F3RM: Feature Fields for Robotic Manipulation
We distill features from 2D foundation models into 3D feature fields, and enable few-shot language-guided manipulation that generalizes across object poses, shapes, appearances and categories.
William Shen*1, Ge Yang*1,2,
Alan Yu1,
Jansen Wong1,
Leslie Kaelbling1,
Phillip Isola1
1 MIT CSAIL,
2 Institute of AI and Fundamental Interactions (IAIFI)
* Indicates equal contribution
CoRL 2023 (Oral)
Table of Contents
We provide the official implementation of F3RM for:
- Training Feature Fields
- 6-DOF Pose Optimization for Open-Text Language-Guided Manipulation
F3RM is built on top of Nerfstudio following their guide for adding new methods. For a summary of the codebase structure, see assets/code_structure.md.
Note: this repo requires an NVIDIA GPU with CUDA 11.7+ for NeRF and feature field distillation.
# We recommend that you use conda to manage your environment
conda create -n f3rm python=3.8
conda activate f3rm# Install torch per instructions here: https://pytorch.org/get-started/locally/
# Choose the CUDA version that your GPU supports. We will use CUDA 11.8
pip install torch==2.0.1+cu118 torchvision==0.15.2+cu118 --extra-index-url https://download.pytorch.org/whl/cu118
# Install CUDA toolkit, you can skip this if you already have CUDA 11.8 installed
# You can check your existing CUDA installation with `nvcc --version`
conda install -c "nvidia/label/cuda-11.8.0" cuda-toolkit
export CUDA_HOME=$CONDA_PREFIX
# Install tiny-cuda-nn, this will take a few minutes
pip install ninja git+https://github.com/NVlabs/tiny-cuda-nn/#subdirectory=bindings/torchgit clone https://github.com/f3rm/f3rm.git
cd f3rm
# Install F3RM and its dependencies
pip install -e .
# Install command-line completions for nerfstudio
ns-install-cli
# Test your installation, check that 'f3rm' is a valid method
ns-train --helpNote: if you have a previous installation of Nerfstudio, make sure it does not conflict with the new installation
in the f3rm conda environment. Run which -a ns-train and check that the first entry points to
$CONDA_PREFIX/bin/ns-train. If it doesn't, then you may need to deactivate all conda environments and only activate
the f3rm environment.
Make sure your conda environment is activated before running the following commands.
# Install robot dependencies
pip install -e ".[robot]"
# Install PyTorch3D, we recommend you build from source which may take a few minutes
# Alternatively, check: https://github.com/facebookresearch/pytorch3d/blob/main/INSTALL.md
pip install "git+https://github.com/facebookresearch/pytorch3d.git@stable"
# Install the latest version of viser, temporary workaround as current nerfstudio release uses older version
pip install viser==0.17.0
# Test your installation. If you see a help message, everything should be working
f3rm-optimize --helpWe provide example datasets of tabletop and room-scale environments which you can download using
the f3rm-download-data command. By default, the script will download all the datasets (requires ~350MB disk space)
into the datasets/f3rm directory relative to your current directory.
Run f3rm-download-data -h to see how to download specific datasets or set your own save directory. We provide a short
description and preview of each dataset in assets/datasets.md.
We provide the functionality to train a NeRF and distill features in parallel. The default features we distill are CLIP
features. You can distill DINO features instead by adding --pipeline.datamanager.feature-type DINO.
ns-train f3rm --data <data_folder>You can try F3RM with the example datasets which you can download following the
instructions here (try out f3rm/panda/scene_001). Alternatively, you can prepare your
own datasets following the instructions in the
Nerfstudio documentation.
Note that while we focused on tabletop environments in the paper, F3RM can be scaled up to much larger environments. Try training feature fields on the example rooms datasets.
You do not need to run the training to completion. We save a checkpoint every 2000 steps by default. To see all the
options available for training, run ns-train f3rm -h.
Use the --load-dir flag to resume training from a checkpoint. Nerfstudio writes the checkpoint files to the outputs/
directory relative to your current directory.
ns-train f3rm --data <data_folder> --load-dir {outputs/.../nerfstudio_models}Checkout the Nerfstudio documentation for more details on functionality.
Our custom web viewer is coming soon! Keep an eye on out for updates.
Once you have started training the feature field with ns-train, Nerfstudio will print a URL to the viewer in the
terminal (the URL will start with https://viewer.nerf.studio). You can open this URL to open the Nerfstudio viewer in
your browser to visualize training progress and the feature field. Alternatively, to visualize a trained model you can
run ns-viewer --load-config {outputs/.../config.yml}.
Note that if you are using a remote server, you will need to forward the port to your local machine (instructions). The default port used by Nerfstudio is 7007, but check the viewer URL to make sure. For a general guide on how to use the Nerfstudio viewer, check out their documentation.
To visualize the PCA of the features, select feature_pca in the Render Options -> Output Render dropdown box.
Note that the initial PCA projection matrix is computed based on the features rendered at your current viewpoint.
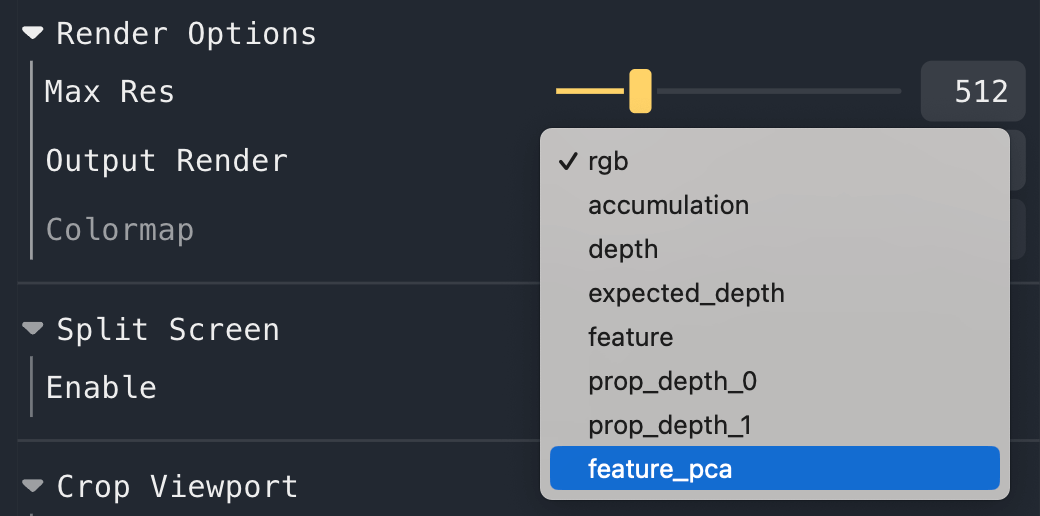
To recompute the PCA projection based on your current viewpoint, click the "Refresh PCA Projection" button under
Trainer/pipeline/model near the bottom of the controls.
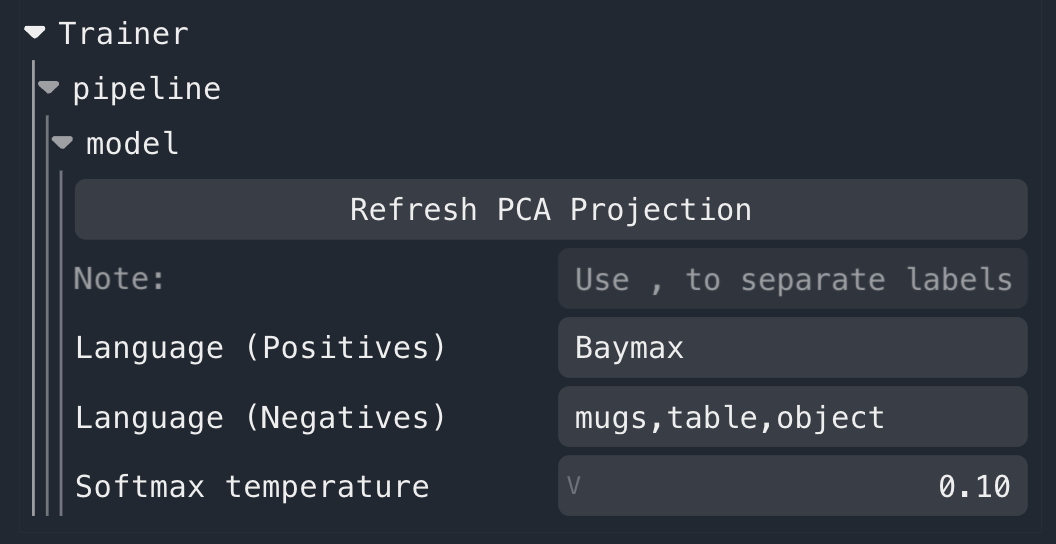
If you are distilling CLIP features (the default feature type), then you will see the following additional controls
under Trainer/pipeline/model near the bottom of the controls panel. You can enter positive and negative text queries
(separated by , commas), which will compute similarity heatmaps. You will need to click out of the text box or press
the enter key to submit the query.
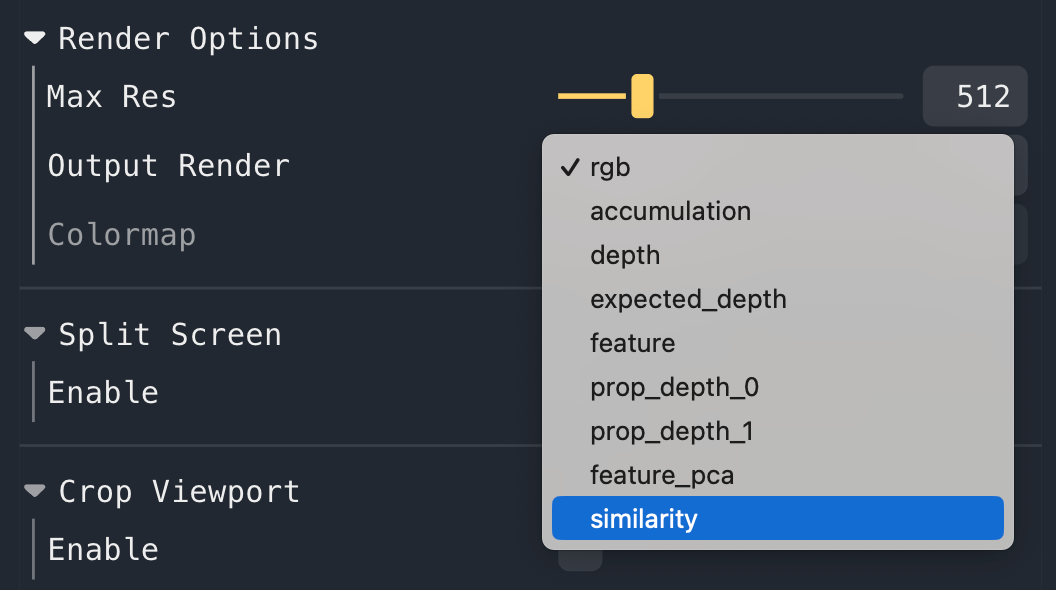
To visualize these heatmaps, select similarity in the Render Options -> Output Render dropdown box. It may take a
few seconds for this option to show up on the first query, as we load CLIP lazily.
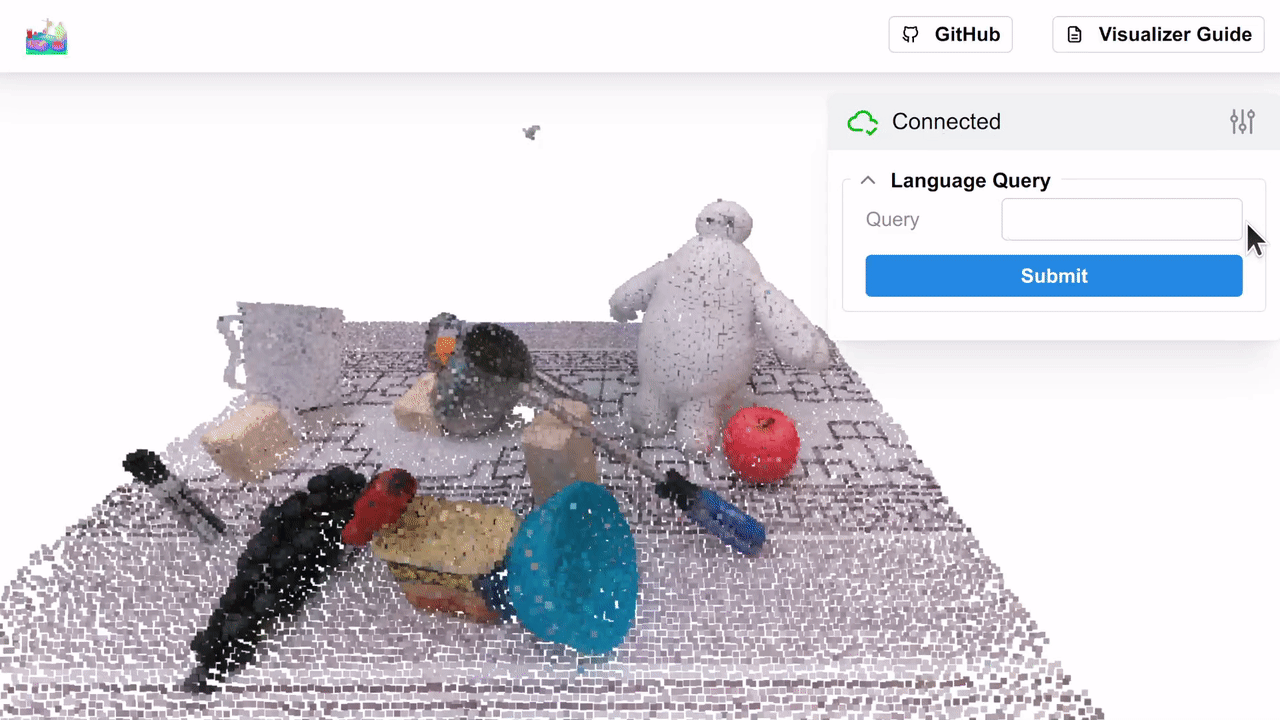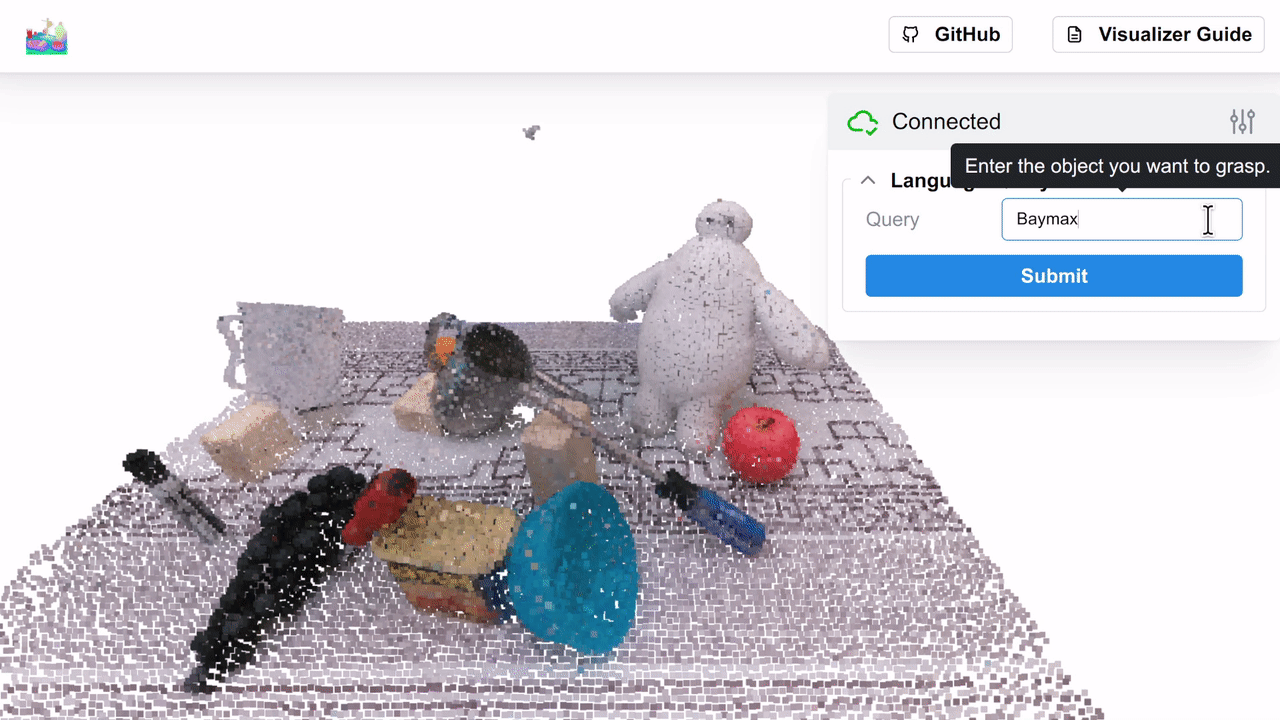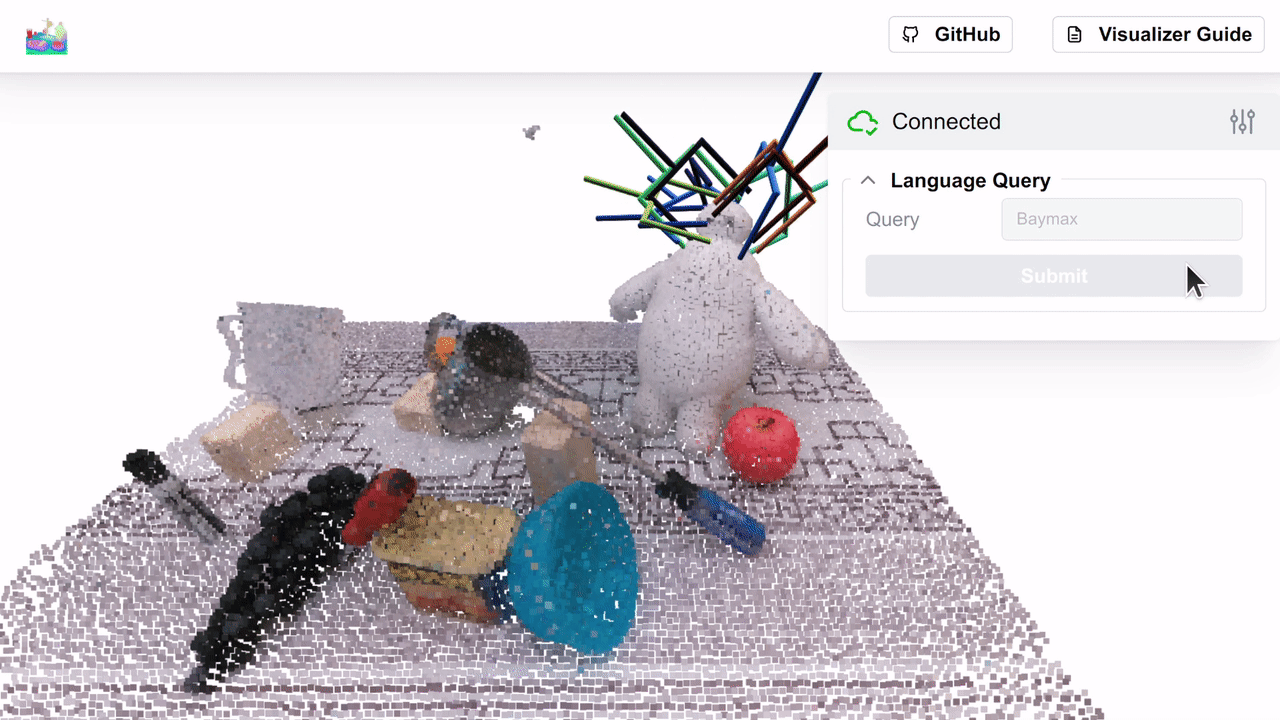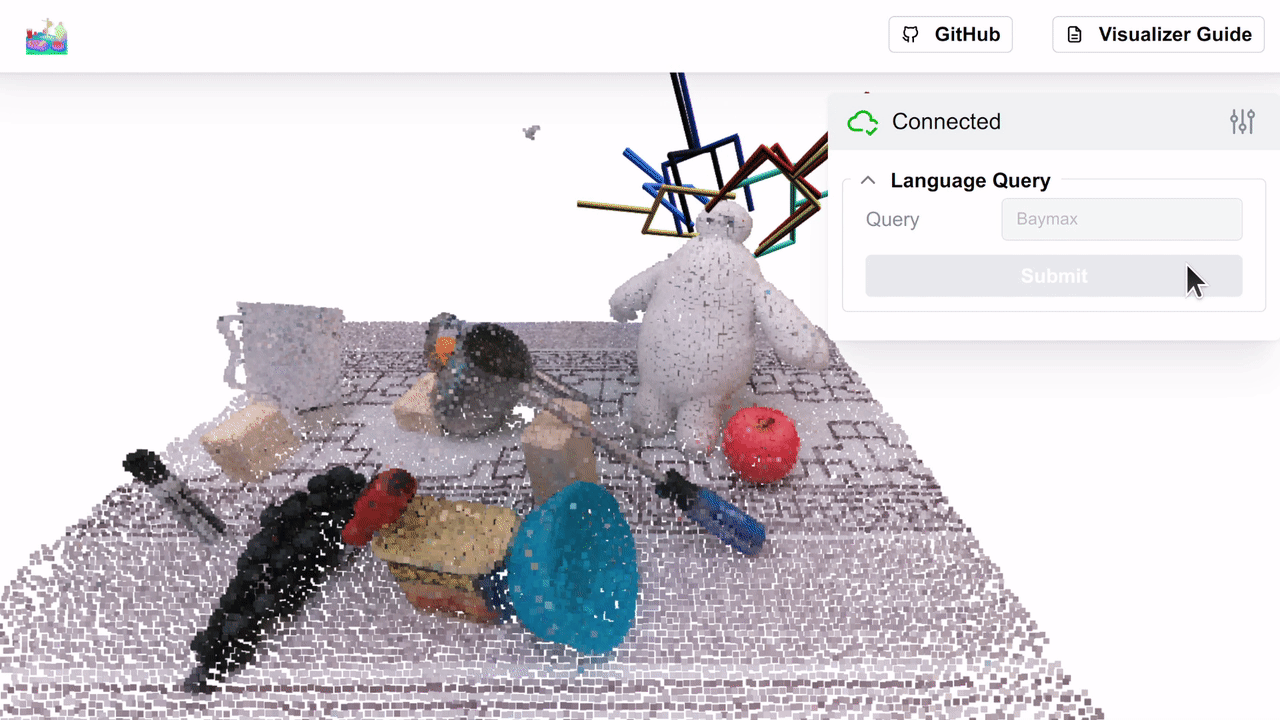
We show the similarity heatmap over the f3rm/panda/scene_001 dataset for the "Baymax" query, with the negatives in the
controls above (you can download this dataset using the f3rm-download-data panda command). Try playing around with
different language queries and see what results you get!

Note: if multiple positive queries are specified, we average their CLIP embeddings before computing the pair-wise softmax described in Section 3.3 of the paper. The default temperature of 0.1 works well. If no negative queries are specified, then we show the cosine similarity between the positive query and the feature field.
We provide scripts to demonstrate how to extract CLIP and DINO features from their respective vision models. You can use these features for your own NeRF pipeline or for other downstream applications.
- Run
python f3rm/scripts/demo_extract_features.pyfor a general demo on how to extract CLIP and DINO features. This will create a plot showing the PCA of the CLIP and DINO features. The plot is saved todemo_extract_features.png. - For details on how to extract CLIP features and compare the extracted features with CLIP text embeddings, run
python f3rm/scripts/demo_clip_features.py. This script will create a plot showing the similarity heatmaps for a given text query, and will save a plot todemo_clip_features-{text_query}.png.
For details on how to run the 6-DOF pose optimization code for language-guided manipulation, please check f3rm_robot/README.md. A detailed tutorial is provided.
The Nerfstudio viewer can sometimes fail to register the input you type into the text boxes if you are use the same
browser tab for different training runs. This means feature_pca and similarity may not appear in the Render Options.
To fix this issue, try closing the tab with the viewer in your browser and opening it again. If this doesn't work,
please open an issue in this repository.
This codebase was tested on a RTX3090 with 24GB of GPU memory. We observe a peak memory usage of ~6GB when training a CLIP feature field without using the viewer. When the viewer is used in conjunction with training, the peak memory usage is ~12GB.
If you are running out of memory when using the Nerfstudio viewer, try:
- Decreasing the number of rays per batch when rendering by using the
--pipeline.model.eval-num-rays-per-chunk 8192flag when runningns-train.- The default rays per chunk is 16384, which uses ~12GB of memory (at
Max Res = 512). - 8192 rays per chunk uses ~10GB memory. Decreasing this number will further reduce memory usage, at the cost of slower rendering.
- The default rays per chunk is 16384, which uses ~12GB of memory (at
- Decrease the rendering resolution in
Max Resunder Render Options in the Nerfstudio viewer.
If you are running out of memory during any other stages, please open a GitHub issue and we will try to help.
We thank the authors of the following projects for making their code open source:
If you find our work useful, please consider citing:
@inproceedings{shen2023F3RM,
title={Distilled Feature Fields Enable Few-Shot Language-Guided Manipulation},
author={Shen, William and Yang, Ge and Yu, Alan and Wong, Jansen and Kaelbling, Leslie Pack and Isola, Phillip},
booktitle={7th Annual Conference on Robot Learning},
year={2023},
url={https://openreview.net/forum?id=Rb0nGIt_kh5}
}