代码量查询:
find . -name "*.c*" -or -name "*.h*" | xargs cat | wc -l##一些开发中遇到的实践经验
1.有override就不要写virtual了
2.注意命名
3.类里面bool写在最后,注意顺序
4.注意传引用还是传值,不能传一个局部变量给一个引用
5.不是简单构造的, 都写到构造函数里面去
6.简单的类变量头文件直接初始化
7.bool变量的命名:如
enableXXX(bool flag):表示一个方法
shouldXXX :表示一个变量8.有时候报奇奇怪怪的语法错误,检查下是否有引头文件
9.shared_ptr get指针,如果对象不为空,get到的是对象,如果对象为空,get到一个nullptr
10.更多地去考虑性能,尽量别传临时对象,传引用
11.有些代码需要适当加注释。
12.注意代码对齐。
13.C++返回引用给lua的话,lua持有的是一个临时变量的指针,可能会有问题
14.C++的void* , 在lua里面可能无法表示, 需要用到 CGE::ByteBuffer
15.std::string类型的构造不需要初始化
16."&&" 的优先级是比 "||" 更高的
17.基础类型不要传引用(比如枚举,int,float)
18.~test() override = default;这样的写法是没必要的可以忽略
19.share_ptr 的resize需要注意内部的resize,需要补齐数据
if (shared_ptrA->size() < size)
{
shared_ptrA->resize(size);
for (auto& f : *shared_ptrA)
{
if (!f)
{
f = MAKE_SHARED(f);
}
}
}20.子类定义变量不要和父类同名,注意父类
21.多次调用使用内联函数
22.C++临时变量的生命周期(const 引用后延长临时变量周期),详细见提交-(1263658b485d1a69ee84513497d50318e71d7257)
23.静态成员函数不能具有“ const”限定符
24.类中定义成员变量:
class Test
{
Test()
{
constructorCount++;
}
virtual ~Test() = default;
static inline static int getConstructorCount()
{
return constructorCount;
}
private:
static int constructorCount;
};
int Test::constructorCount = 0;
// 必须在定义类的文件中对静态成员变量进行一次说明,或初始化。否则编译能通过,链接不能通过。
int main()
{
return 0;
Test *t = new Test[10];
delete[] t;
}25.宏定义:宏定义,本质上就是替换,参数需要加括号
#define COM(A,B) (A)*(B)
// 那么COM(6+5,3)它会换成这样: (6+5)*(3)
// 显然这是和COM宏的意图一致的,但是如是去掉了定义中括号,即写成这样:
#define COM(A,B) A*B
// 那么COM(6+5,3)它就会换成这样: 6+5*3, 这样显然就和宏的意图不符合了。26.虚函数派生类的函数不能带有缺省参数,因为缺省参数是静态编译,而虚函数机制是动态编译
virtual void A(int a = 0); // error
virtual void B(int a); // ok27.使用'= default'定义一个简单的默认构造函数
28.尽可能得使用const auto&,从而减少拷贝
29.%lu表示输出无符号长整型整数 (long unsigned)
30.遍历整个array并且打印:
std::reverse_copy(arr.begin(), arr.end(),
std::ostream_iterator<int>(std::cout, " "));31.头文件千万不要写using namespace xxx,源文件里面可以写
- 对vector向量设置初始容量是很重要的,可以避免数据拷贝,详细测试代码可以见仓库move.cpp
33.Default arguments on virtual or override methods are prohibited,翻译过来就是禁止在虚拟或覆盖的方法上使用默认参数,例如
class B
{
public:
B() = default;
virtual ~B() = default;
virtual void test(int a = 1)
{
std::cout << a << std::endl;
}
};
class D : public B
{
public:
D() = default;
virtual ~D() = default;
void test(int a = 10) override
{
std::cout << a - 1 << std::endl;
}
};
void virtualFuncTest()
{
B* d = new D();
d->test();
/// 输出的是 0,可能用户以为的默认参数是10,所以以为输出是9,需要注意
}
34.避免边界错误
// bad
void f()
{
array<int, 10> a, b;
memset(a.data(), 0, 10); // BAD, and contains a length error (length = 10 * sizeof(int))
memcmp(a.data(), b.data(), 10); // BAD, and contains a length error (length = 10 * sizeof(int))
}
// good
void f()
{
array<int, 10> a, b, c{}; // c is initialized to zero
a.fill(0);
fill(b.begin(), b.end(), 0); // std::fill()
fill(b, 0); // std::ranges::fill()
if ( a == b ) {
// ...
}
}
void f(std::vector<int>& v, std::array<int, 12> a, int i)
{
v[0] = a[0]; // BAD
v.at(0) = a[0]; // OK (alternative 1)
at(v, 0) = a[0]; // OK (alternative 2)
v.at(0) = a[i]; // BAD
v.at(0) = a.at(i); // OK (alternative 1)
v.at(0) = at(a, i); // OK (alternative 2)
}35.不要将memset或者memcpy, memmove, memcmp用于不可复制的参数,这样做会弄乱对象的语义
struct base {
virtual void update() = 0;
};
struct derived : public base {
void update() override {}
};
// bad
void f(derived& a, derived& b) // goodbye v-tables
{
memset(&a, 0, sizeof(derived));
memcpy(&a, &b, sizeof(derived));
memcmp(&a, &b, sizeof(derived));
}
// good
void g(derived& a, derived& b)
{
a = {}; // default initialize
b = a; // copy
if (a == b) do_something(a, b);
}36.std::string用于拥有字符序列
vector<string> readUntil(const string& terminator)
{
vector<string> res;
for (string s; cin >> s && s != terminator; ) // read a word
res.push_back(s);
return res;
}
// C++17: good
// std::string_view或gsl::span<char>提供对字符序列的简单且(可能)安全的访问,而与这些序列的分配和存储方式无关
// note: std::string_view(C++17) 是只读的
vector<string> readUntil(string_view terminator)
{
vector<string> res;
for (string s; cin >> s && s != terminator; ) // read a word
res.push_back(s);
return res;
}
void user(zstring p, const string& s, string_view ss)
{
auto v1 = read_until(p);
auto v2 = read_until(s);
auto v3 = read_until(ss);
// ...
}37.避免std::endl, std::endl大多等价于'\n'或者 "\n"; flush()作为最常用的,它只是通过执行冗余s来减慢输出。printf与C++风格的输出相比,这种放缓可能是显着的 }
cout << "Hello, World!" << endl; // two output operations and a flush
cout << "Hello, World!\n"; // one output operation and no flush
}38.不要坚持return在函数中只有一个语句
// bad
int index2(const char* p)
{
int i;
if (!p)
i = -1; // error indicator
else {
// ... do a lookup to find the index for p
}
return i;
}
// good
template<class T>
// requires Number<T>
string sign(T x) // bad
{
string res;
if (x < 0)
res = "negative";
else if (x > 0)
res = "positive";
else
res = "zero";
return res;
}39.写代码需要表明意图,保证可读性
// bad
void f(vector<string>& v)
{
string val;
cin >> val;
// ...
int index = -1; // bad, plus should use gsl::index
for (int i = 0; i < v.size(); ++i) {
if (v[i] == val) {
index = i;
break;
}
}
}
void f(vector<string>& v)
{
string val;
cin >> val;
// ...
auto p = find(begin(v), end(v), val); // better
// ...
}40.返回值优化rvo
vector<int> f5(int n) // OK: move
{
vector<int> v(n);
// ... initialize v ...
return v;
}
unique_ptr<int[]> f6(int n) // bad: loses n
{
auto p = make_unique<int[]>(n);
// ... initialize *p ...
return p;
}
owner<int*> f7(int n) // bad: loses n and we might forget to delete
{
owner<int*> p = new int[n];
// ... initialize *p ...
return p;
}
41.不要泄露任何资源
// bad
void f(char* name)
{
FILE* input = fopen(name, "r");
// ...
if (something) return; // bad: if something == true, a file handle is leaked
// ...
fclose(input);
}
// good
void f(char* name)
{
ifstream input {name};
// ...
if (something) return; // OK: no leak
// ...
}42.状态后置条件
// bad
int area(int height, int width) { return height * width; } // bad
// good
int area(int height, int width)
{
auto res = height * width;
assert(res > 0);
return res;
}##C++ 编程规范 101条规则、准则与最佳实践 001.了解哪些东西不应该标准化
002.在搞警告级别干净利落地进行编译
003.使用自动构建系统
004.使用版本控制系统
005.一个实体应该只有一个紧凑的职责
006.正确、简单和清晰第一
007.编程中应该知道如何考虑可伸缩性
008.不要进行不成熟的优化
009.不要进行不成熟的劣化
010.尽量减少全局和共享数据
指针是存储对象的内存地址的变量。 指针在 C 和C++中广泛使用,主要有三个目的:
- 在堆上分配新对象
- 将函数传递给其他函数
- 迭代数组或其他数据结构中的元素。
在 C 语言的编程中,原始指针用于所有这些方案。 但是,原始指针是许多严重编程错误的根源。 因此,强烈建议不使用它们,除非它们提供了显著的性能优势,并且对于哪个指针是负责删除对象的拥有指针没有歧义。 现代C++提供用于分配对象的智能指针、用于遍历数据结构的迭代器以及用于传递函数的 lambda 表达式。 通过使用这些语言和库工具而不是原始指针,可以使程序更安全、更易于调试以及更易于理解和维护。
指针是一种类型的变量。 它将对象的地址存储在内存中,并用于访问该对象。 原始指针是一个指针,其生存期不受封装对象(如智能指针)的控制。 可以为原始指针分配另一个非指针变量的地址,也可以为其分配值 nullptr 。 尚未分配值的指针包含随机数据。
还可以取消引用指针以检索它指向的对象的值。 成员访问运算符提供对象成员的访问权限。
指针可指向类型化对象或 void , 当程序在内存中的堆上分配对象时,它将以指针的形式接收该对象的地址。
如果指针(未声明为 const ),则可以递增或递减到内存中的另一个位置。 此操作称为指针算法。C 样式编程中使用它来循环访问数组或其他数据结构中的元素。 const 指针不能指向不同的内存位置,在这种情况下,与引用类似。
/ declare a C-style string. Compiler adds terminating '\0'.
const char* str = "Hello world";
const int c = 1;
const int* pconst = &c; // declare a non-const pointer to const int
const int c2 = 2;
pconst = &c2; // OK pconst itself isn't const
const int* const pconst2 = &c;
// pconst2 = &c2; // Error! pconst2 is const.Const和volatile关键字更改指针的处理方式,const 关键字指定在初始化之后不能修改指针; 之后,该指针将受到保护以防止修改。
volatile 关键字指定与后面的名称关联的值可以通过用户应用程序中的其他操作进行修改。 因此, volatile 关键字适用于在共享内存中声明对象,这些对象可以由多个进程或用于与中断服务例程进行通信的全局数据区域访问。
- unique_ptr:只允许基础指针的一个所有者。 除非你确信需要
shared_ptr,否则请将该指针用作 POCO 的默认选项。 可以移到新所有者,但不会复制或共享。unique_ptr很小且高效;大小是一个指针,它支持用于从 c + + 标准库集合快速插入和检索的右值引用。 头文件:<memory> - shared_ptr:采用引用计数的智能指针。 如果你想要将一个原始指针分配给多个所有者(例如,从容器返回了指针副本又想保留原始指针时),请使用该指针。 直至所有
shared_ptr所有者超出了范围或放弃所有权,才会删除原始指针。 大小为两个指针;一个用于对象,另一个用于包含引用计数的共享控制块。 头文件:<memory>。 - 结合
shared_ptr使用的特例智能指针。weak_ptr提供对一个或多个shared_ptr实例拥有的对象的访问,但不参与引用计数。 如果你想要观察某个对象但不需要其保持活动状态,请使用该实例。 在某些情况下,需要断开shared_ptr实例间的循环引用。 头文件:<memory>。
智能指针详解:
Unique_ptr不共享其指针。 不能将其复制到另一个。
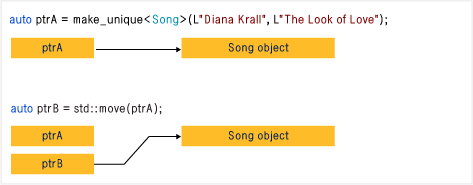
std::move
- static_assert
- 支持右角括号:例如:vector a;
- 扩展的friend声明
- long long
- 类型特征的编译器支持
- auto
- 委托构造函数
- 1,优化cpu:
- (1)图像分块多线程;
- (2)SIMD(neon、SSE2);
- (3)减少IO操作,尽量访问连续的内存地址,增加缓存命中率;
- (4)避免内存重复创建和copy;
- (5)循环展开;
- (6)定点化;
- 2,内存:
- (1)GPU纹理压缩;
- (2)GPU/CPU内存池。
- (3)关注内存峰值。
- 3,GPU(只涉及opengl):
- (1)异步DMA;
- (2)减少draw call次数,减少没必要的gpu指令;
- (3)使用纹理共享方式:graphic buffer(android);
- (4)vs能完成的不在fs上做;
- (5)fs绘制区域大小影响性能较大,优化fragment shader;
- i.小纹理采样和渲染效果做平衡;
- ii.避免非uniform的分支语句;
- iii.低精度性能更优,如果可以的话,要用高精度(美颜,美妆)
- 4,其他:
- 1,CPU和GPU负载均衡,结合具体算法,不依赖的计算过程并行;
- 2,间隔帧计算,如CPU中非必要实时计算模块间隔帧计算。
- 5.从API层面去优化,升级gles3.0,可以使用到新的扩展功能,比如:
- UBO,glclear-glInvalidateFramebuffer组合(使用到了vk以及metal的一些特有概念,比如vk在加载framebuffer的时候有LOP和SOP两个过程,如果使用了DontCare模式,可以降低了图像内存同步的带宽,CPU/GPU同步的效率更高,使得帧率以及cpu占用率均有提升优化,LOP和SOP,及时扔掉不想要的framebuffer数据)
- gles3.0对uniform的if语句具有更高的性能
- 6.通过hook draw call 的方式,逐个分析draw call(在Xcode中对glDrawArray进行断点,看是否符合预期调用)
- 7.采纳一种缓存池的策略,复用纹理,render target
- 8.render target的尺寸会影响内存以及性能
- 9.避免造成等待,提高cpu,gpu利用率,可以提升帧率
- 10.限制帧率(根据情况限制24或者30),避免多余的draw call
- git把多个commit合成一个
git reset -q --soft 6e9a2e92676d404a859321d414cbe30808c84b55
git add .
git commit -m "xxx"
git push- git清缓存
git clean -fix
rm -rf *
git reset —hard
git submodule update --init --recursive- git查看当前commit ID
git rev-parse HEAD- git查看当前commit ID
git rev-parse HEAD- git重新修改当前commit
git commit --amend --no-verify
git push -f###环境安装
13.vulkan 环境配置: 下载地址:https://vulkan.lunarg.com/sdk/home#mac 直接安装即可 1.安装homebrew
/bin/zsh -c "$(curl -fsSL https://gitee.com/cunkai/HomebrewCN/raw/master/Homebrew.sh)"2.安装opencv:
brew install opencv@23.安装qt