公众号文章:命名实体识别常用算法及工程实现
公众号文章:命名实体识别开源项目V4.0版本
此仓库是基于Tensorflow2.3的NER任务项目,支持BiLSTM-Crf、预训练模型-BiLSTM-Crf、预训练模型-Crf,可对Bert进行微调,提供可配置文档,配置完可直接运行。
NER除了CRF范式还有指针范式,做NER的朋友可以横向对比,可参考另外一个项目(基于torch框架的)entity_extractor_by_pointer
| 日期 | 版本 | 描述 |
|---|---|---|
| 2020-01-12 | v1.0.0 | 初始仓库 |
| 2020-04-08 | v1.1.0 | 重构项目代码,添加必要的注释 |
| 2020-04-13 | v1.2.0 | 分别打印出每一个实体类别的指标 |
| 2020-09-09 | v2.0.0 | 更新到tensorflow2.3版本 |
| 2020-09-13 | v3.0.0 | 增加Bert做embedding,通过配置支持BiLSTM-Crf和Bert-BiLSTM-Crf两种模型的训练与预测 |
| 2021-04-21 | v3.0.1 | 添加中断之后再训练逻辑、通过配置可选GPU和CPU、bug-fix |
| 2021-04-25 | v3.1.0 | 使用tf.data.Dataset包装数据,合并数据处理类 |
| 2021-04-25 | v3.1.1 | bug-fix:读取token出现KeyError |
| 2021-06-29 | v4.0.0 | 重构项目代码,增加对Bert-CRF的支持以及其和Bert-Bilstm-CRF中对Bert的微调的支持 |
| 2022-04-11 | v5.0.0 | 增加测试集批量测试、增加一个idcnn模型、支持选择不同的预训练模型、支持两种对抗学习、保存pb格式 |
- tensorflow-gpu==2.3.0
- tensorflow-addons==0.15.0
- transformers==4.6.1
- tqdm==4.62.3
推荐使用GPU加速训练,其他环境见requirements.txt
人民日报语料
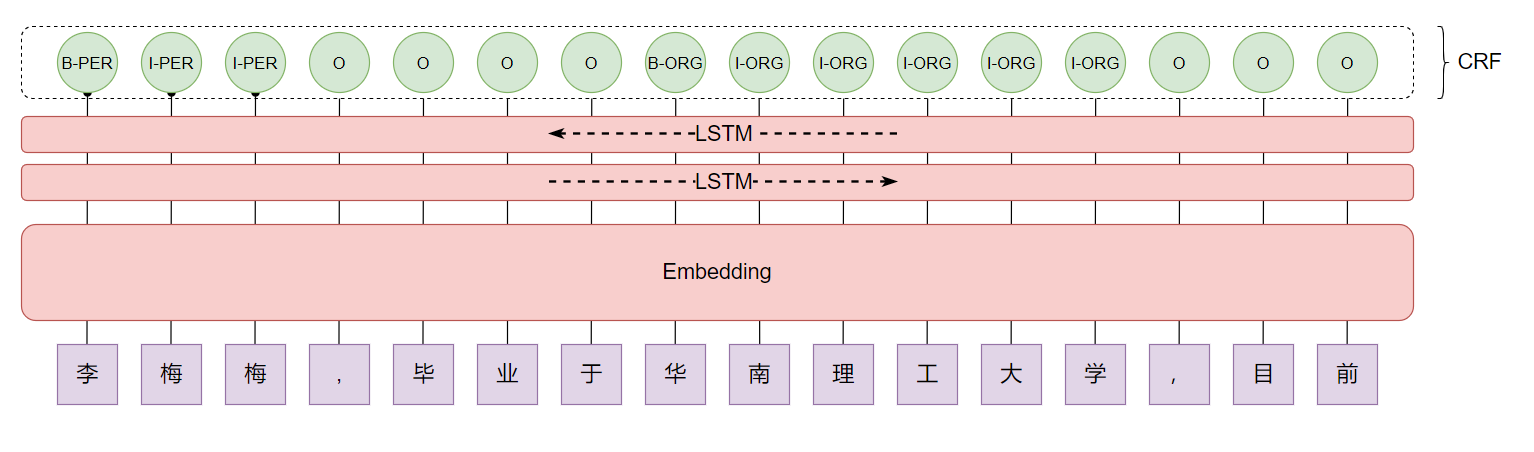
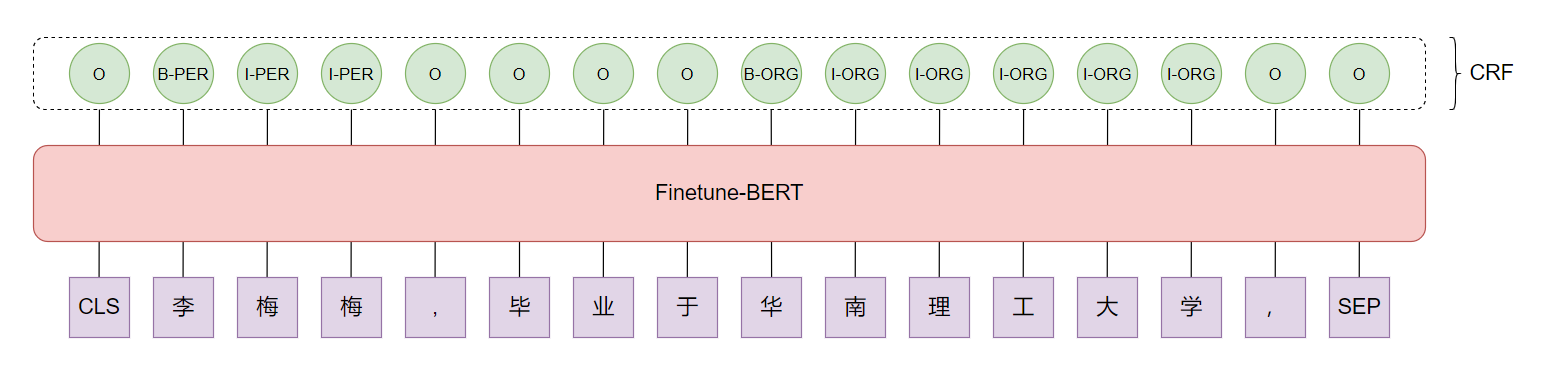
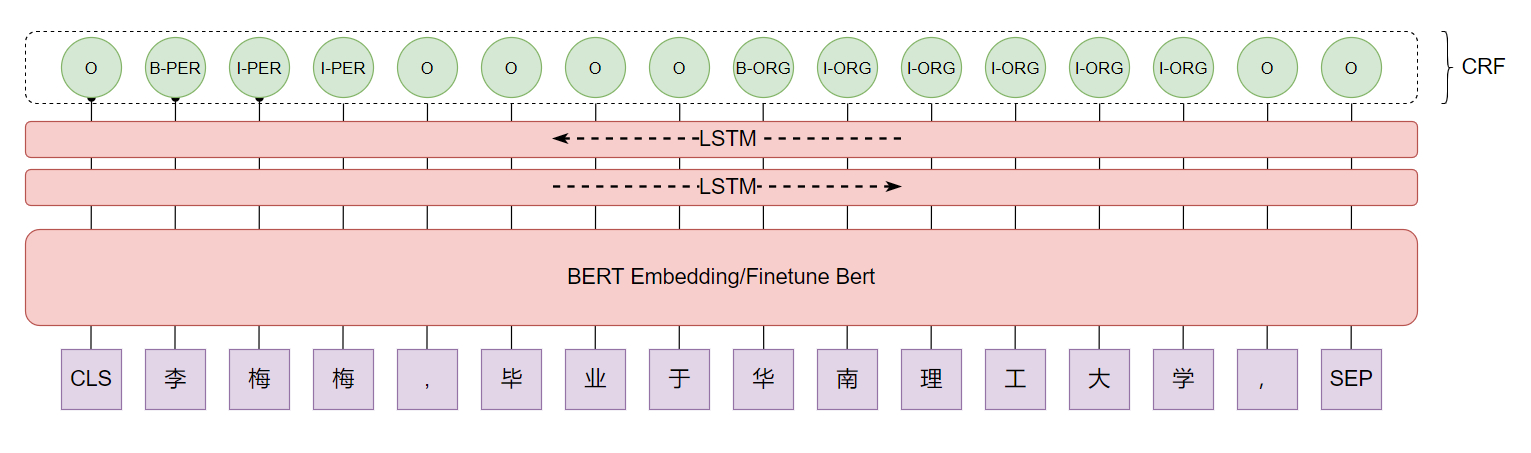
最通俗易懂的BiLSTM-CRF模型中的CRF层介绍
CRF Layer on the Top of BiLSTM - 1
CRF层需要使用viterbi译码法,知乎上这个答案比较容易理解
【step1】 训练之前请在data目录下面建立自己的数据文件夹,然后在配置里的datasets_fold修改下你的数据文件夹地址,将已经标注好的数据切割好训练(train.csv)、验证集(dev.csv)放入你的数据目录下(这里只需要放这两个文件就好,lab2id和token2id两个文件不需要你自己定义,会自己生成),此处请修改配置里面的train_file和dev_file为自己的数据集文件名,如果只提供训练集将会有程序自己按照9:1切割训练集与验证集;
【step2】 配置好vocabs_dir和log_dir两个地址,它们分别对应存放词表生成的文件夹和记录训练过程日志的文件夹,demo数据是把它们放到了自己的数据文件夹下面,你可以改成自己想要的位置;
【step3】 配置好新的checkpoints_dir和checkpoint_name,前者是存放模型的文件夹,后面是模型文件的名字,因为项目是可以在原始模型上继续训练的,所以如果是新的数据集或者想从头训练一定要改!这是很多人运行报错的原因,因为你自己的数据和配置跑在了原来的模型上;
【step4】 在system.config的Datasets(Input/Output)下配置好分隔符,在system.config的Labeling Scheme配置标注模式,在system.config的Model Configuration/Training Settings下配置模型参数和训练参数。
设定system.config的Status中的为train:
################ Status ################
mode=train
# string: train/interactive_predict
是否使用预训练模型(选择True/False):
use_pretrained_model=True
预训练模型的类型:
pretrained_model=Bert
是否微调预训练模型:
finetune=True
使用bilstm或者idcnn:
use_middle_model=True
middle_model=bilstm
# bilstm/idcnn
模型配置
| 模型 | use_pretrained_model | pretrained_model | use_middle_model | middle_model |
|---|---|---|---|---|
| BiLstm+Crf | False | None | True | bilstm |
| IDCNN+Crf | False | None | True | idcnn |
| Bert+BiLstm+Crf | True | Bert | True | bilstm |
| Bert+IDCNN+Crf | True | Bert | True | idcnn |
| Finetune-Bert+Crf | True | Bert | False | None |
| Finetune-Bert+BiLstm+Crf | True | Bert | True | bilstm |
| Finetune-Bert+IDCNN+Crf | True | Bert | True | idcnn |
运行main.py开始训练。
- Bilstm-CRF模型下效果
- Finetune-Bert-CRF模型下效果
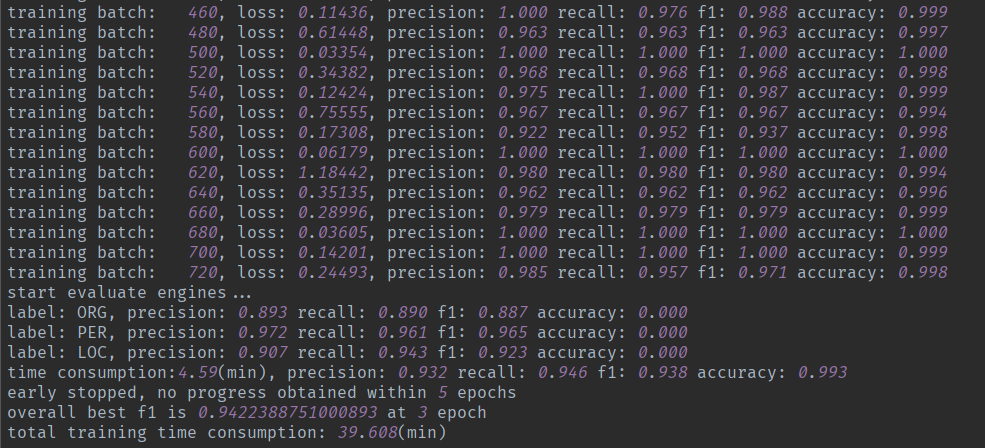
- Bert-Blism-CRF模型下效果
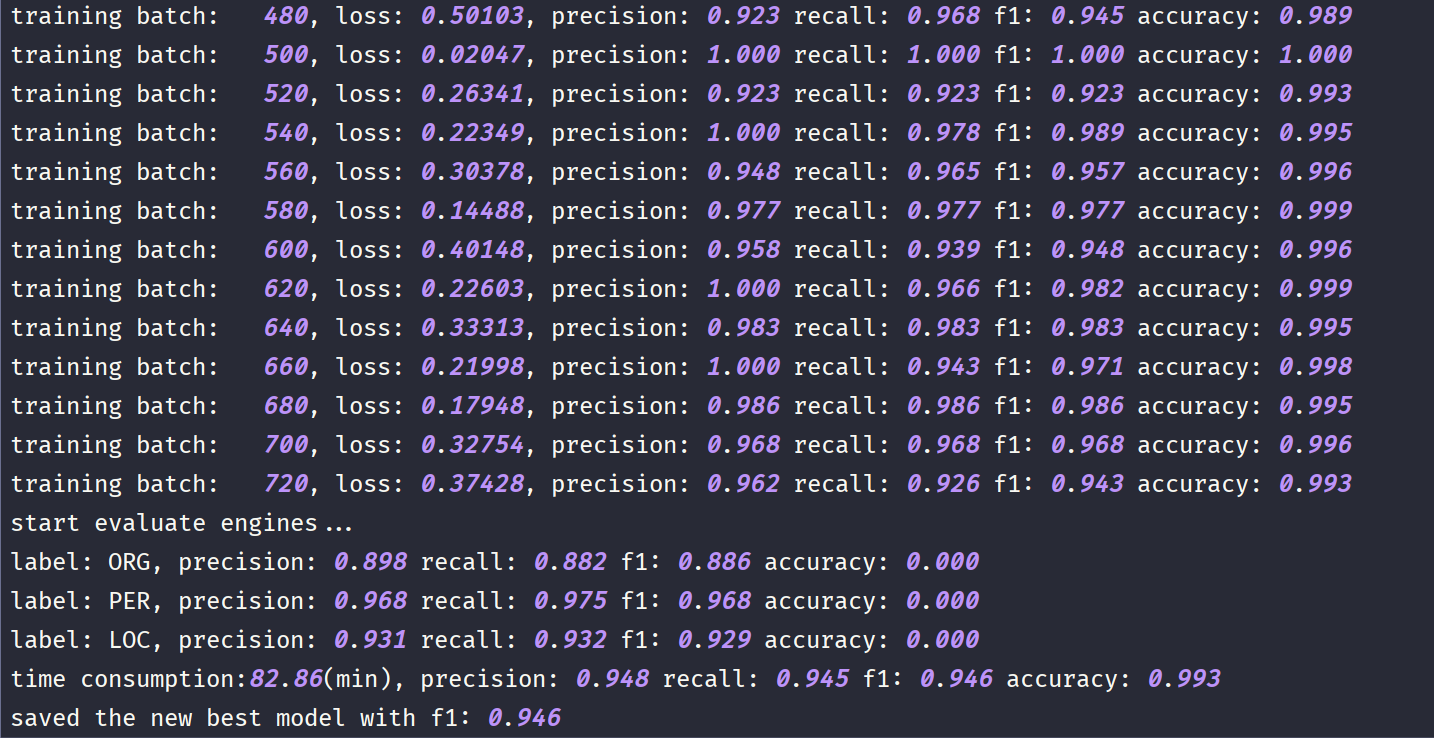
注(1):这里使用的transformers包加载Bert,初次使用的时候会自动下载Bert的模型
注(2):使用Bert-Bilstm-CRF时候max_sequence_length不能超过512并且embedding_dim默认为768
注(3):微调Bert的时候learning_rate改小,设置为5e-5比较好,很多人因为learning_rate太大不收敛
仓库中已经训练好了Bilstm-CRF和Bert-Bilstm-CRF两个模型在同一份数据集上的参数,可直接进行试验,两者位于checkpoints/目录下
- 使用Bilstm-CRF模型时使用bilstm-crf/里的system.config配置
- 使用Bert-Bilstm-CRF模型时使用bert-bilsm-crf/里的system.config配置
将对应的配置替换掉当前的配置。
最后,运行main.py开始在线预测。
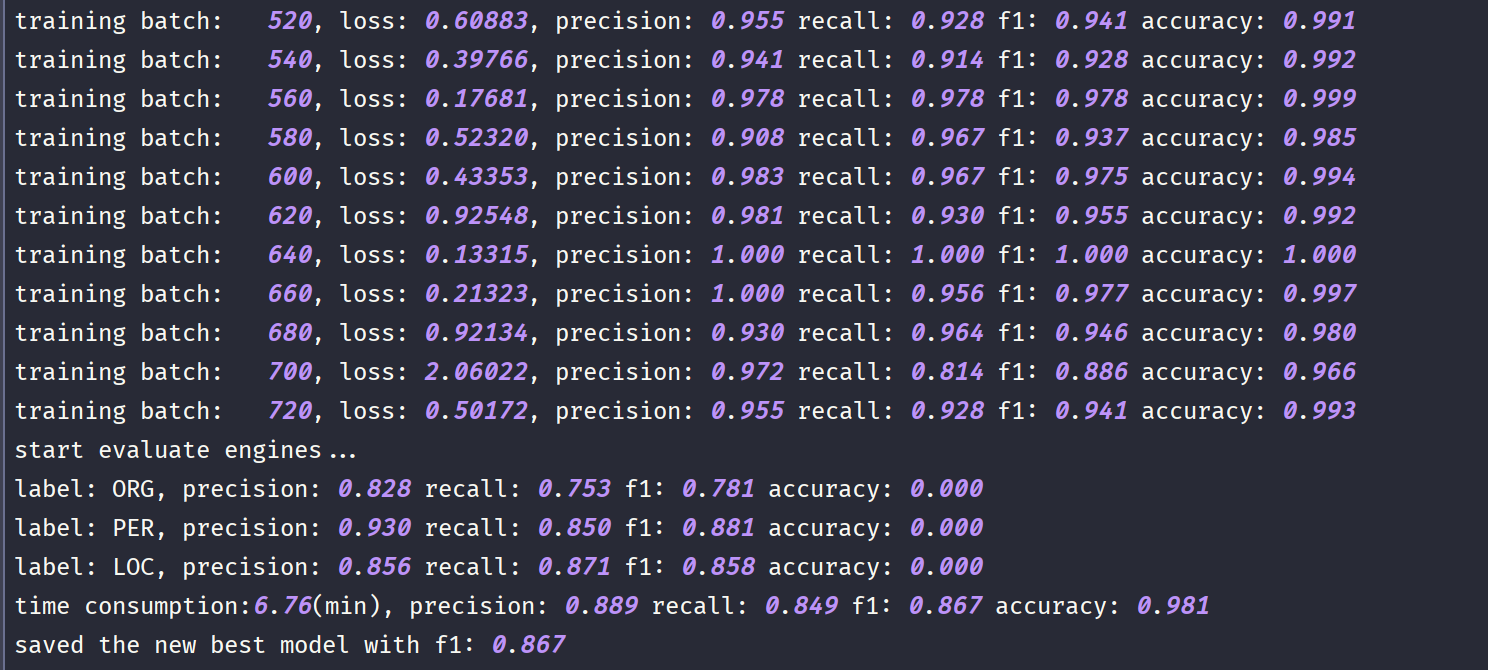
下图为在线预测结果,你可以移植到自己项目里面做成对外接口。
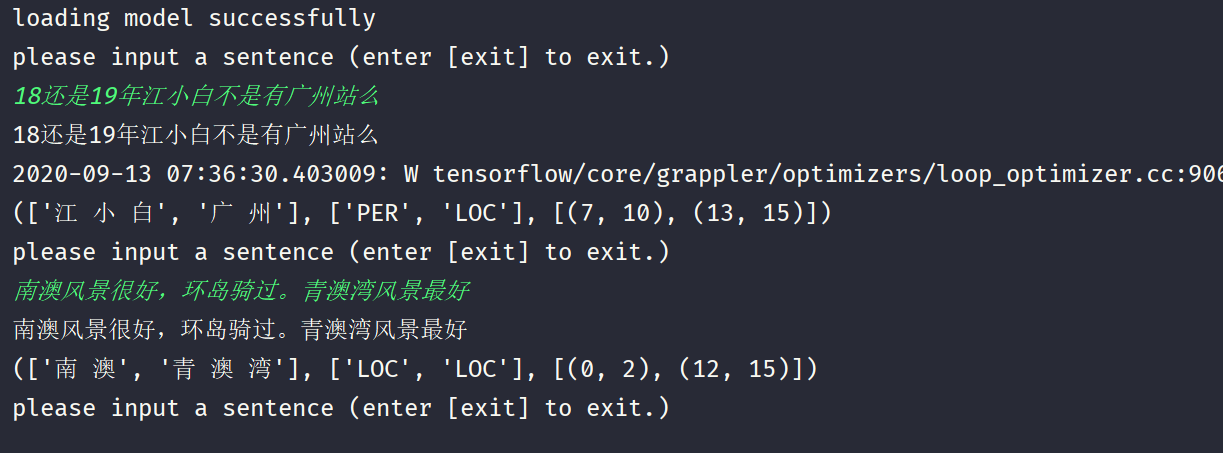
将测试集放到你的数据目录下(测试集和训练集文件格式一样),并修改配置如下:
################ Status ################
mode=test
# string: train/interactive_predict/test
################ Datasets(Input/Output) ################
# 此处展示的是demo数据集所在的文件夹,训练自己数据前请自己设置一个文件夹
datasets_fold=data/example_datasets
train_file=train.csv
dev_file=dev.csv
test_file=test.csv
相关问题欢迎在公众号反馈:
