Quick Annotator is an open-source digital pathology annotation tool.
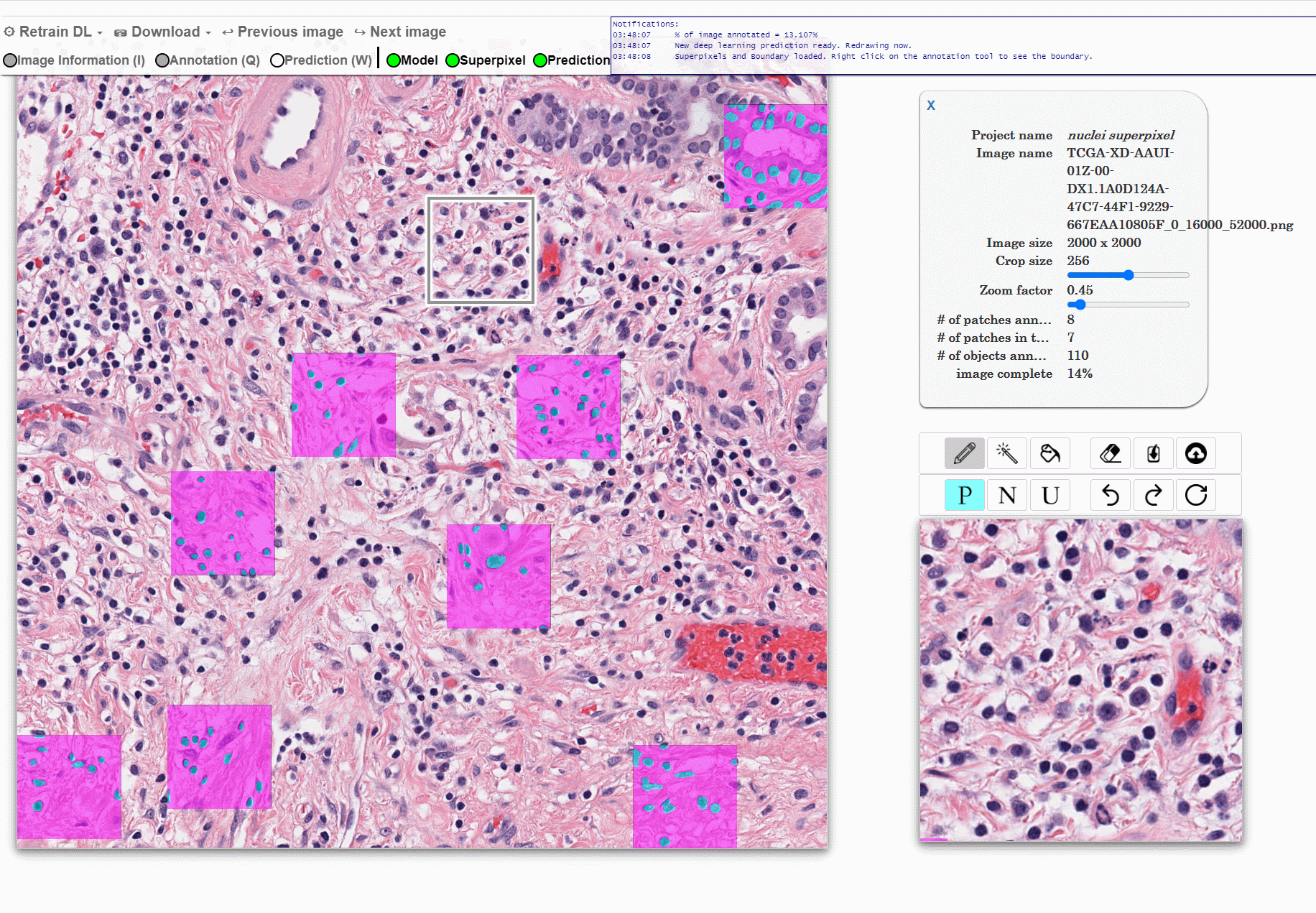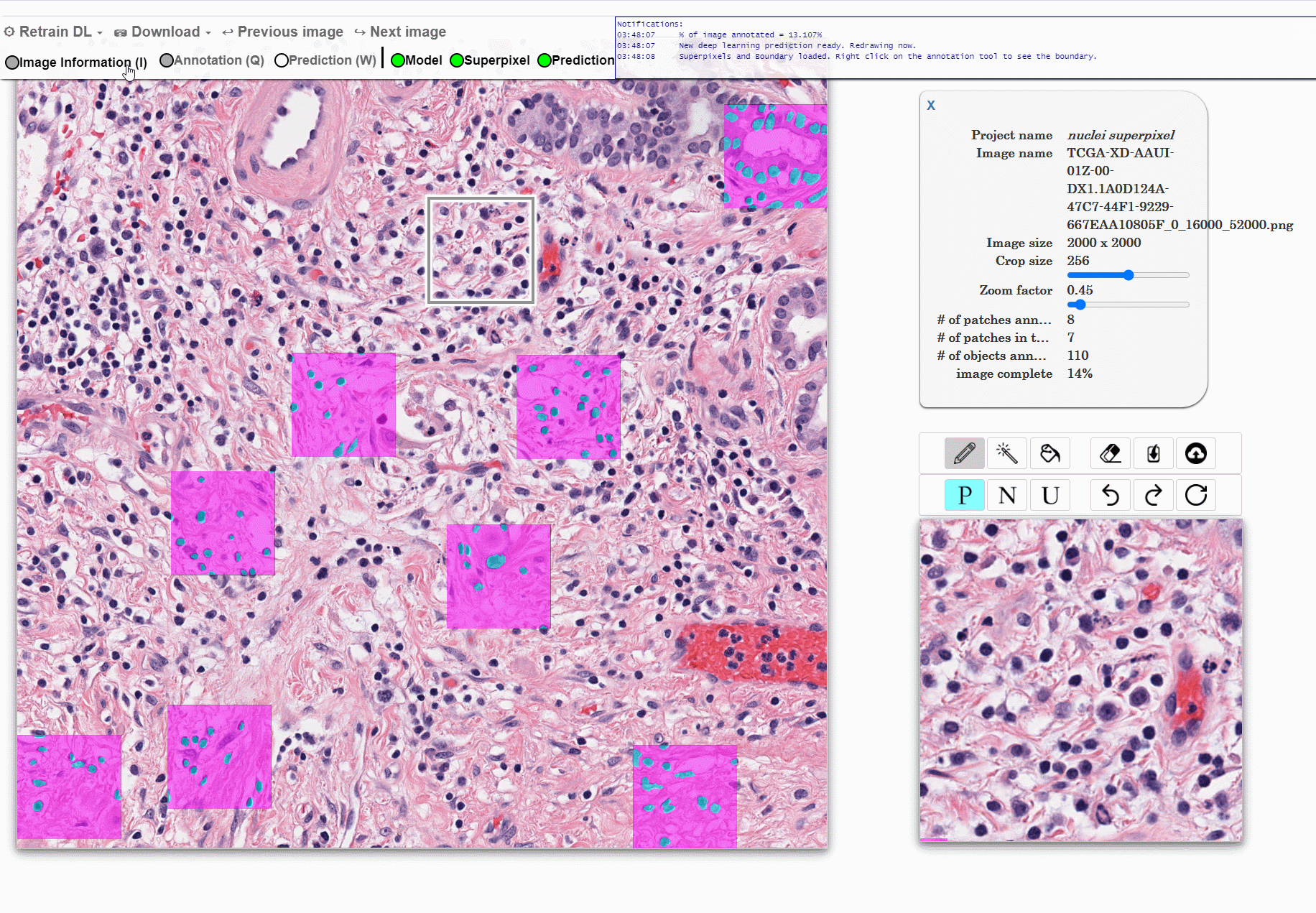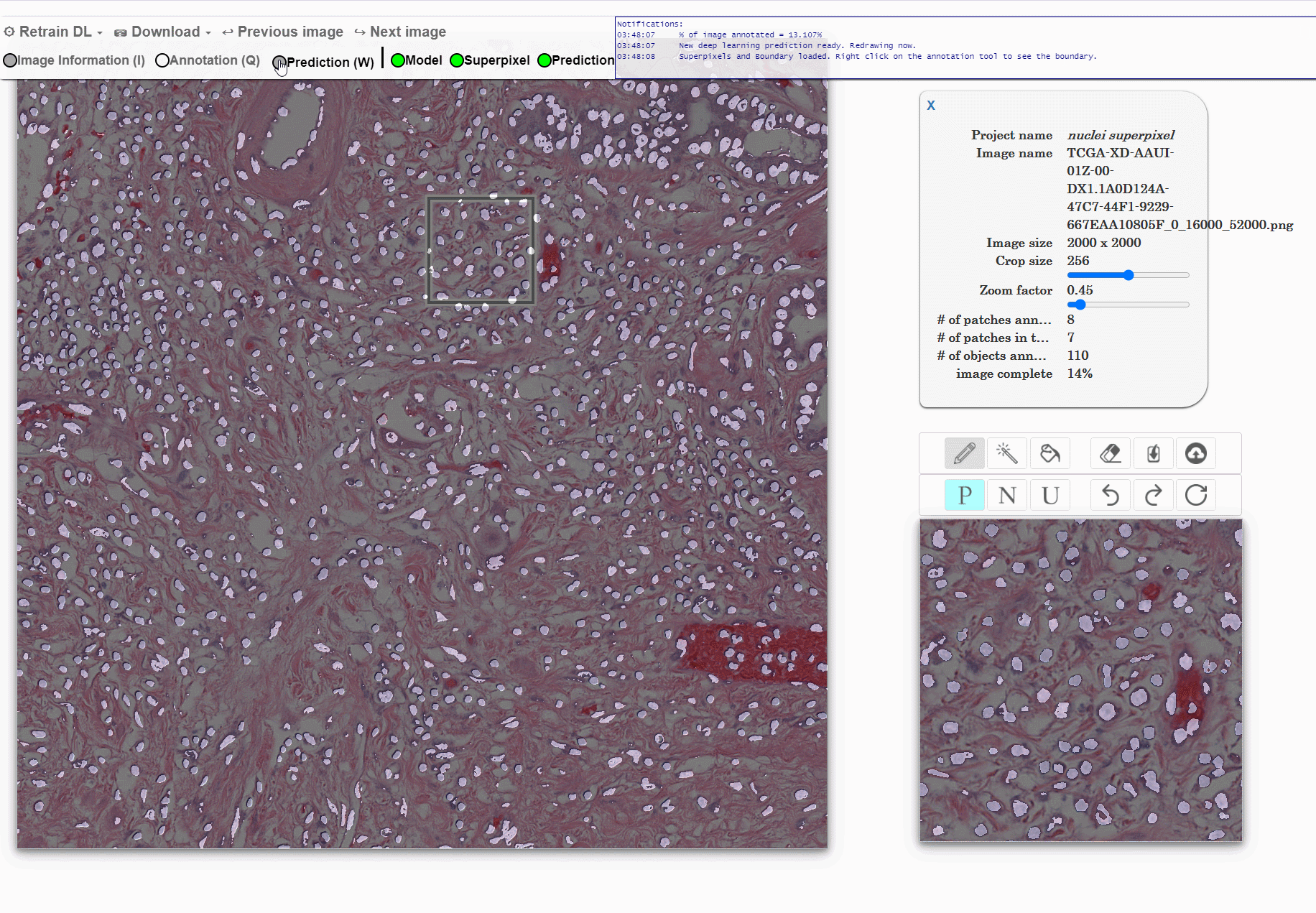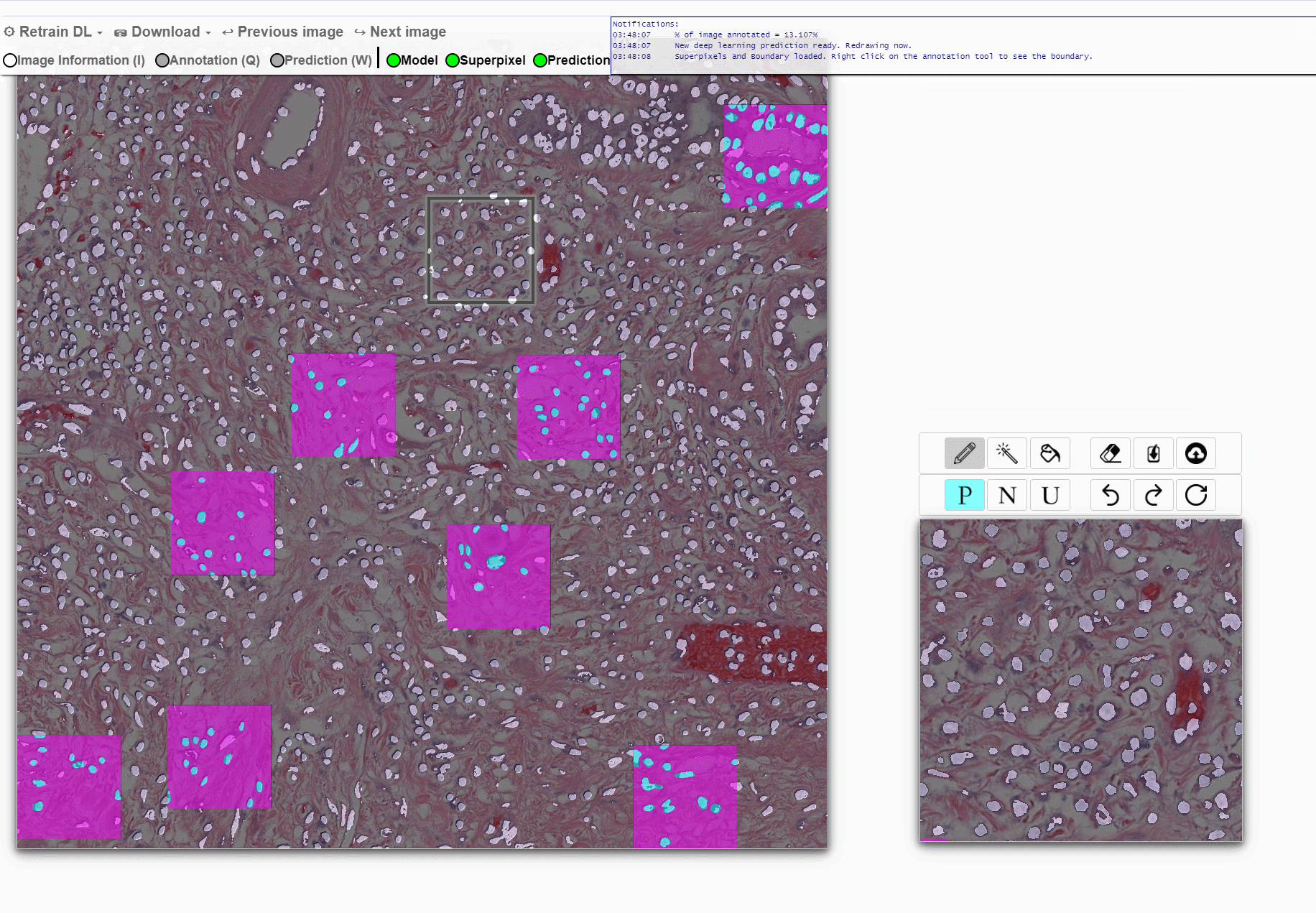
Machine learning approaches for segmentation of histologic primitives (e.g., cell nuclei) in digital pathology (DP) Whole Slide Images (WSI) require large numbers of exemplars. Unfortunately, annotating each object is laborious and often intractable even in moderately sized cohorts. The purpose of the quick annotator is to rapidly bootstrap annotation creation for digital pathology projects by helping identify images and small regions.
Because the classifier is likely to struggle by intentionally focusing in these areas, less pixel level annotations are needed, which significantly improves the efficiency of the users. Our approach involves updating a u-net model while the user provides annotations, so the model is then in real time used to produce. This allows the user to either accept or modify regions of the prediction.
Tested with Python 3.8 and Chrome (errors have been reported with Firefox which are being addressed currently)
Requires:
- Python
- pip
And the following additional python package:
- Flask_SQLAlchemy
- scikit_image
- scikit_learn
- opencv_python_headless
- scipy
- requests
- SQLAlchemy
- torch
- torchvision 10.Flask_Restless
- numpy
- Flask
- umap_learn
- Pillow
- tensorboard
- ttach
- albumentations
- config
You can likely install the python requirements using something like (note python 3+ requirement):
pip3 install -r requirements.txt
Note: The requirements.txt under root directory of cuda version 11.
The library versions have been pegged to the current validated ones. Later versions are likely to work but may not allow for cross-site/version reproducibility
We received some feedback that users could installed torch. Here, we provide a detailed guide to install Torch
The general guides for installing Pytorch can be summarized as following:
- Check your NVIDIA GPU Compute Capability @ https://developer.nvidia.com/cuda-gpus
- Download CUDA Toolkit @ https://developer.nvidia.com/cuda-downloads
- Install PyTorch command can be found @ https://pytorch.org/get-started/locally/
Singularity is a container runtime, like Docker, but it starts from a very different place. It favors integration rather than isolation, while still preserving security restrictions on the container, and providing reproducible images.
Therefore, singularity container is more likely to be an environment where is set up to run QA. However, docker container is more like to be an application where an isolated Quick Annotator is built inside.
It is very common that user could specify a port number preallocated by other users and need to change the port number connecting to QA. When using Docker container, user needs to rebuild the image and start the container. When using Singularity container, user needs to change the port number in the config foler.
Docker is a set of platform as a service products that use OS-level virtualization to deliver software in packages called containers. Containers are isolated from one another and bundle their own software, libraries and configuration files.
In order to use Docker version of QA, user needs:
- Nvidia driver supporting cuda. See documentation, here.
- Docker Engine. See documentation, here
- Nvidia-docker https://github.com/NVIDIA/nvidia-docker
PS: Docker Desktop is an easy-to-install application for your Mac or Windows environment that enables you to build and share containerized applications and microservices. Docker Desktop includes Docker Engine, Docker CLI client, Docker Compose, Notary, Kubernetes, and Credential Helper.
Depending on your cuda version, we provide Dockerfiles for cuda_10 and cuda_11.
To start the server, run either:
docker build -t quick_annotator -f cuda_10/Dockerfile .
or
docker build -t quick_annotator -f cuda_11/Dockerfile .
from the QuickAnnotator folder.
When the docker image is done building, it can be run by typing:
docker run --gpus all -v /data/$CaseID/QuickAnnotator:/opt/QuickAnnotator -p 5555:5555 --shm-size=8G quick_annotator
In the above command, -v /data/$CaseID/QuickAnnotator:/opt/QuickAnnotator mounts the QA on host file system to the QA inside the container. /data/$CaseID/QuickAnnotator should be the QA path on your host file system, /opt/quick_annotator is the QA path inside the container, which is specified in the Dockerfile.
Note: This command will forward port 5555 from the computer to port 5555 of the container, where our flask server is running as specified in the config.ini. The port number should match the config of running QA on host file system.
Singularity provides a single universal on-ramp from developers’ workstations to local resources, the cloud, and all the way to edge.
In order to use Singulariy version of QA, user needs:
Depending on your cuda version, we provide Singularity Recipe files for cuda_10 and cuda_11.
To build the Singularity Image Format (SIF) of QA, users need to ask for --fakeroot privilege from the administrator.
- Users need to set environment variable (the environment variables should be set to different locations according to use cases)
export SINGULARITY_TMPDIR=/mnt/data/home/$CaseID/sing_cache
export SINGULARITY_CACHEDIR=/mnt/data/home/$CaseID/sing_cache
Note: The location for temporary directories defaults to /tmp. The temporary directory used during a build must be on a filesystem that has enough space to hold the entire container image, uncompressed, including any temporary files that are created and later removed during the build. You may need to set SINGULARITY_TMPDIR when building a large container on a system which has a small /tmp filesystem.
-
To build SIF of QA, run either:
singularity build --fakeroot --force /mnt/data/home/$CaseID/QATestSin10.sif cuda_10/Singularity10orsingularity build --fakeroot --force /mnt/data/home/$CaseID/singularityQA11.sif cuda_11/Singularity11from the QuickAnnotator folder.(Note: /mnt/data/home/$CaseID/singularityQA10.sif is the output directory, which could be modified based on users' preference. We recommend users to build the SIF files under data or scratch folder under the assumption that users run Singularity in a server.)
-
When the SIF is done build, it can be run by:
singularity run --bind /data/rxm723/QuickAnnotator:/opt/QuickAnnotator --nv /mnt/data/home/$CaseID/singularity10.sif, where the --nv enables GPU usage.
In the above command, --bind /data/rxm723/QuickAnnotator:/opt/QuickAnnotator mounts the QA on host file system to the QA inside the container. /data/$CaseID/QuickAnnotator should be the QA path on your host file system.
Note: This command will forward you to port 5555 by default, where is specified in the config.ini. If this port is occupied on your machine, for example by another user or process, you will need to change in the config.ini of your QuickAnnotator.
Note: We recommend users to confirm that Nvidia support is successfully enabled before running a singularity container: user should use nvidia-smi command inside the container.
singularity shell --nv /mnt/data/home/$CaseID/singularity10.sif
Nvidia-smi
It is not necessary to specify bind path when checking Nvidia enabling when using singularity shell.
see UserManual for a demo
E:\Study\Research\QA\qqqqq\test1\quick_annotator>python QA.py
By default, it will start up on localhost:5555. Note that 5555 is the port number setting in config.ini and user should confirm {port number} is not pre-occupied by other users on the host.
Warning: virtualenv will not work with paths that have spaces in them, so make sure the entire path to env/ is free of spaces.
There are many modular functions in QA whose behaviors could be adjusted by hyper-parameters. These hyper-parameters can be set in the config.ini file
- [common]
- [flask]
- [cuda]
- [sqlalchemy]
- [pooling]
- [train_ae]
- [train_tl]
- [make_patches]
- [make_embed]
- [get_prediction]
- [frontend]
- [superpixel]
See wiki
Read the related paper in Journal of Pathology - Clinical Research: Quick Annotator: an open-source digital pathology based rapid image annotation tool
Please use below to cite this paper if you find this repository useful or if you use the software shared here in your research.
@misc{miao2021quick,
title={Quick Annotator: an open-source digital pathology based rapid image annotation tool},
author={Runtian Miao and Robert Toth and Yu Zhou and Anant Madabhushi and Andrew Janowczyk},
year={2021},
journal = {The Journal of Pathology: Clinical Research},
issn = {2056-4538}
}
See FAQ