If interested, join the slack workspace where the paper is discussed, issues are worked through, and more! Click this link to join.
PyTorch implementation for this paper.
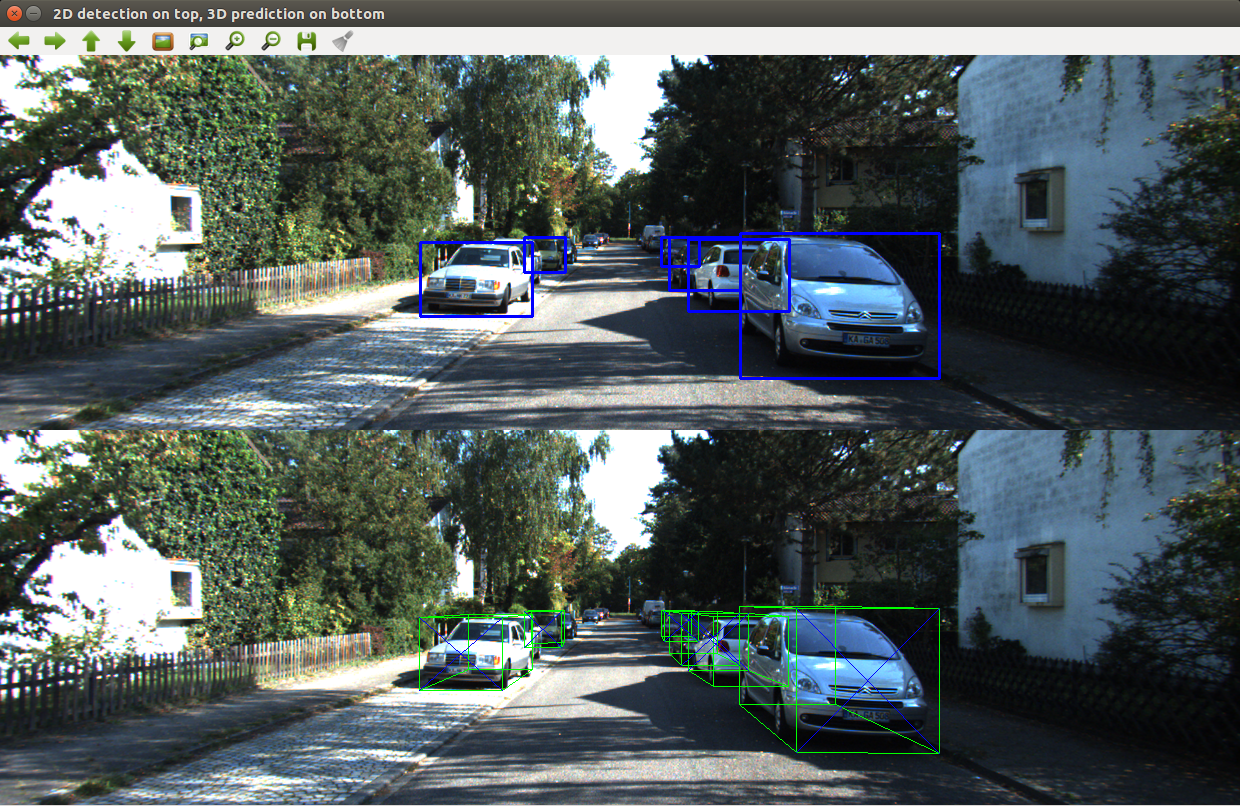
At the moment, it takes approximately 0.4s per frame, depending on the number of objects
detected. An improvement will be speed upgrades soon. Here is the current fastest possible:

- PyTorch
- Cuda
- OpenCV >= 3.4.3
In order to download the weights:
cd weights/
./get_weights.sh
This will download pre-trained weights for the 3D BoundingBox net and also YOLOv3 weights from the official yolo source.
If script is not working: pre trained weights and YOLO weights
To see all the options:
python Run.py --help
Run through all images in default directory (eval/image_2/), optionally with the 2D bounding boxes also drawn. Press SPACE to proceed to next image, and any other key to exit.
python Run.py [--show-yolo]
Note: See training for where to download the data from
There is also a script provided to download the default video from Kitti in ./eval/video. Or,
download any Kitti video and corresponding calibration and use --image-dir and --cal-dir to
specify where to get the frames from.
python Run.py --video [--hide-debug]
First, the data must be downloaded from Kitti. Download the left color images, the training labels, and the camera calibration matrices. Total is ~13GB. Unzip the downloads into the Kitti/ directory.
python Train.py
By default, the model is saved every 10 epochs in weights/. The loss is printed every 10 batches. The loss should not converge to 0! The loss function for the orientation is driven to -1, so a negative loss is expected. The hyper-parameters to tune are alpha and w (see paper). I obtained good results after just 10 epochs, but the training script will run until 100.
The PyTorch neural net takes in images of size 224x224 and predicts the orientation and relative dimension of that object to the class average. Thus, another neural net must give the 2D bounding box and object class. I chose to use YOLOv3 through OpenCV. Using the orientation, dimension, and 2D bounding box, the 3D location is calculated, and then back projected onto the image.
There are 2 key assumptions made:
- The 2D bounding box fits very tightly around the object
- The object has ~0 pitch and ~0 roll (valid for cars on the road)
- Train custom YOLO net on the Kitti dataset
- Some type of Pose visualization (ROS?)
I originally started from a fork of this repo, and some of the original code still exists in the training script.