Zhizheng Liu*, Francesco Milano*, Jonas Frey, Roland Siegwart, Hermann Blum, Cesar Cadena
Paper | Video | Project Page
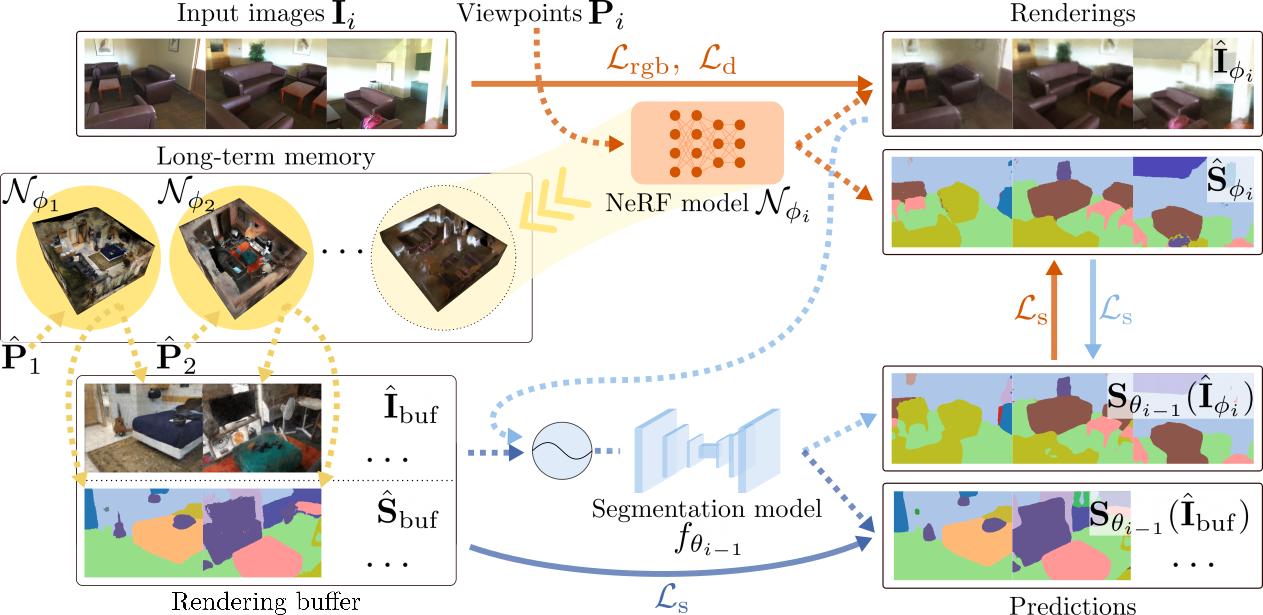
We present a framework to improve semantic scene understanding for agents that are deployed across a sequence of scenes. In particular, our method performs unsupervised continual semantic adaptation by jointly training a 2-D segmentation model and a Semantic-NeRF network.
- Our framework allows successfully adapting the 2-D segmentation model across multiple, previously unseen scenes and with no ground-truth supervision, reducing the domain gap in the new scenes and improving on the initial performance of the model.
- By rendering training and novel views, the pipeline can effectively mitigate forgetting and even gain additional knowledge about the previous scenes.
We recommend configuring your workspace with a conda environment. You can then install the project and its dependencies as follows. The instructions were tested on Ubuntu 20.04 and 22.04, with CUDA 11.3.
-
Clone this repo to a folder of your choice, which in the following we will refer to with the environmental variable
REPO_ROOT:export REPO_ROOT=<FOLDER_PATH_HERE> cd ${REPO_ROOT}; git clone git@github.com:ethz-asl/nr_semantic_segmentation.git
-
Create a conda environment and install PyTorch, tiny-cuda-nn and other dependencies:
conda create -n nr4seg python=3.8 conda activate nr4seg python -m pip install --upgrade pip # For CUDA 11.3. conda install pytorch==1.11.0 torchvision==0.12.0 torchaudio==0.11.0 cudatoolkit=11.3 -c pytorch # Install tiny-cuda-nn pip install git+https://github.com/NVlabs/tiny-cuda-nn/#subdirectory=bindings/torch pip install -r requirements.txt python setup.py develop
We use the ScanNet v2 [1] dataset for our experiments.
[1] Angela Dai, Angel X. Chang, Manolis Savva, Maciej Halber, Thomas Funkhouser, and Matthias Nießner, "ScanNet: Richly-annotated 3D Reconstructions of Indoor Scenes", in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pp. 2432-2443, 2017.
-
To get started, visit the official ScanNet dataset website to obtain the data downloading permission and script. We keep all the ScanNet data in the
${REPO_ROOT}/data/scannetfolder. You may use a symbolic link if necessary (e.g.,ln -s <YOUR_DOWNLOAD_FOLDER> ${REPO_ROOT}/data/scannet). -
As detailed in the paper, we use scenes
0000to0009to perform continual semantic adaptation, and a subset of data from the remaining scenes (0010to0706) to pre-train the segmentation network.-
The data from the pre-training scenes are conveniently provided already in the correct format by the ScanNet dataset, as a
scannet_frames_25k.zipfile. You can download this file using the official download script that you should have received after requesting access to the dataset, specifying the--preprocessed_framesflag. Once downloaded, the content of the file should be extracted to the subfolder${REPO_ROOT}/data/scannet/scannet_frames_25k. -
For the scenes used to perform continual semantic adaptation, the full data are required. To obtain them, run the official download script, specifying through the flag
--idthe scene to download (e.g.,--id scene0000_00to download scene0000) and including the--label_mapflag, to download also the label mapping filescannetv2-labels.combined.tsv(cf. here). The downloaded data should be stored in the subfolder${REPO_ROOT}/data/scannet/scans. Next, extract all the sensor data (depth images, color images, poses, intrinsics) using the SensReader tool provided by ScanNet, for each of the downloaded scenes from0000to0009. For instance, for scene0000, runpython2 reader.py --filename ${REPO_ROOT}/data/scannet/scans/scene0000_00/scene0000_00.sens --output_path ${REPO_ROOT}/data/scannet/scans/scene0000_00 --export_depth_images --export_color_images --export_poses --export_intrinsics
To obtain the raw labels (for evaluation purposes) for each of the continual adaptation scenes, also extract the content of the
sceneXXXX_XX_2d-label-filt.zipfile, so that a${REPO_ROOT}/data/scannet/scans/sceneXXXX_XX/label-filtfolder is created. -
Copy the
scannetv2-labels.combined.tsvfile to each scene folder under${REPO_ROOT}/data/scannet/scans, as well as to the subfolder${REPO_ROOT}/data/scannet/scannet_frames_25k. -
At the end of the process, the
${REPO_ROOT}/datafolder should contain at least the following data, structured as below:scannet scannet_frames_25k scene0010_00 color 000000.jpg ... XXXXXX.jpg label 000000.png ... XXXXXX.png ... ... scene0706_00 ... scannetv2-labels.combined.tsv scans scene0000_00 color 000000.jpg ... XXXXXX.jpg depth 000000.png ... XXXXXX.png label-filt 000000.png ... XXXXXX.png pose 000000.txt ... XXXXXX.txt intrinsics intriniscs_color.txt intrinsics_depth.txt scannetv2-labels.combined.tsv ... scene0009_00 ...You may define the data subfolders differently by adjusting the
scannetandscannet_frames_25kfields incfg/env/env.yml. You may also define several config files and set the configuration to use by specifying theENV_WORKSTATION_NAMEenvironmental variable before running the code (e.g.,export ENV_WORKSTATION_NAME="gpu_machine"to use the config incfg/env/gpu_machine.yml).
-
-
Copy the files
split.npzandsplit_cl.npzfrom the${REPO_ROOT}/cfg/dataset/scannet/folder to the${REPO_ROOT}/data/scannet/scannet_frames_25kfolder. These files contain the indices of the samples that define the train/validation splits used in pre-training and to form the replay buffer in continual adaptation, to ensure reproducibility.
After organizing the ScanNet files as detailed above, run the following script to pre-process the files:
bash run_scripts/preprocess_scannet.shAfter pre-processing, the folder structure for each sceneXXXX_XX from scene0000_00 to scene0009_00 should look as follows:
sceneXXXX_XX
color
000000.jpg
...
XXXXXX.jpg
color_scaled
000000.jpg
...
XXXXXX.jpg
depth
000000.png
...
XXXXXX.png
label_40
000000.png
...
XXXXXX.png
label_40_scaled
000000.png
...
XXXXXX.png
label-filt
000000.png
...
XXXXXX.png
pose
000000.txt
...
XXXXXX.txt
intrinsics
intriniscs_color.txt
intrinsics_depth.txt
scannetv2-labels.combined.tsv
transforms_test.json
transforms_test_scaled_semantics_40_raw.json
transforms_train.json
transforms_train_scaled_semantics_40_raw.jsonBy default, the data produced when running the code is stored in the ${REPO_ROOT}/experiments folder. You can modify this by changing the results field in cfg/env/env.yml.
To pre-train the DeepLabv3 segmentation network on scenes 0010 to 0706, run the following script:
bash run_scripts/pretrain.sh --exp cfg/exp/pretrain_scannet_25k_deeplabv3.ymlAlternatively, we provide a pre-trained DeepLabv3 checkpoint, which you may download to the ${REPO_ROOT}/ckpts folder.
This Section contains instruction on how to perform one-step adaptation experiments (cf. Sec. 4.4 in the main paper).
For fine-tuning, NeRF pseudo-labels should first be generated by running NeRF-only training:
bash run_scripts/one_step_nerf_only_train.shNext, run
bash run_scripts/one_step_finetune_train.shto fine-tune DeepLabv3 with the NeRF pseudo-labels. Please make sure the variable prev_exp_name defined in the fine-tuning script matches the variable name in the NeRF-only script.
To perform one-step joint training, run
bash run_scripts/one_step_joint_train.shTo perform multi-step adaptation experiments (cf. Sec. 4.5 in the main paper), run the following commands:
# Using training views for replay.
bash run_scripts/multi_step.sh --exp cfg/exp/multi_step/cl_base.yml
# Using novel views for "replay".
bash run_scripts/multi_step.sh --exp cfg/exp/multi_step/cl_base_novel_viewpoints.ymlBy default, we use WandB to log our experiments. You can initialize WandB logging by running
wandb init -e ${YOUR_WANDB_ENTITY}in the terminal. Alternatively, you can disable all logging by defining export WANDB_MODE=disabled before launching the experiments.
To obtain the variances of the results, we run the above experiments multiple times with different seeds by specifying --seed in the argument.
If you find our code or paper useful, please cite:
@inproceedings{Liu2023UnsupervisedContinualSemanticAdaptationNR,
author = {Liu, Zhizheng and Milano, Francesco and Frey, Jonas and Siegwart, Roland and Blum, Hermann and Cadena, Cesar},
title = {Unsupervised Continual Semantic Adaptation through Neural Rendering},
booktitle = {Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)},
year = {2023}
}Parts of the NeRF implementation are adapted from torch-ngp, Semantic-NeRF, and Instant-NGP.
Contact Zhizheng Liu and Francesco Milano for questions, comments, and reporting bugs.