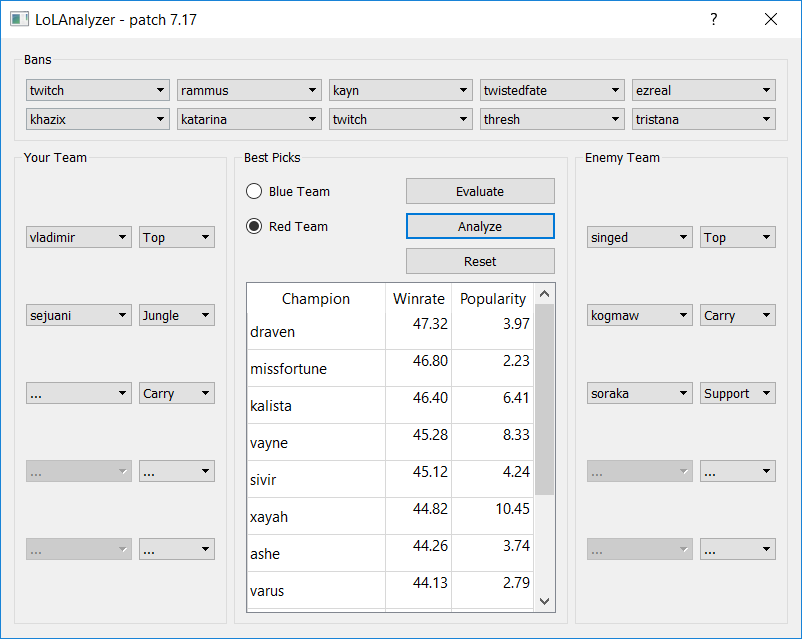
This small project contains all the tools you will ever need to train and use neural networks for the purpose of draft analysis. Precisely, you can use this application to evaluate your own drafts (partial or complete) and find the champions that will maximize your chances of winning the game.
It is a project I have developed in my spare time. I have tested it as much as I could, but I can't provide you any guarantee you won't ever find any bug. However, if you find some, please let me know. Any feedback is welcome.
I know that most people here are LoL players running on Windows and who would like to have a .exe to double-click and go. Unfortunately, I am using many heavy libraries and making you download a 2GB program instead of a couple scripts is certainly not the way to go. Of course, if you know a way to create a light-weight distributable program, please let me know. Don't worry, even if you don't know a thing about Python or even programming you should not have any trouble installing and using this application.
Most of the scripts here are designed to create a neural network from scratch. Since I guess most people just want to try out the application, I have provided a demo network for the patch 7.17. Updating the network on a daily basis is a huge amount of work I will NOT do. If you want to seriously use this application, you will have to train your own neural network (or find someone who will.)
I am myself a LoL player. I have been playing this game since season 1 and as many of my fellow players, I love playing ranked games, I want to become stronger and climb the ladder. But becoming stronger is not all about picking Yasuo/Zed, making plays and carrying your team (of course don't forget to spam your mastery when you do). Sometimes, getting better at the game is simply about building a better team. How many times have you said to yourself you had lost a game by simply looking at your draft. Sometimes it's not your fault, you are the first pick, you can't predict everything. But sometimes it is, and worse, you may not even realize it.
So how can you make sure you're not the fail pick? How can you make sure the champion you pick actually fits the team?
Personally, I have been using op.gg for a long time. They provide a wide range of meaningful statistics for whoever wants to play ranked seriously. They give champions win ratio, matchups information, best builds, etc. But is it enough to choose the perfect champion for your team? Unfortunately, no. The reason is simple: since the analysis is made from large statistics, it does not take into account the most important information of the draft: what your team and the opponent team composition is. For instance, even if Pantheon is reported to be the best top laner on op.gg and to have an average of 54.22% win rate, does it mean it is always a good choice to pick Pantheon top? Of course not. The truth is that once you're in a draft, this number is not that relevant anymore. You have no choice then but to rely mainly on your experience, which will never be perfect, regardless the time you spent in the game.
There's nothing to worry, though: a computer can collect all the draft experience you will ever need. This is where machine learning kicks in.
The strength of a machine learning based system is that it can predict the outcome of games it has never encounter, whereas a statistical tool needs to see the same situation over and over to predict the outcome efficiently. How does it work? Well, it's rather simple: let's imagine your team is composed of Jarvan top, Sejuani jungle, Zilean mid, Janna support and Kog'Maw adc and that you won the game. The system will not learn that Jarvan top, Sejuani jungle, Zilean mid, Janna support and Kog'Maw adc is a good composition; instead, it will learn that this kind of team composition works well: a lot of cc, peeler and one hyper-carry. In fact, it is what any human would do. You can replace Jarvan for Maokai, Sejuani for Amumu or Kog'Maw for Jinx, it doesn't really change the nature of the team, and from the neural network perspective (and yours), there are almost the same. Hence, if you want the neural network to be strong, the only thing you need to do is to make sure it has been trained with a lot of different drafts. The difference between a human and a computer here is that a machine will learn faster than you, and will be able to digest way more data than you.
This project uses Python 3 (it won't work with Python 2.7). If you are on Windows/Mac OS, you can download it from the official webpage: https://www.python.org/downloads/. During installation, makes sure to check "Add Python 3.X to PATH". If you're on Linux you can install it with the package manager (for example on debian:)
sudo apt-get update
sudo apt-get install python3 python3-pip
Keep in mind that on Linux you will have to call python3 and pip3 instead of python and pip (default python is for python 2.7 and it's not recommended to change it).
You can check your installation of python by opening a console (on Windows Win+R > cmd), typing python and checking that the version matches what you have installed. For example:
Python 3.5.0 |Anaconda custom (64-bit)| (default, Dec 1 2015, 11:46:22) [MSC v.1900 64 bit (AMD64)] on win32
Type "help", "copyright", "credits" or "license" for more information.
If the console tells you it can't find the python command, it's usually because you have forgotten to add python to PATH during installation. You can either re-install python or add it to PATH manually (google is your best friend).
Now you will need to install some libraries, this can be done easily by using pip in a console:
pip install numpy pandas PyQt5 configparser python-slugify requests keras tensorflow h5py
Finally, if you plan to build and train your own neural networks you will need a developer API-KEY to interact with Riot's servers: https://developer.riotgames.com/. This is not mandatory if you just want to use the demo network. Keep in mind that your API-KEY may expire at some point. In such case you will have to generate a new one from the developer portal.
If you plan to go ahead with the example files, keep in mind you have to respect the following architecture:
- config.ini has to be put in the same folder than the scripts
- models you download have to be put in YOUR_DATABASE/models/xxx.h5
YOUR_DATABASE has to be defined in config.ini. You can set any folder you want, for example: C:\LoLAnalyzerDB. It is not necessary to get an API-KEY if you only want to run a model.
You may have to change the default model used in BestPicks.py (it can be opened with any text editor) to make sure it corresponds to the model you want to use (this is defined at the end of the script). Check examples/README.md for the exact parameters.
To run the application, open a new console and set the current working directory to where all the scripts are. You can change the working directory by using cd command, like this (you can even drag & drop the folder in the console):
cd PATH_TO_FOLDER
Finally, you can run the application from a console:
python BestPicks.py
I think the GUI is rather self-explanatory but tell me if you find it hard to use or not user-friendly.
If you want to build everything from scratch and maintain your own network, simply run the scripts in the following order (working directory has to be the same as the scripts):
- ConfigUpdater.py : generate your personnal config.ini. It is a simple text file and easy to edit. If you have a basic API-KEY, I recommend you to only select challenger and master leagues. Servers limitations are independant so there's no reason to not collect games from all the servers.
- RunAll.py : All the steps from 2 to 8 at once. You can jump steps you've already done by simply commenting lines in the script. The script is short short and easy to configure so I recommend you to use it.
Or in detail:
- ConfigUpdater.py : generate your personnal config.ini. It is a simple text file and easy to edit. If you have a basic API-KEY, I recommend you to only select challenger and master leagues. Servers limitations are independant so there's no reason to not collect games from all the servers.
- PlayersListing.py : list all the players that meet the level requirements (defined in config.ini). I would not recommend taking more than challenger and master if you don't have a decent limit-rate on your API key (or it will takes you ages)
- DataDownloader.py : download games played by the listed players
- DataExtractor.py : extract and collect all the downloaded data
- DataProcessing.py : pre-process the extracted data
- DataShuffling.py : shuffle the data
- Learner.py: train a neural network. You can accelerate the learning speed by installing tensorflow-gpu
- BestPicks.py: start a GUI to use the network
Starting from scratch will take quite some time. Don't be surprised if it takes a week!
images/ subfolder contains some screenshot of the application running.
As for the performance, the model given in the examples/ subfolder has reached an overall accuracy of 53.49% (from the ban phase to the full draft) and a full-draft accuracy of 55.57%. The latter number is rather high and shows that you can significantly increase your win rate by simply improving your draft.
- When there's a new patch, run ConfigUpdater.py
- You can delete config.ini to start with a clean config but it's easier to simply edit the file
- You can download games from several patches by listing them in the config.ini file. See the list of all the patches for the syntax and existing patches. In order to download the most recent games first, the patches should be ordered from the most recent to the oldest.
- When you download games, you may experience some errors (see https://developer.riotgames.com/response-codes.html), most often: 404/503 if the data was not found/service is unavailable, 403 means your API-KEY has expired (edit config.ini with a new one from https://developer.riotgames.com/).
- The downloaded games are located under DATABASE_ROOT/patches/PATCH/REGION/. You can change the patch/regions you're downloading games from by simply editing config.ini.
- Extracted data location is DATABASE_ROOT/extracted/ and DATABASE_ROOT/extracted.txt and contains all the data you've downloaded (all patches/all regions)
- Preprocessed data location is DATABASE_ROOT/data_XXXX/ (the actual name depends on the network you use.)
- Only DATABASE_ROOT/training_XXXX/ is used for the training, so if you need to free some space on your hard drive you can delete the data files from a patch you've already fully extracted (under DATABASE_ROOT/patches/). Keep in mind if you don't configure the app properly, it may re-download games you've already used for training
- The models you train are located under DATABASE_ROOT/models.
- Faster player listing (current algorithm is rather slow)
- Policy network for pick prediction and pre-selection evaluation