到目前为止,SLAM的方案都处于特征点或者像素的层级关于这些特征点或像素到底来自于什么东西,我们一无所知。这使得计算机视觉中的SLAM与我们人类的做法不怎么相似, 至少我们自己从来看不到特征点,也不会去根据特征点判断自身的运动方向。 我们看到的是一个个物体,通过左右眼判断它们的远近,然后基于它们在图像当中的运动推测相机的移动。很久之前,研究者就试图将物体信息结合到SLAM中。另一方面,把标签信息引入到BA或优化端的目标函数和约束中,我们可以结合特征点的位置与标签信息进行优化。这些工作都可以称为语义SLAM。 语义和SLAM看似是两个独立的模块,实则不然。在很多应用中,二者相辅相成。一方面,语义信息可以帮助SLAM提高建图和定位的精度,特别是对于复杂的动态场景。传统SLAM的建图和定位多是基于像素级别的几何匹配。 借助语义信息,我们可以将数据关联从传统的像素级别升级到物体级别,提升复杂场景下的精度。另一方面,借助SLAM技术计算出物体之间的位置约束,可以对同一物体在不同角度, 不同时刻的识别结果进行一致性约束,从而提高语义理解的精度。 综合来说,SLAM和语义的结合点主要有两个方面: 1、 语义帮助SLAM。传统的物体识别、分割算法往往只考虑一幅图,而在SLAM中我们拥有一台移动的相机。如果我们把运动过程中的图片都带上物体标签,就能得到一个带有标签的地图。另外,物体信息亦可为回环检测、BA优化带来更多的条件。 2、SLAM帮助语义。 物体识别和分割都需要大量的训练数据。要让分类器识别各个角度的物体,需要从不同视角采集该物体的数据,然后进行人工标定,非常辛苦。 而SLAM中,由于我们可以估计相机的运动,可以自动地计算物体在图像中的位置,节省人工标定的成本。如果有自动生成的带高质量标注的样本数据,能够很大程度上加速分类器的训练过程。
3D-SIS:RGB-D扫描的3D语义实例分割 摘要: 本文介绍了3D-SIS,一种商用RGB-D扫描中的3D语义实例分割的新型神经网络架构,其核心**是共同学习几何和颜色信号,从而实现准确的实例预测。作者观察到大多数计算机视觉应用都具有可用的多视图RGB-D输入,而不是仅仅在2D帧上操作,利用这些输入来构建用于3D实例分割的方法,可以有效地将这些多模态输入融合在一起。网络通过基于3D重建的姿势对齐,将2D图像与体积网格相关联,来利用高分辨率RGB输入。对于每个图像,首先通过一系列2D卷积为每个像素提取2D特征;然后,我们将得到的特征向量反投影到3D网格中的关联体素。2D和3D特征学习的这种组合比最先进的替代方案具有更高精度的对象检测和实例分割。根据在合成和真实公共基准测试中显示的结果,我们实现了对实际数据的mAP超过13的改进。

论文地址:https://arxiv.org/pdf/1812.07003.pdf
视频:https://www.youtube.com/watch?v=IH9rNLD1-JE
项目网址:http://graphics.stanford.edu/~adai/hou20193dsis.html
摘要:
本文提出了Scan2CAD1,这是一种新颖的数据驱动方法,它学习如何将形状数据库中的纯3D CAD模型与RGBD扫描的噪声和不完整几何形状对齐。对于室内场景的3D重建,我们的方法将一组CAD模型作为输入,并预测将每个模型与基础扫描几何对齐的9DoF姿势。为了解决这个问题,我们基于1506 ScanNet扫描创建了一个新的scanto-CAD对齐数据集,其中包含来自ShapeNet的14225个CAD模型与扫描中的对应对象之间的97607个带注释的关键点对。我们的方法在3D扫描中选择一组代表性关键点,寻找它们与CAD几何体的对应关系。为此,我们设计了一种新颖的3D CNN架构,以学习真实物体和合成物体之间的联合嵌入,从而预测对应的热度图。基于这些对应热度图,我们制定了变分能量最小化,使一组给定的CAD模型与重建的结果对齐。我们在新推出的Scan2CAD基准测试中评估了我们的方法,它比手工特征描述以及最先进的CNN方法都优秀21.39%。

论文地址: https://arxiv.org/pdf/1811.11187.pdf
视频: https://www.youtube.com/watch?v=PiHSYpgLTfA
项目网址: http://graphics.stanford.edu/~adai/avetisyan2019scan2cad.html
摘要:
本文提出了Scan2Mesh,这是一种新颖的数据驱动的生成方法,它将非结构化和可能不完整的范围扫描转换为结构化的3D网格表示。这项工作的主要贡献:构建了一种输入是3D对象的范围扫描,其输出是以输入扫描为条件的索引面集的生成神经网络架构。为了生成3D网格作为一组顶点和面部索引,生成模型建立在顶点,边和面的一系列代理损失之上。在每个阶段,我们通过卷积和图形神经网络架构的组合,实现预测的和真实数据点之间的一对一离散映射。这使我们的算法能够预测紧凑的网格表示,类似于使用3D建模软件通过艺术家手工创建的网格表示。因此,我们生成的网格结果可生成更灵敏,更清晰的网格,其结构与通过隐式函数生成的网格具有根本不同的结构,这是缩小与艺术家创建的CAD模型的差距的第一步。

论文地址: https://arxiv.org/pdf/1811.10464.pdf
项目网址: http://graphics.stanford.edu/~adai/dai2019scan2mesh.html
摘要:
我们从单个图像研究3D形状建模,并从三个方面做出贡献。首先,我们提出了Pix3D,这是一个大规模的基准,具有像素级2D-3D对齐的各种图像形状对。Pix3D在有关形状的任务中有广泛的应用,包括重建,检索,视点估计等。然而,建立如此大规模的数据集非常具有挑战性;现有数据集要么仅包含合成数据,要么缺少2D图像和3D形状之间的精确对齐,或者仅具有少量图像。其次,我们通过行为研究校准3D形状重建的评估标准,并使用它们客观和系统地对Pix3D上的切割重建算法进行基准测试。第三,我们设计了一种同时进行三维重建和姿态估计的新模型;我们的多任务学习方法在这两项任务中实现了最先进的性能。

论文地址: http://pix3d.csail.mit.edu/papers/pix3d_cvpr.pdf
Github地址: https://github.com/xingyuansun/pix3d
项目网址: http://pix3d.csail.mit.edu/
摘要:
我们提出了一种方法,用先前看到的物体模型填充未知环境,将其放置在欧几里得参考帧中,利用单目视频和惯性传感器进行因果和在线推断。我们实现的系统为场景中可见但未被识别为先前看到的对象的区域返回稀疏点云,否则返回详细对象模型及其在欧几里德帧中的姿势。该系统包括自下而上和自上而下的组件,由此训练用于检测的深度网络提供由非线性滤波器提供的对象假设的似然分数,其状态用作存储器。附加网络提供边缘的似然分数,这完善了检测网络对于微小形变的不变性能。我们在现有数据集上测试我们的算法,并且还引入VISMA数据集,其提供地面实况姿势,点云图和对象模型,以及带时间戳的惯性测量。
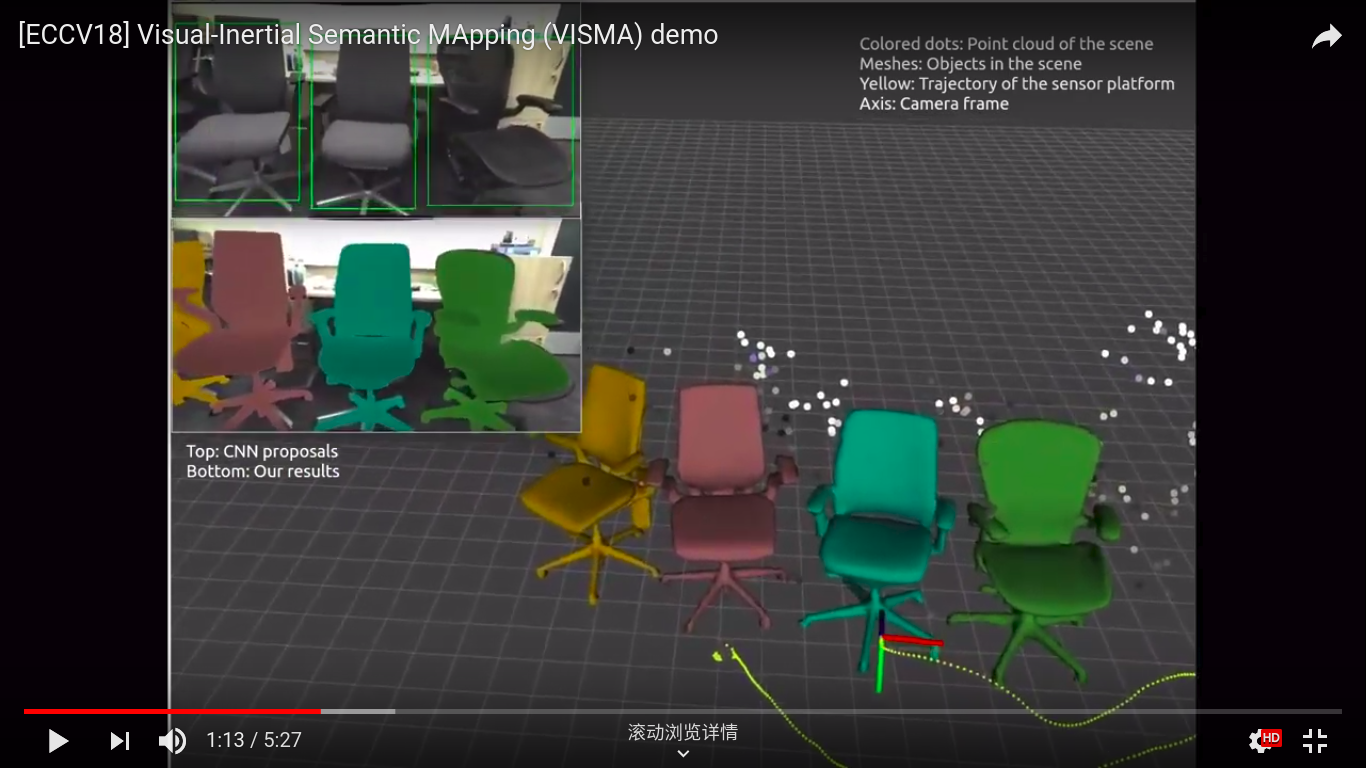
论文地址: https://arxiv.org/pdf/1806.08498.pdf
视频: https://www.youtube.com/watch?v=TZTriqQm6nU
数据: https://github.com/feixh/VISMA
摘要:
本文提出了一种基于过滤的语义映射方法,可以同时检测对象并定位它们的6DoF姿势。这种方法称为上下文时间映射(或CT-Map),我们将语义映射表示为对象类的信念,并在观察到的场景中构建。然后以条件随机场(CRF)的形式对语义映射问题的推断进行建模。CT-Map是一种CRF,它考虑两种形式的关系潜力来解释对象之间的上下文关系和对象姿势的时间一致性,以及观察的测量潜力。然后提出粒子滤波算法以在CT-Map模型中执行推断。我们使用配备RGB-D传感器的Michigan Progress Fetch机器人展示了CT-Map方法的有效性。我们的结果表明,基于粒子滤波的CT-Map推断相对于将观察视为场景的独立样本的基线方法提供了改进的物体检测和姿态估计。
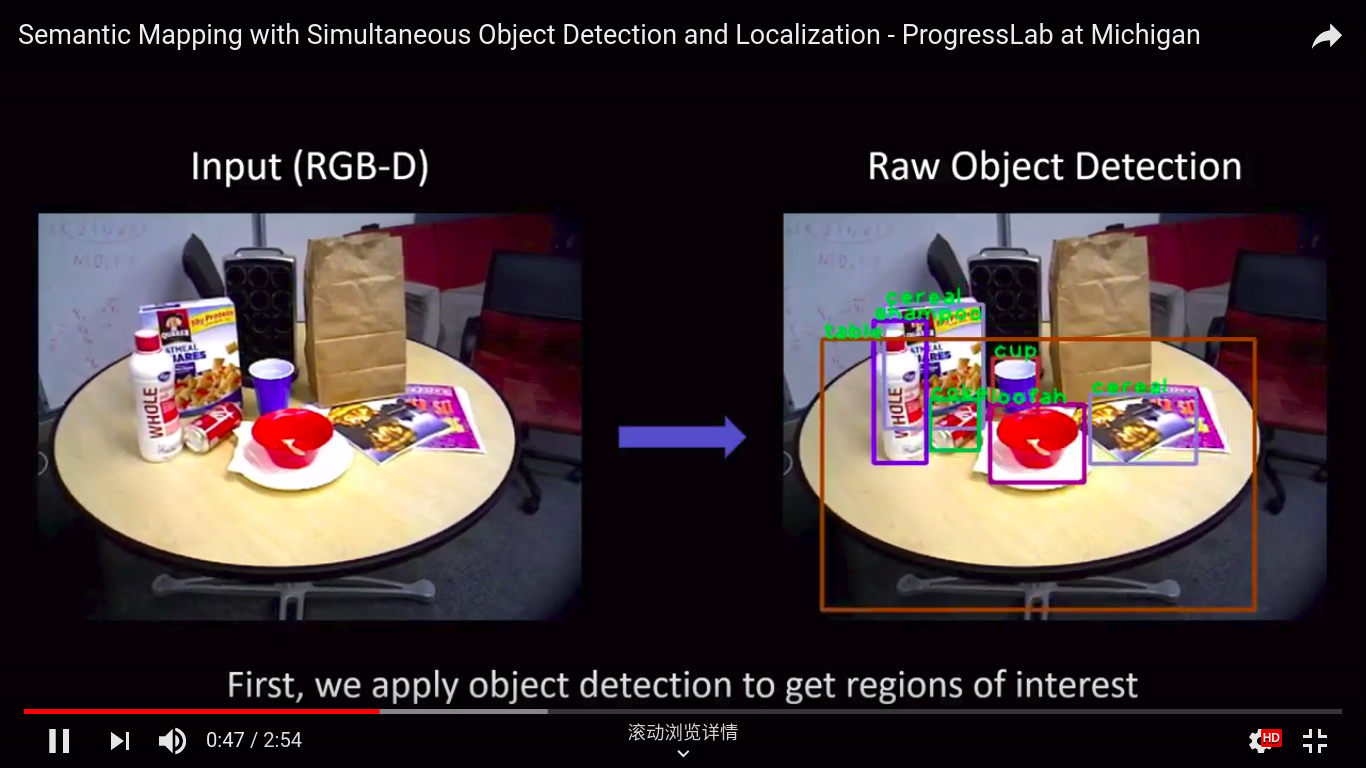
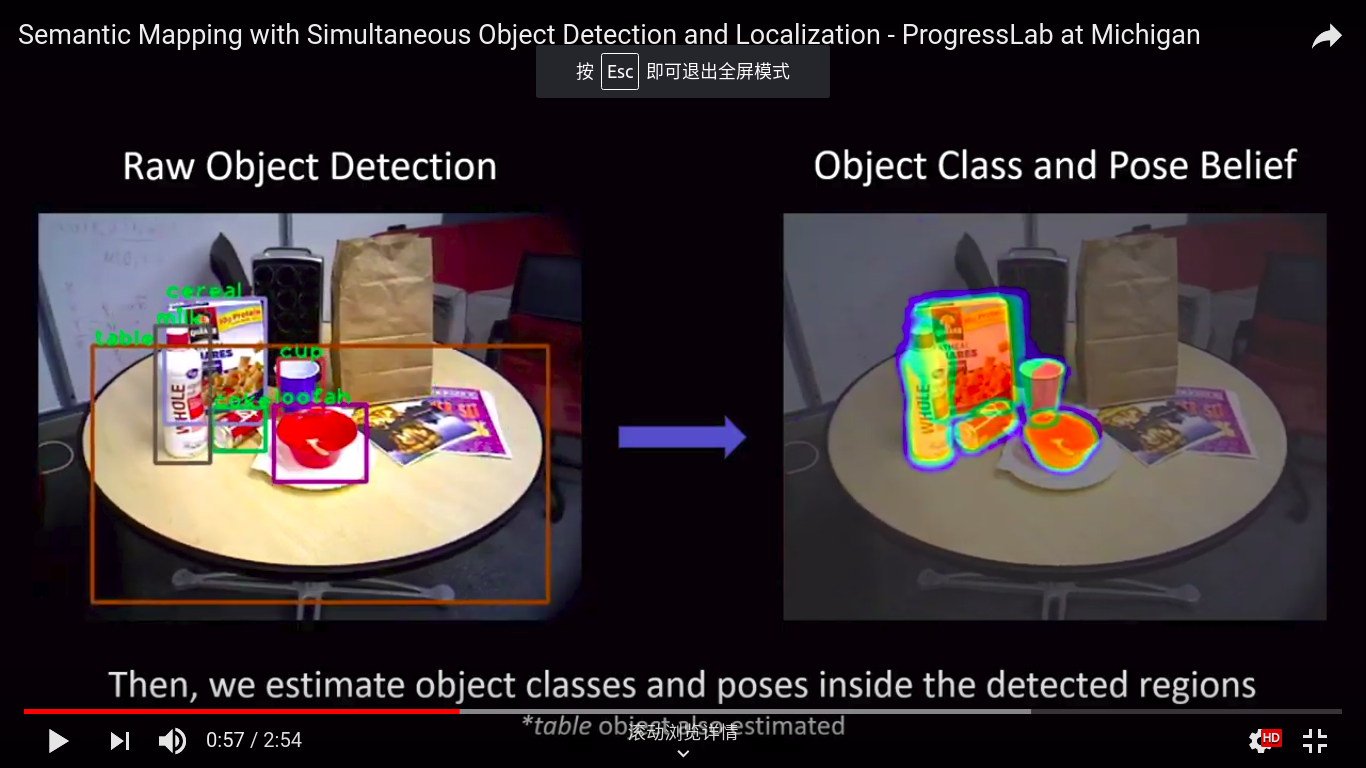
论文地址: https://arxiv.org/abs/1810.11525
视频: https://www.youtube.com/watch?v=W-6ViSlrrZg
摘要:
本文提出了3DMV,一种使用联合3D多视图预测网络在室内环境中进行RGB-D扫描的3D语义场景分割的新方法。与使用几何或RGB数据作为此任务的输入的现有方法相比,我们将这两种数据模态组合在一个联合的端到端网络架构中。我们首先从相关的RGB图像中提取特征图,而不是简单地将颜色数据投影到体积网格中并且仅以3D操作 - 这将导致细节不足。然后使用可反射的反投影层将这些特征映射到3D网络的体积特征网格中。由于我们的目标是可能有很多帧的3D扫描场景,我们使用多视图池化方法来处理不同数量的RGB输入视图。这种学习到的RGB和几何特征与我们的联合2D-3D架构相结合,可以获得比现有基线更好的结果。例如,与现有的体积架构相比,我们的结果在ScanNet 3D分割基准上的准确率从52.8%提升到75%.

论文地址: https://arxiv.org/pdf/1803.10409.pdf
代码: https://github.com/angeladai/3DMV
项目网址: http://graphics.stanford.edu/~adai/dai20183dmv.html
摘要:
本文提出了ScanComplete,这是一种新颖的数据驱动方法,将场景的不完整3D扫描作为输入,能够预测出完整的3D模型以及每个体素的语义标签。本文的主要贡献是:随着场景规模的扩大,使立方体的数据尺寸增大,因此能够处理具有不同空间范围的大型场景。我们设计了一个完全卷积生成的3D CNN模型,其卷积核对于整个场景尺寸是不变的。该模型可以在子场景上进行训练,但在测试时能够部署在任意大的场景中。另外,我们提出了一个粗略的推理策略,以产生高分辨率的输出,同时也利用了大的输入上下文尺寸。在一系列广泛的实验中,我们仔细评估了不同的模型设计选择,考虑了完成和语义推断的确定性和概率模型。我们的结果表明,我们不仅在处理环境的大小和处理效率方面优于其他方法,而且在完成质量和语义分割性能方面有显着的优势。

论文地址: https://arxiv.org/pdf/1712.10215.pdf
视频: https://www.youtube.com/watch?v=5s5s8iH0NF8
代码: https://github.com/angeladai/ScanComplete
项目网址: http://graphics.stanford.edu/~adai/dai2018scancomplete.html
摘要:
本文提出了3DLite,这是一种使用消费者的RGB-D传感器重建3D环境的新方法,它使我们朝着直接利用图像应用程序(如视频游戏、虚拟现实或AR)中捕获的3D内容迈出了一步。我们的方法不是重建真实世界的精确的一对一表示,而是计算出一个轻量、低多边形的扫描几何的几何抽象。我们认为,对于许多图形应用来说,获得高质量的表面纹理比获得高细节的几何图形更重要。为此,我们通过扭曲和缝合来自低质量RGB输入数据的图像片段来补偿运动模糊、自动曝光伪影和相机姿态中的微小错位,以实现高分辨率、锐利的表面纹理。除了观察到的场景区域外,我们外推场景几何体以及映射的表面纹理,以获得完整的环境3D模型。我们表明,场景几何图形的简单平面抽象非常适合此完成任务,使3DLite能够生成完整、轻量级且具有视觉吸引力的三维场景模型。我们认为,这些类似CAD的重建是在实际物体创建中利用RGB-D扫描的重要步骤。

论文地址:http://graphics.stanford.edu/~adai/papers/2017/3dlite/huang2017dlite.pdf
视频: https://www.youtube.com/watch?v=AzAb6O9OjYg
项目网址: http://graphics.stanford.edu/projects/3dlite/
摘要:
本文提出了一种数据驱动方法,通过体积深度神经网络和3D形状合成的组合来补全部分3D形状。从部分扫描的输入形状,我们的方法首先推断出分辨率低、但完整的输出。为此,我们提出了由3D卷积层组成的3D-Encoder-Predictor(3D-EPN)网络。训练网络以预测和填充丢失的数据,并对隐含的表面表示进行操作,该表示对已知和未知空间进行编码。这使我们能够以高精度预测未知区域的整体结构。然后,我们在测试时将这些中间结果与形状数据库中的3D几何形状相关联。在最后一遍中,我们提出了一种基于补丁的3D形状合成方法,该方法将来自这些检索到的形状的3D几何形状强加为粗略完成的网格上的约束。该合成过程使我们能够在遵循由3D-EPN获得的全局网格结构的同时,重建比例细节并生成高分辨率输出。虽然我们的3D-EPN优于最先进的补全方法,但主要贡献在于数据驱动的形状预测和分析3D形状合成的结合。在我们的结果中,我们展示了对新引入的真实和合成数据的形状补全基准的广泛评估。

论文地址: https://arxiv.org/pdf/1612.00101.pdf
项目网址: http://graphics.stanford.edu/projects/cnncomplete/
摘要:
从单个图像重建三维对象是一个具有高度不确定性的问题,需要对可能的三维形状有很强的先验知识。这为基于学习的方法带来了挑战,因为三维对象注释在真实图像中是稀缺的。以前的工作选择在具有地面实况三维信息的合成数据进行训练,但在实际数据测试时遭受域适应问题。
在这项工作中,我们提出了MarrNet,这是一种端到端的可训练模型,可以按顺序估算2.5D草图和3D物体形状。我们提出的方案分为两步,它有三个优点:首先,与完整的3D形状相比,2.5D草图更容易从2D图像中恢复;恢复2.5D草图的模型也更有可能从合成数据转移到实际数据。其次,对于2.5D草图的3D重建,系统可以纯粹从合成数据中学习。这是因为我们可以轻松渲染逼真的2.5D草图,而无需在真实图像中对物体的外观变化,包括光照,纹理等进行建模。这进一步缓解了域适应问题。第三,我们推导出从3D形状到2.5D草图的可微类投影函数;因此,框架可以在真实图像上进行端到端的训练,不需要人类注释。我们的模型在3D形状重建方面实现了最先进的性能。



论文地址: http://papers.nips.cc/paper/6657-marrnet-3d-shape-reconstruction-via-25d-sketches.pdf
Github地址: https://github.com/jiajunwu/marrnet
未完待续。。欢迎补充