Training and inference scripts for the vocoder models in A Comparison of Discrete and Soft Speech Units for Improved Voice Conversion. For more details see soft-vc. Audio samples can be found here. Colab demo can be found here.
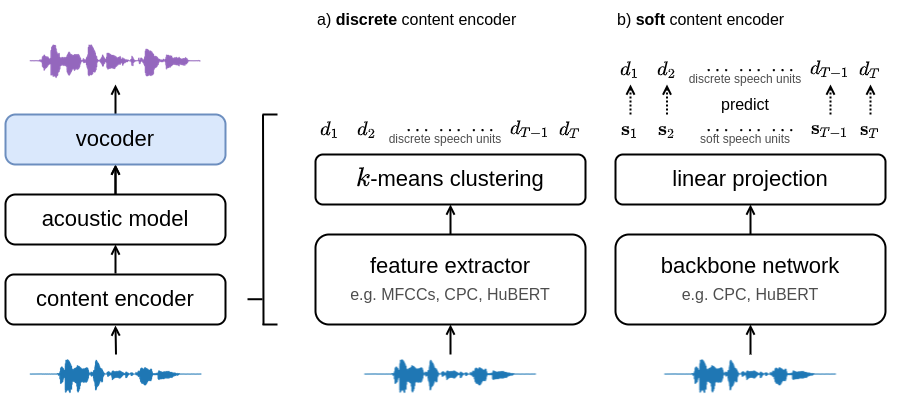
Fig 1: Architecture of the voice conversion system. a) The discrete content encoder clusters audio features to produce a sequence of discrete speech units. b) The soft content encoder is trained to predict the discrete units. The acoustic model transforms the discrete/soft speech units into a target spectrogram. The vocoder converts the spectrogram into an audio waveform.
import torch
import numpy as np
# Load checkpoint
hifigan = torch.hub.load("bshall/hifigan:main", "hifigan_hubert_soft").cuda()
# Load mel-spectrogram
mel = torch.from_numpy(np.load("path/to/mel")).unsqueeze(0).cuda()
# Generate
wav, sr = hifigan.generate(mel)usage: generate.py [-h] {soft,discrete,base} in-dir out-dir
Generate audio for a directory of mel-spectrogams using HiFi-GAN.
positional arguments:
{soft,discrete,base} available models (HuBERT-Soft, HuBERT-Discrete, or
Base).
in-dir path to input directory containing the mel-
spectrograms.
out-dir path to output directory.
optional arguments:
-h, --help show this help message and exit
Download and extract the LJSpeech dataset. The training script expects the following tree structure for the dataset directory:
└───wavs
├───dev
│ ├───LJ001-0001.wav
│ ├───...
│ └───LJ050-0278.wav
└───train
├───LJ002-0332.wav
├───...
└───LJ047-0007.wav
The train and dev directories should contain the training and validation splits respectively. The splits used for the paper can be found here.
Resample the audio to 16kHz using the resample.py script:
usage: resample.py [-h] [--sample-rate SAMPLE_RATE] in-dir out-dir
Resample an audio dataset.
positional arguments:
in-dir path to the dataset directory.
out-dir path to the output directory.
optional arguments:
-h, --help show this help message and exit
--sample-rate SAMPLE_RATE
target sample rate (default 16kHz)
for example:
python reample.py path/to/LJSpeech-1.1/ path/to/LJSpeech-Resampled/
usage: train.py [-h] [--resume RESUME] [--finetune] dataset-dir checkpoint-dir
Train or finetune HiFi-GAN.
positional arguments:
dataset-dir path to the preprocessed data directory
checkpoint-dir path to the checkpoint directory
optional arguments:
-h, --help show this help message and exit
--resume RESUME path to the checkpoint to resume from
--finetune whether to finetune (note that a resume path must be given)
If you found this work helpful please consider citing our paper:
@inproceedings{
soft-vc-2022,
author={van Niekerk, Benjamin and Carbonneau, Marc-André and Zaïdi, Julian and Baas, Matthew and Seuté, Hugo and Kamper, Herman},
booktitle={ICASSP},
title={A Comparison of Discrete and Soft Speech Units for Improved Voice Conversion},
year={2022}
}
This repo is based heavily on https://github.com/jik876/hifi-gan.