The purpose of this repo is to provide a standard dataset for testing traffic observation software on videos from the Carla Simulator. The Python code in this repo creates a number of standard videos with truly accurate ground truth positions for road users in world coordinates. Hopefully, this will allow a more fair comparison between different road user tracking methods. While Carla Simulator does not create perfectly realistic traffic videos, they are hopefully realistic enough to be useful for computer vision and traffic researchers.
The following road user classes are supported:
- Pedestrians
- Bicyclists/Motorbikes
- Cars
- Trucks
- Buses
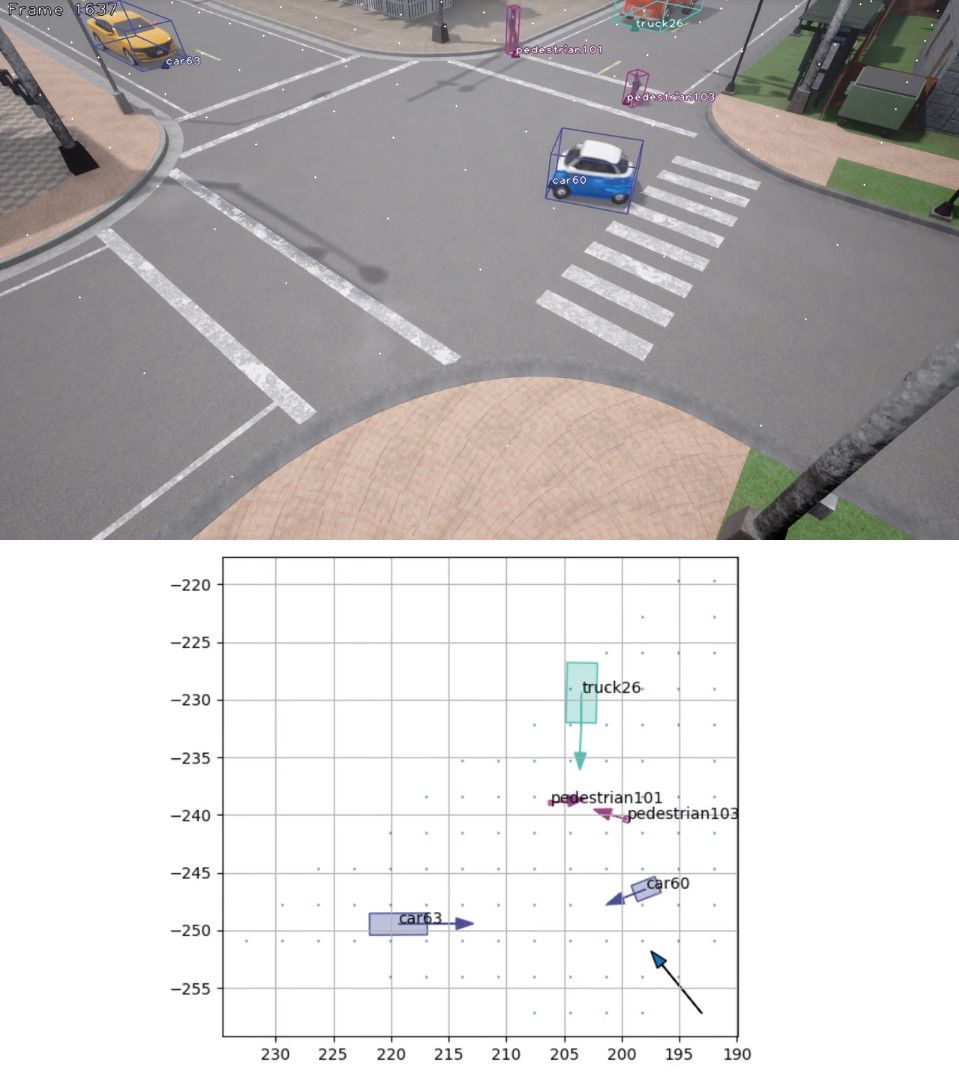
The videos are stored as 720p .jpg files, at 25 FPS. By default, monocular videos are generated, but an option exists for stereo/trinocular or even more cameras through the --cam_setup parameter. There are 40 sequences, each 3000 frames long. These are divided into training/validation/test sets, see sets.txt. The sequences are recorded across several different Carla maps, with a wide variety of camera angles, chosen to be somewhat feasible in a traffic surveillance setting, with the camera placed several metres above the ground and observing an active traffic environment. For each frame in each sequence, there exists a text file containing the ground truth position, in world coordinates, of each road user. The road users have consistent IDs across all frames. Thus this dataset can be used to evaluate world coordinate tracking methods designed for use on road users seen in surveillance cameras, of the kind that is of importance for traffic safety researchers. Each frame is recorded both as an RGB image and as an instance segmentation image.
The UTOCS dataset, and all the code in this repository, is released under the MIT License. See the file LICENSE for details.
If you are unable or unwilling to run the UTOCS code to generate the dataset, you can also download the dataset from this link, with only a monocular view:
It is divided into 17 files, around 4 GiB each. The total size is around 69 GiB. The compression format is 7z.
If you use the UTOCS dataset in your research, please cite this paper: https://ieeexplore.ieee.org/abstract/document/9921949
- Install Carla Simulator 0.9.13
- Start the server with
./CarlaUE4.shin the appropriate folder, and make sure this runs before proceeding - Install Python dependencies with
python3 -m pip install carla==0.9.13 shapely motmetrics scipy numpy imageio, or to include the optional dependencies for visualization do insteadpython3 -m pip install carla==0.9.13 imageio imageio-ffmpeg opencv-python shapely motmetrics scipy numpy matplotlib - While the server is running, execute
python3 start.py. Use the-hflag to see options. - To run the optional visualization, run
python3 visualize.py. Again, use-hto see options.
To evaluate a method against the UTOCS dataset, make sure your method exports to the following JSON format:
A folder, typically named after the method itself, should contain one subfolder for each sequence (0000, 0001 and so on). Each such folder should contain .json files for each frame, called 000000.json, 000001.json and so on. These files should be JSON formatted, as a list containing objects with (at least) the following entries:
"type"- the road user class ("car", "bicyclist", "pedestrian", "truck" or "bus")."id"- ID of that road user, should be consistent across frames. Does obviously not need to match the ground truth IDs!"x","y"and"z": The x, y and z position of the lower center point of the road user (touching the ground)."l","w"and"h": The length (in the forward direction), width and height (upwards) of the road user. The height is currently not used."forward_x","forward_y"and"forward_z": A normalized vector for the direction the road user is facing, representing the orientation of the road user.
The format is essentially the same as how UTOCS stores the ground truth.
To run evaluation, simply run python3 eval.py and the MOTA across all sequences will be presented in the terminal, using either IoU or Euclidean metrics. Run python3 eval.py -h to see all options.
- Note that Carla Simulator has a tendency to crash if left to run for several hours. If that happens, use the
--rangeparameter tostart.pyto specify which scenarios still need to be generated, so that you do not need to run all sequences in a single go. - When generating images with multiple cameras, make sure to use quotes (
') around the argument. Otherwise, your shell will likely interpret the semicolons (;) as splitting the different commands. An example of a correct command for stereo images ispython3 start.py --cam_setup '0,0,0;0.5,0,0', which will give you a stereo setup with 0.5 m between the two cameras, horizontally. The format uses three coordinates to allow exotic camera configurations; to make a stereo camera where the two cameras are placed above each other, use something like0,0,0;0,0.5;0and similarly,0,0,0;0,0,0.5will give a setup where one of the cameras is placed in front of the other one (which is somewhat unrealistic). - The tracking method to be evaluated is allowed (and supposed) to use the camera calibration and ground points for computing the tracks. The method is not allowed to use the positions text files from the test set in any way prior to evaluation.
- It is the responsibility of your method to remove tracks without significant motion, or those that are further than 50 metres away from the camera center of camera 0, or those who appear to have a height for lower than 15 pixels in camera 0.
- The instance segmentation images generated by Carla are not entirely intuitive to understand. If the value in the third channel (B) is 4, that means it's a human, either a pedestrian or a person sitting on a bike. If the value is 10, it's a vehicle (bike/car/bus/truck). The R and G channels contain the IDs of the road user, which is consistent across for bicyclists (so the person sitting on a bike and the bike itself get the same ID). UTOCS currently does nothing to process this data, so there is currently no automatic association between these segmentations and the corresponding road user in the ground truth.