from 2.1.0 to 4.2.0, this brings:
- Performance improvements
- The ability to use (the recently announced) headless rendering feature, see here this makes it much easier to run AI2-THOR on shared servers where you may not have the admin privileges to start an X-server.
- New dataset. We've released a new rearrangement dataset to match the new AI2-THOR version. This new dataset has a more uniform balance of easy/hard episodes.
- Misc. improvements. We've fixed a number of minor bugs and performance issues from the 2021 challenge improving consistency.
To begin, clone this repository locally
git clone git@github.com:allenai/ai2thor-rearrangement.gitSee here for a summary of the most important files/directories in this repository
Here's a quick summary of the most important files/directories in this repository:
example.pyan example script showing how rearrangement tasks can be instantiated for training and validation.baseline_configs/rearrange_base.pyThe base configuration file which defines the challenge parameters (e.g. screen size, allowed actions, etc).one_phase/*.py- Baseline experiment configurations for the 1-phase challenge track.two_phase/*.py- Baseline experiment configurations for the 2-phase challenge track.walkthrough/*.py- Baseline experiment configurations if one wants to train the walkthrough phase in isolation.
rearrange/baseline_models.py- A collection of baseline models for the 1- and 2-phase challenge tasks. These Actor-Critic models use a CNN->RNN architecture and can be trained using the experiment configs under thebaseline_configs/[one/two]_phase/directories.constants.py- Constants used to define the rearrangement task. These include the step size taken by the agent, the unique id of the the THOR build we use, etc.environment.py- The definition of theRearrangeTHOREnvironmentclass that wraps the AI2-THOR environment and enables setting up rearrangement tasks.expert.py- The definition of a heuristic expert (GreedyUnshuffleExpert) which uses privileged information (e.g. the scene graph & knowledge of exact object poses) to solve the rearrangement task. This heuristic expert is meant to be used to produce expert actions for use with imitation learning techinques. See thequery_expertmethod within therearrange.tasks.UnshuffleTaskclass for an example of how such an action can be generated.losses.py- Losses (outside of those provided by AllenAct by default) used to train our baseline agents.sensors.py- Sensors which provide observations to our agents during training. E.g. theRGBRearrangeSensorobtains RGB images from the environment and returns them for use by the agent.tasks.py- Definitions of theUnshuffleTask,WalkthroughTask, andRearrangeTaskSamplerclasses. For more information on how these are used, see the Setting up Rearrangement section.utils.py- Standalone utility functions (e.g. computing IoU between 3D bounding boxes).
You can then install requirements by running
pip install -r requirements.txtor, if you prefer using conda, we can create a thor-rearrange environment with our requirements by running
export MY_ENV_NAME=thor-rearrange
export CONDA_BASE="$(dirname $(dirname "${CONDA_EXE}"))"
export PIP_SRC="${CONDA_BASE}/envs/${MY_ENV_NAME}/pipsrc"
conda env create --file environment.yml --name $MY_ENV_NAME Why not just run conda env create --file environment.yml --name thor-rearrange by itself?
If you were to run conda env create --file environment.yml --name thor-rearrange nothing would break
but we have some pip requirements in our environment.yml file and, by default, these are saved in
a local ./src directory. By explicitly specifying the PIP_SRC variable we can have it place these
pip-installed packages in a nicer (more hidden) location.
Python 3.6+ 🐍. Each of the actions supports typing within Python.
AI2-THOR 4.2.0 🧞. To ensure reproducible results, we're restricting all users to use the exact same version of AI2-THOR.
AllenAct 🏋💪. We ues the AllenAct reinforcement learning framework for generating baseline models, baseline training pipelines, and for several of their helpful abstractions/utilities.

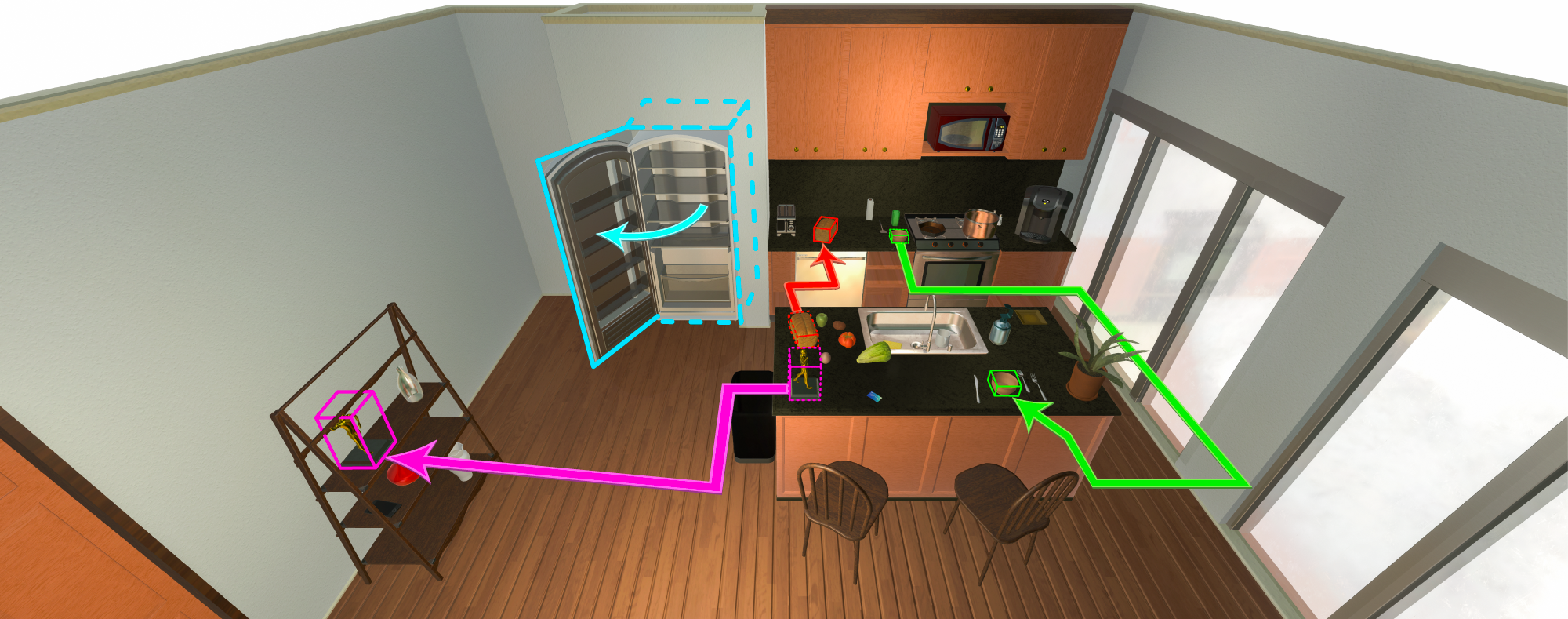
Overview 🤖. Our rearrangement task involves moving and modifying (i.e. opening/closing) randomly placed objects within a room to obtain a goal configuration. There are 2 phases:
- Walkthrough 👀. The agent walks around the room and observes the objects in their ideal goal state.
- Unshuffle 🏋. After the walkthrough phase, we randomly change between 1 to 5 objects in the room. The agent's goal is to identify which objects have changed and reset those objects to their state from the walkthrough phase. Changes to an object's state may include changes to its position, orientation, or openness.
For this 2021 challenge we have two distinct tracks:
- 1-Phase Track (Easier). In this track we merge both of the above phases into a single phase. At every step the agent obtains observations from the walkthrough (goal) state as well as the shuffled state. This allows the agent to directly compare aligned images from the two world-states and thus makes it much easier to determine if an object is, or is not, in its goal pose.
- 2-Phase Track (Harder). In this track, the walkthrough and unshuffle phases occur sequentially and so, once in the unshuffle phase, the agent no longer has any access to the walkthrough state except through any memory it has saved.
For this challenge we have three dataset splits: "train", "val", and "test".
The train split uses floor plans 1-20, 200-220, 300-320, and 400-420 within AI2-THOR,
the "val" split uses floor plans 21-25, 221-225, 321-325, and 421-425, and finally the "test" split uses
scenes 26-30, 226-230, 326-330, and 426-430. These dataset splits are stored as the compressed pickle-serialized files
data/*.pkl.gz. While you are freely (and encouraged) to enhance the training set as you see fit, you should
never train your agent within any of the test scenes.
For evaluation, your model will need to be evaluated on each of the above splits and the results
submitted to our leaderboard link (see section below). As the "train" set is
are quite large, we do not expect you to evaluate on their entirety. Instead we select ~1000 datapoints
from each of these sets for use in evaluation. For convenience, we provide the data/combined.pkl.gz
file which contains the "train", "val", and "test" datapoints that should
be used for evaluation.
| Split | # Total Episodes | # Episodes for Eval | Path |
|---|---|---|---|
| train | 4000 | 800 | data/train.pkl.gz |
| val | 1000 | 1000 | data/val.pkl.gz |
| test | 1000 | 1000 | data/test.pkl.gz |
| combined | 2800 | 2800 | data/combined.pkl.gz |
We are tracking challenge participant entries using the AI2 Leaderboard. The team with the best submission made to either of the below leaderboards by May 31st (midnight, anywhere on earth) will be announced at the CVPR'21 Embodied-AI Workshop and invited to produce a video describing their approach.
In particular, our 2022 leaderboard links can be found at
Our older (2021) leaderboards are also available indefinitely (previous 2021 1-phase leaderboard, [previous 2021 2-phase leaderboard]](https://leaderboard.allenai.org/ithor_rearrangement_1phase)) Note that our 2021 challenge uses a different dataset and older version of AI2-THOR and so results will not be directly comparable.
Submissions should include your agent's trajectories for all tasks contained within the combined.pkl.gz dataset, this "combined" dataset includes tasks for the train, train_unseen, validation, and test sets. For an example as to how to iterate through all the datapoints in this dataset and save the resulting metrics in our expected submission format see here.
A (full) example the expected submission format for the 1-phase task can be found here and, for the 2-phase task, can be found here. Note that this submission format is a gzip'ed json file where the json file has the form
{
"UNIQUE_ID_OF_TASK_0": YOUR_AGENTS_METRICS_AND_TRAJECTORY_FOR_TASK_0,
"UNIQUE_ID_OF_TASK_1": YOUR_AGENTS_METRICS_AND_TRAJECTORY_FOR_TASK_1,
...
}
these metrics and unique IDs can be easily obtained when iterating over the dataset (see the above example).
Alternatively: if you run inference on the combined dataset using AllenAct (see below
for more details) then you can simply (1) gzip the metrics*.json file saved when running inference, (2) rename
this file submission.json.gz, and (3) submit this file to the leaderboard directly.
In both of these tracks, agents should make decisions based off of egocentric sensor readings. The types of sensors allowed/provided for this challenge include:

- RGB images - having shape
224x224x3and an FOV of 90 degrees. - Depth maps - having shape
224x224and an FOV of 90 degrees. - Perfect egomotion - We allow for agents to know precisely how far (and in which direction) they have moved as well as how many degrees they have rotated.
While you are absolutely free to use any sensor information you would like during training (e.g. pretraining your CNN using semantic segmentations from AI2-THOR or using a scene graph to compute expert actions for imitation learning) such additional sensor information should not be used at inference time.
A total of 82 actions are available to our agents, these include:
Navigation
-
Move[Ahead/Left/Right/Back]- Results in the agent moving 0.25m in the specified direction if doing so would not result in the agent colliding with something. -
Rotate[Right/Left]- Results in the agent rotating 90 degrees clockwise (ifRight) or counterclockwise (ifLeft). This action may fail if the agent is holding an object and rotating would cause the object to collide. -
Look[Up/Down]- Results in the agent raising or lowering its camera angle by 30 degrees (up to a max of 60 degrees below horizontal and 30 degrees above horizontal).
Object Interaction
-
Pickup[OBJECT_TYPE]- WhereOBJECT_TYPEis one of the 62 pickupable object types, seeconstants.py. This action results in the agent picking up a visible object of typeOBJECT_TYPEif: (a) the agent is not already holding an object, (b) the agent is close enough to the object (within 1.5m), and picking up the object would not result in it colliding with objects in front of the agent. If there are multiple objects of typeOBJECT_TYPEthen the object closest to the agent is chosen. -
Open[OBJECT_TYPE]- WhereOBJECT_TYPEis one of the 10 opennable object types that are not also pickupable, seeconstants.py. If an object whose openness is different from the openness in the goal state is visible and within 1.5m of the agent, this object's openness is changed to its value in the goal state. -
PlaceObject- Results in the agent dropping its held object. If the held object's goal state is visible and within 1.5m of the agent, it is placed into that goal state. Otherwise, a heuristic is used to place the object on a nearby surface.
Done action
Done- Results in the walkthrough or unshuffle phase immediately terminating.
See the example.py file for an example of how you can instantiate the 1- and 2-phase
variants of our rearrangement task.
The rearrange.environment.RearrangeTHOREnvironment class provides a wrapper around the AI2-THOR environment
and is designed to
- Make it easy to set up a AI2-THOR scene in a particular state ready for rearrangement.
- Provides utilities to make it easy to evaluate (see e.g. the
posesandcompare_posesmethods) how close the current state of the environment is to the goal state. - Provide an API with which the agent may interact with the environment.
You'll notice that the above RearrangeTHOREnvironment is not explicitly instantiated by the example.py
script and, instead, we create rearrange.tasks.RearrangeTaskSampler objects using the
TwoPhaseRGBBaseExperimentConfig.make_sampler_fn and OnePhaseRGBBaseExperimentConfig.make_sampler_fn.
This is because the RearrangeTHOREnvironment is very flexible and doesn't know anything about
training/validation/test datasets, the types of actions we want our agent to be restricted to use,
or precisely which types of sensor observations we want to give our agents (e.g. RGB images, depth maps, etc).
All of these extra details are managed by the RearrangeTaskSampler which iteratively creates new
tasks for our agent to complete when calling the next_task method. During training, these new tasks can be sampled
indefinitely while, during validation or testing, the tasks will only be sampled until the validation/test datasets
are exhausted. This sampling is best understood by example so please go over the example.py file.
As described above, the RearrangeTaskSampler samples tasks for our agent to complete, these tasks correspond
to instantiations of the rearrange.tasks.WalkthroughTask and rearrange.tasks.UnshuffleTask classes. For the 2-phase
challenge track, the RearrangeTaskSampler will first sample a new WalkthroughTask after which it will sample a
corresponding UnshuffleTask where the agent must return the objects to their poses at the start of the
WalkthroughTask.
Accessing object poses 🧘. The poses of all objects in the environment can be accessed
using the RearrangeTHOREnvironment.poses property, i.e.
unshuffle_start_poses, walkthrough_start_poses, current_poses = env.poses # where env is an RearrangeTHOREnvironment instance Reading an object's pose 📖. Here, unshuffle_start_poses, walkthrough_start_poses, and current_poses
evaluate to a list of dictionaries and are defined as:
unshuffle_start_posesstores a list of object poses if the agent were to do nothing to theenvduring the unshuffling phase.walkthrough_start_posesstores a list of object poses that the agent sees during the walkthrough phase.current_posesstores a list of object poses in the current state of the environment (i.e. possibly after the unshuffle agent makes all its changes to theenvduring the unshuffling phase).
Each dictionary contains the object's pose in a form similar to:
{
"type": "Candle",
"position": {
"x": -0.3012670874595642,
"y": 0.7431036233901978,
"z": -2.040205240249634
},
"rotation": {
"x": 2.958569288253784,
"y": 0.027708930894732475,
"z": 0.6745457053184509
},
"openness": None,
"pickupable": True,
"broken": False,
"objectId": "Candle|-00.30|+00.74|-02.04",
"name": "Candle_977f7f43",
"parentReceptacles": [
"Bathtub|-01.28|+00.28|-02.53"
],
"bounding_box": [
[-0.27043721079826355, 0.6975823640823364, -2.0129783153533936],
[-0.3310248851776123, 0.696869969367981, -2.012985944747925],
[-0.3310534358024597, 0.6999208927154541, -2.072017192840576],
[-0.27046576142311096, 0.7006332278251648, -2.072009563446045],
[-0.272365003824234, 0.8614493608474731, -2.0045082569122314],
[-0.3329526484012604, 0.8607369661331177, -2.0045158863067627],
[-0.3329811990261078, 0.8637878894805908, -2.063547134399414],
[-0.27239352464675903, 0.8645002245903015, -2.063539505004883]
]
}Matching objects across poses 🤝. Across unshuffle_start_poses, walkthrough_start_poses, and current_poses,
the ith entry in each list will always correspond to the same object across each pose list.
So, unshuffle_start_poses[5] will refer to the same object as walkthrough_start_poses[5] and current_poses[5].
Most scenes have around 70 objects, among which, 10 to 20 are pickupable by the agent.
Pose keys 🔑.
opennessspecifies the[0:1]percentage that an object is opened. For objects where theopennessvalue does not fit (e.g.,Bowl,Spoon), theopennessvalue isNone.bounding_boxis only given for moveable objects, where the set of moveable objects may consist of couches or chairs, that are not necessarily pickupable. For pickupable objects, the bounding_box is aligned to the object's relative axes. For moveable objects that are non-pickupable, the object is aligned to the global axes.brokenstates if the object broke from the agent's actions during the unshuffling phase. The initial pose or goal pose for each object will never be broken. But, if the agent decides to pick up an object, and drop it on a hard surface, it's possible that the object can break.
To evaluate the quality of a rearrangement agent we compute several metrics measuring how well the agent has managed to move objects so that their final poses are (approximately) equal to their goal poses.
Recall that we represent the pose of an object as a combination of its:
- Openness 📖. - A value in [0,1] which measures how far the object has been opened.
- Position 📍, Rotation 🙃, and bounding box 📦 - The 3D position, rotation, and bounding box of each object.
- Broken - A boolean indicating if the object has been broken (all goal object poses are unbroken).
The openness between its goal state and predicted state is off by less than 20 percent. The openness check is only applied to objects that can open. The object's 3D bounding box from its goal pose and the predicted pose must have an IoU over 0.5. The positional check is only relevant to objects that can move.
To measure if two object poses are approximately equal we use the following criterion:
- ❌ If any object pose is broken.
- ❌ If the object is opennable but not pickupable (e.g. a cabinet) and the the openness values between the two poses differ by more than 0.2.
- ❌ The two 3D bounding boxes of pickupable objects have an IoU under 0.5.
- ✔️ None of the above criteria are met so the poses are not broken, are close in openness values, and have sufficiently high IoU.
Suppose that task is an instance of an UnshuffleTask which your agent has taken
actions until reaching a terminal state (e.g. either the agent has taken the maximum number of steps or it
has taken the "done" action). Then metrics regarding the agent's performance can be computed by calling
the task.metrics() function. This will return a dictionary of the form
{
"task_info": {
"scene": "FloorPlan420",
"index": 7,
"stage": "train"
},
"ep_length": 176,
"unshuffle/ep_length": 7,
"unshuffle/reward": 0.5058389582634852,
"unshuffle/start_energy": 0.5058389582634852,
"unshuffle/end_energy": 0.0,
"unshuffle/prop_fixed": 1.0,
"unshuffle/prop_fixed_strict": 1.0,
"unshuffle/num_misplaced": 0,
"unshuffle/num_newly_misplaced": 0,
"unshuffle/num_initially_misplaced": 1,
"unshuffle/num_fixed": 1,
"unshuffle/num_broken": 0,
"unshuffle/change_energy": 0.5058464936498058,
"unshuffle/num_changed": 1,
"unshuffle/prop_misplaced": 0.0,
"unshuffle/energy_prop": 0.0,
"unshuffle/success": 0.0,
"walkthrough/ep_length": 169,
"walkthrough/reward": 1.82,
"walkthrough/num_explored_xz": 17,
"walkthrough/num_explored_xzr": 46,
"walkthrough/prop_visited_xz": 0.5151515151515151,
"walkthrough/prop_visited_xzr": 0.3484848484848485,
"walkthrough/num_obj_seen": 11,
"walkthrough/prop_obj_seen": 0.9166666666666666
}Of the above metrics, the most important (those used for comparing models) are
- Success rate (
"unshuffle/success") - This is the most unforgiving of our metrics and equals 1 if all object poses are in their goal states after the unshuffle phase. - % Misplaced (
"unshuffle/prop_misplaced") - The above sucess metric is quite strict, requiring exact rearrangement of all objects, and also does not additionally penalize an agent for moving objects that should not be moved. This metric equals the number of misplaced objects at the end of the episode divided by the number of misplaced objects at the start of the episode. Note that this metric can be larger than 1 if the agent, during the unshuffle stage, misplaces more objects than were originally misplaced at the start. - % Fixed Strict (
"unshuffle/prop_fixed_strict") - This metric equals 0 if, at the end of the unshuffle task, the agent has misplaced any new objects (i.e. it has incorrectly moved an object that started in its correct position). Otherwise, if it has not misplaced new objects, then this equals (# objects which started in the wrong pose but are now in the correct pose) / (# objects which started in an incorrect pose), i.e. the proportion of objects who had their pose fixed. - % Energy Remaining (
"unshuffle/energy_prop") - The above metrics do not give any partial credit if, for example, the agent moves an object across a room and towards its goal pose but fails to place it so that has a sufficiently high IOU with the goal. To allow for partial credit, we define an energy functionDthat monotonically decreases to 0 as two poses get closer together (see code for full details) and which equals zero if two poses are approximately equal. This metric is then defined as the amount of energy remaining at the end of the unshuffle episode divided by the total energy at the start of the unshuffle episode, i.e. equals (sum of energy between all goal/current object poses at end of the unshuffle phase) / (sum of energy between all goal/current object poses at the start of the unshuffle phase).
We use the AllenAct framework for training our baseline rearrangement models, this framework is automatically installed when installing the requirements for this project.
Before running training or inference you'll first have to add the ai2thor-rearrangement directory
to your PYTHONPATH (so that python and AllenAct knows where to for various modules).
To do this you can run the following:
cd YOUR/PATH/TO/ai2thor-rearrangement
export PYTHONPATH=$PYTHONPATH:$PWDLet's say you want to train a model for the 1-phase challenge. This can be easily done by running the command
allenact -o rearrange_out -b . baseline_configs/one_phase/one_phase_rgb_resnet_dagger.py This will train (using DAgger, a form of imitation learning) a model which uses a pretrained (with frozen
weights) ResNet18 as the visual backbone that feeds into a recurrent neural network (a GRU) before
producing action probabilities and a value estimate. Results from this training are then saved to
rearrange_out where you can find model checkpoints, tensorboard plots, and configuration files that can
be used if you, in the future, forget precisely what the details of your experiment were.
A similar model can be trained for the 2-phase challenge by running
allenact -o rearrange_out -b . baseline_configs/two_phase/two_phase_rgb_resnet_ppowalkthrough_ilunshuffle.pyIn the below table we provide a collection of pretrained models from:
- Our CVPR'21 paper introducing this challenge, and
- Our CVPR'22 paper which showed that using CLIP visual encodings can dramatically improve model performance acros embodied tasks.
We have only evaluated a subset of these models on our 2022 dataset.
| Model | % Fixed Strict (2022 dataset, test) | % Fixed Strict (2021 dataset, test) | Pretrained Model |
|---|---|---|---|
| 1-Phase Embodied CLIP ResNet50 IL | 19.1% | 17.3% | (link) |
| 1-Phase ResNet18+ANM IL | - | 8.9% | (link) |
| 1-Phase ResNet18 IL | - | 6.3% | (link) |
| 1-Phase ResNet18 PPO | - | 5.3% | (link) |
| 1-Phase Simple IL | - | 4.8% | (link) |
| 1-Phase Simple PPO | - | 4.6% | (link) |
| 2-Phase ResNet18+ANM IL+PPO | 0.53% | 1.44% | (link) |
| 2-Phase ResNet18 IL+PPO | - | 0.66% | (link) |
These models can be downloaded at from the above links and should be placed into the pretrained_model_ckpts directory.
You can then, for example, run inference for the 1-Phase ResNet18 IL model using AllenAct by running:
export CURRENT_TIME=$(date '+%Y-%m-%d_%H-%M-%S') # This is just to record when you ran this inference
allenact baseline_configs/one_phase/one_phase_rgb_resnet_dagger.py \
-c pretrained_model_ckpts/exp_OnePhaseRGBResNetDagger_40proc__stage_00__steps_000050058550.pt \
--extra_tag $CURRENT_TIME \
--evalthis will evaluate this model across all datapoints in the data/combined.pkl.gz dataset
which contains data from the train, val, and test sets so that
evaluation doesn't have to be run on each set separately.
If you use this work, please cite our CVPR'21 paper:
@InProceedings{RoomR,
author = {Luca Weihs and Matt Deitke and Aniruddha Kembhavi and Roozbeh Mottaghi},
title = {Visual Room Rearrangement},
booktitle = {IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)},
month = {June},
year = {2021}
}