![]()

![]()




Ignite is a high-level library to help with training neural networks in PyTorch:
- ignite helps you write compact but full-featured training loops in a few lines of code
- you get a training loop with metrics, early-stopping, model checkpointing and other features without the boilerplate
Below we show a side-by-side comparison of using pure pytorch and using ignite to create a training loop to train and validate your model with occasional checkpointing:
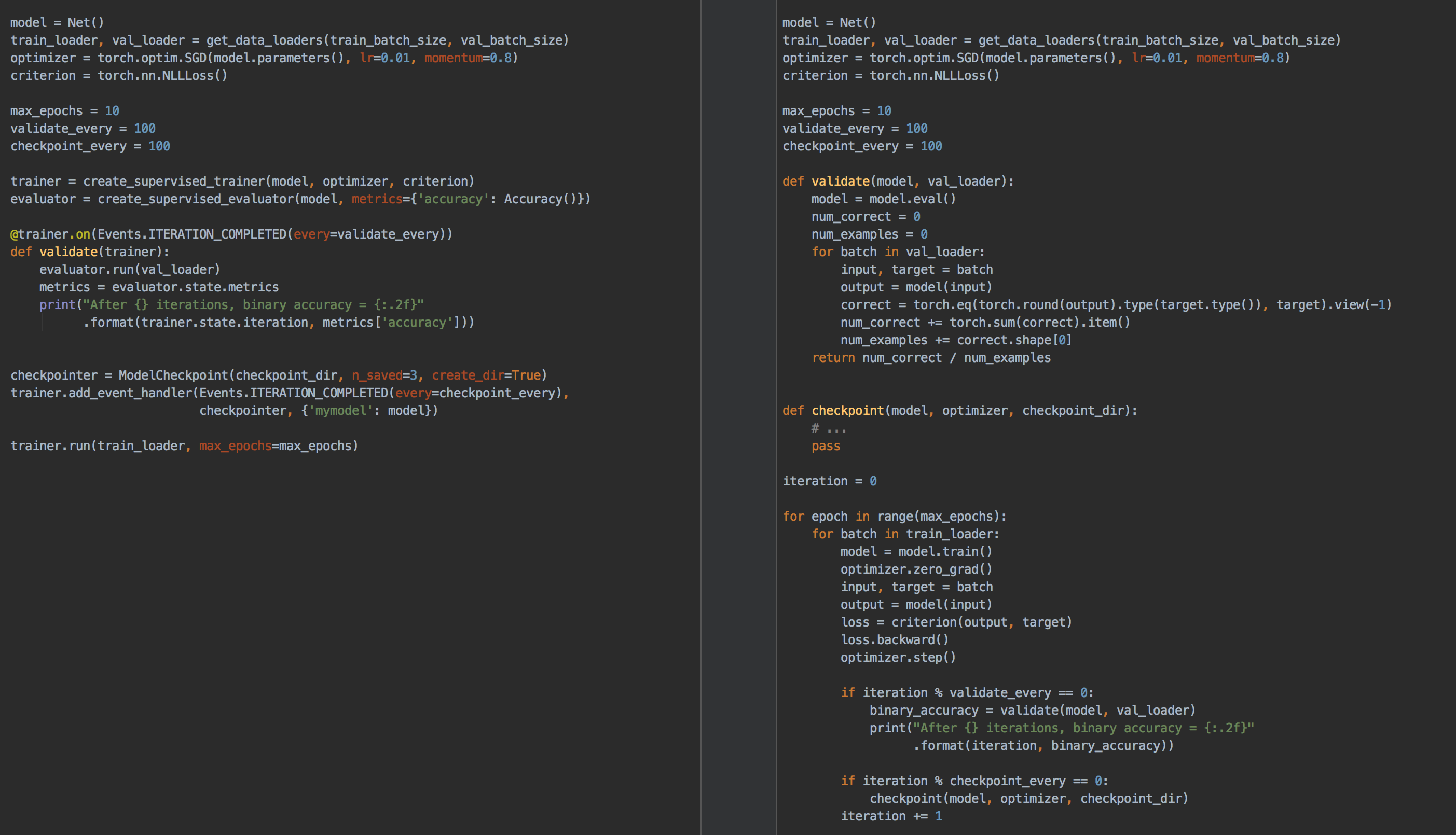
As you can see, the code is more concise and readable with ignite. Furthermore, adding additional metrics, or things like early stopping is a breeze in ignite, but can start to rapidly increase the complexity of your code when "rolling your own" training loop.
- Installation
- Why Ignite?
- Documentation
- Structure
- Examples
- Communication
- Contributing
- Projects using Ignite
- About the team
From pip:
pip install pytorch-ignite
From conda:
conda install ignite -c pytorch
From source:
pip install git+https://github.com/pytorch/ignite
From pip:
pip install --pre pytorch-ignite
From conda (this suggests to install pytorch nightly release instead of stable version as dependency):
conda install ignite -c pytorch-nightly
Ignite's high level of abstraction assumes less about the type of network (or networks) that you are training, and we require the user to define the closure to be run in the training and validation loop. This level of abstraction allows for a great deal more of flexibility, such as co-training multiple models (i.e. GANs) and computing/tracking multiple losses and metrics in your training loop.
The cool thing with handlers is that they offer unparalleled flexibility (compared to say, callbacks). Handlers can be
any function: e.g. lambda, simple function, class method etc. The first argument can be optionally engine, but not necessary.
Thus, we do not require to inherit from an interface and override its abstract methods which could unnecessarily bulk
up your code and its complexity.
Examples
trainer.add_event_handler(Events.STARTED, lambda _: print("Start training"))
# attach handler with args, kwargs
mydata = [1, 2, 3, 4]
logger = ...
def on_training_ended(data):
print("Training is ended. mydata={}".format(data))
# User can use variables from another scope
logger.info("Training is ended")
trainer.add_event_handler(Events.COMPLETED, on_training_ended, mydata)
# call any number of functions on a single event
trainer.add_event_handler(Events.COMPLETED, lambda engine: print("OK"))
@trainer.on(Events.ITERATION_COMPLETED)
def log_something(engine):
print(engine.state.output)Examples
# run the validation every 5 epochs
@trainer.on(Events.EPOCH_COMPLETED(every=5))
def run_validation():
# run validation
# change some training variable once on 20th epoch
@trainer.on(Events.EPOCH_STARTED(once=20))
def change_training_variable():
# ...
# Trigger handler with customly defined frequency
@trainer.on(Events.ITERATION_COMPLETED(event_filter=first_x_iters))
def log_gradients():
# ...Examples
Events can be stacked together to enable multiple calls:
@trainer.on(Events.COMPLETED | Events.EPOCH_COMPLETED(every=10))
def run_validation():
# ...Examples
Custom events related to backward and optimizer step calls:
class BackpropEvents(EventEnum):
BACKWARD_STARTED = 'backward_started'
BACKWARD_COMPLETED = 'backward_completed'
OPTIM_STEP_COMPLETED = 'optim_step_completed'
def update(engine, batch):
# ...
loss = criterion(y_pred, y)
engine.fire_event(BackpropEvents.BACKWARD_STARTED)
loss.backward()
engine.fire_event(BackpropEvents.BACKWARD_COMPLETED)
optimizer.step()
engine.fire_event(BackpropEvents.OPTIM_STEP_COMPLETED)
# ...
trainer = Engine(update)
trainer.register_events(*BackpropEvents)
@trainer.on(BackpropEvents.BACKWARD_STARTED)
def function_before_backprop(engine):
# ...- Complete snippet can be found here.
- Another use-case of custom events: trainer for Truncated Backprop Through Time.
-
Metrics for various tasks: Precision, Recall, Accuracy, Confusion Matrix, IoU etc, ~20 regression metrics.
-
Users can also compose their own metrics with ease from existing ones using arithmetic operations or torch methods:
precision = Precision(average=False)
recall = Recall(average=False)
F1_per_class = (precision * recall * 2 / (precision + recall))
F1_mean = F1_per_class.mean() # torch mean method
F1_mean.attach(engine, "F1")- Stable API documentation and an overview of the library: https://pytorch.org/ignite/
- Development version API documentation: https://pytorch.org/ignite/master/
- FAQ and "Questions on Github".
- Project's Roadmap
- 8 Creators and Core Contributors Talk About Their Model Training Libraries From PyTorch Ecosystem
- Ignite Posters from Pytorch Developer Conferences:
- ignite: Core of the library, contains an engine for training and evaluating, all of the classic machine learning metrics and a variety of handlers to ease the pain of training and validation of neural networks!
- ignite.contrib: The Contrib directory contains additional modules that can require extra dependencies. Modules vary from TBPTT engine, various optimisation parameter schedulers, logging handlers and a metrics module containing many regression metrics (ignite.contrib.metrics.regression)!
The code in ignite.contrib is not as fully maintained as the core part of the library.
We provide several examples ported from
pytorch/examples using ignite to display how it helps to write compact and
full-featured training loops in a few lines of code:
Basic neural network training on MNIST dataset with/without ignite.contrib module:
- MNIST with ignite.contrib TQDM/Tensorboard/Visdom loggers
- MNIST with native TQDM/Tensorboard/Visdom logging
Text Classification using Convolutional Neural Networks
Training a small variant of ResNet on CIFAR10 in various configurations: 1) single gpu, 2) single node multiple gpus, 3) multiple nodes and multilple gpus.
Inspired by torchvision/references, we provide several reproducible baselines for vision tasks:
Features:
- Distributed training with mixed precision by nvidia/apex
- Experiments tracking with MLflow or Polyaxon
-
GitHub issues: questions, bug reports, feature requests, etc.
-
Discuss.PyTorch, category "Ignite".
-
PyTorch Slack at #pytorch-ignite channel. Request access.
We have created a form for "user feedback". We appreciate any type of feedback and this is how we would like to see our community:
- If you like the project and want to say thanks, this the right place.
- If you do not like something, please, share it with us and we can see how to improve it.
Thank you !
Please see the contribution guidelines for more information.
As always, PRs are welcome :)
- BatchBALD: Efficient and Diverse Batch Acquisition for Deep Bayesian Active Learning
- A Model to Search for Synthesizable Molecules
- Localised Generative Flows
- Extracting T Cell Function and Differentiation Characteristics from the Biomedical Literature
- Variational Information Distillation for Knowledge Transfer
- XPersona: Evaluating Multilingual Personalized Chatbot
- CNN-CASS: CNN for Classification of Coronary Artery Stenosis Score in MPR Images
- Bridging Text and Video: A Universal Multimodal Transformer for Video-Audio Scene-Aware Dialog
- Adversarial Decomposition of Text Representation
- State-of-the-Art Conversational AI with Transfer Learning
- Tutorial on Transfer Learning in NLP held at NAACL 2019
- Deep-Reinforcement-Learning-Hands-On-Second-Edition, published by Packt
- Once Upon a Repository: How to Write Readable, Maintainable Code with PyTorch
- Project MONAI - AI Toolkit for Healthcare Imaging
- DeepSeismic - Deep Learning for Seismic Imaging and Interpretation
- Nussl - a flexible, object oriented Python audio source separation library
- Implementation of "Attention is All You Need" paper
- Implementation of DropBlock: A regularization method for convolutional networks in PyTorch
- Kaggle Kuzushiji Recognition: 2nd place solution
- Unsupervised Data Augmentation experiments in PyTorch
- Hyperparameters tuning with Optuna
- Logging with ChainerUI
See other projects at "Used by"
If your project implements a paper, represents other use-cases not covered in our official tutorials, Kaggle competition's code or just your code presents interesting results and uses Ignite. We would like to add your project in this list, so please send a PR with brief description of the project.
Project is currently maintained by a team of volunteers. See the "About us" page for a list of core contributors.