This is the official code for the paper Benchmarking Multimodal Variational Autoencoders: CdSprites+ Dataset and Toolkit.
The purpose of this toolkit is to offer a systematic and unified way to train, evaluate and compare the state-of-the-art multimodal variational autoencoders. The toolkit can be used with arbitrary datasets and both uni/multimodal settings. By default, we provide implementations of the MVAE (paper), MMVAE (paper), MoPoE (paper) and DMVAE (paper) models, but anyone is free to contribute with their own implementation.
We also provide a custom synthetic bimodal dataset, called CdSprites+, designed specifically for comparison of the joint- and cross-generative capabilities of multimodal VAEs. You can read about the utilities of the dataset in the proposed paper (link will be added soon). This dataset extends the dSprites dataset with natural language captions and additional features and offers 5 levels of difficulty (based on the number of attributes) to find the minimal functioning scenario for each model. Moreover, its rigid structure enables automatic qualitative evaluation of the generated samples. For more info, see below.
Code Documentation & Tutorials
Supplementary Material (Additional Paper Results)
| 🎯 To elevate the general discussion on the development and evaluation of multimodal VAEs, we have now added the Discussions section |
|---|
- Preliminaries
- CdSprites+ dataset
- Setup & Training
- Evaluation
- CdSprites+ leaderboard
- Training on other datasets
- Add own model
- Ethical Guidelines
- License & Acknowledgement
- Contact
This code was tested with:
- Python version 3.8.13
- PyTorch version 1.12.1
- CUDA version 10.2 and 11.6
We recommend to install the conda enviroment as follows:
conda install mamba -n base -c conda-forge
mamba env create -f environment.yml
conda activate multivae
Please note that the framework depends on the Pytorch Lightning framework which manages the model training and evaluation.
We provide a bimodal image-text dataset CdSprites+ (Geometric shapes Bimodal Dataset) for systematic multimodal VAE comparison. There are 5 difficulty levels based on the number of featured attributes (shape, size, color, position and background color). You can either generate the dataset on your own, or download a ready-to-go version.
You can download any of the following difficulty levels: Level 1, Level 2, Level 3, Level 4, Level 5.
The dataset should be placed in the ./data/CdSpritesplus directory. For downloading, unzipping and moving the chosen dataset, run:
cd ~/multimodal-vae-comparison/multimodal_compare
wget https://data.ciirc.cvut.cz/public/groups/incognite/CdSprites/level2.zip # replace level2 with any of the 1-5 levels
unzip level2.zip -d ./data/CdSpritesplus
You can also generate the dataset on your own. To generate all levels at once, run:
cd ~/multimodal-vae-comparison/multimodal_compare/data_proc
python ./cdSprites.py
Alternatively, to generate only one level:
cd ~/multimodal-vae-comparison/multimodal_compare/data_proc
python ./cdSprites.py --level 4
The code will create the ./CdSpritesplus folder in the ./data directory. The folder includes subfolders with different levels (or the one level that you have chosen). Each level contains images sorted in directories according to their captions. There is also the traindata.h5 file containing the whole dataset - you can then use this file in the config.
We show an example training config in ./multimodal_compare/configs/config1.yml. You can run the training as follows (assuming you downloaded or generated the dataset level 2 above):
cd ~/multimodal-vae-comparison/multimodal_compare
python main.py --cfg configs/config1.yml
The config contains general arguments and modality-specific arguments (denoted as "modality_n"). In general, you can set up a training for 1-N modalities by defining the required subsections for each of them. The paths to all modalities are expected to have the data ordered so that they are semantically matching (e.g. the first image and the first text sample belong together).
The usage and possible options for all the config arguments are below:

We provide an automated way to perform a hyperparameter grid search for your models. First, set up the default config (e.g. config1.yml in ./configs) that should be adjusted in the selected parameters. Then generate the full variability within the chosen parameters as follows:
cd ~/multimodal-vae-comparison/multimodal_compare
python data_proc/generate_configs.py --path ./configs/my_experiment --cfg ./configs/config1.yml --n-latents 24 32 64 --mixing moe poe --seed 1 2 3
The script will make 36 configs (4 models x 3 seeds x 3 latent dimensionalities) within the chosen directory. To see the full spectrum of parameters that can be adjusted, run:
python data_proc/generate_configs.py -h
To automatically run the whole set of experiments located in one folder, launch:
./iterate_configs.sh "./configs/my_experiment/"
We provide sets of configs for the experiments reported in the paper. These are located in ./configs/reproduce_paper/. You can run any subset of these using the same bash script. E.g., to reproduce all reported experiments, run:
./iterate_configs.sh "./configs/reproduce_paper/"
(This is 60 experiments, each run trains the model 5x with 5 different seeds.)
Or, to reproduce for example only the experiments for the MMVAE model, run:
./iterate_configs.sh "./configs/reproduce_paper/mmvae"
(This is 15 experiments, each run trains the model 5x with 5 different seeds.)
For improving the training speed, you can also use Mixed Precision Training. PyTorch Lightning supports the following values: 64, 32, 16, bf16. The default precision is 32, but you can change the parameter with the '--precision' or '-p' argument:
cd ~/multimodal-vae-comparison/multimodal_compare
python main.py --cfg configs/config1.yml --precision bf16
You can read more about this configuration in the PyTorch Lightning documentation
After training, you will find various visualizations of the training progress in the ./visuals folder of your experiment. Furthermore, to calculate the joint- and cross-generation accuracy, you can run:
cd ~/multimodal-vae-comparison/multimodal_compare
python eval/eval_cdsprites.py --model model_dir_name --level 2 # specify the level on which the model was trained
The trained model is expected to be placed in the results folder. The script will print the statistics in the terminal and also save them in the model folder as cdsprites_stats.txt
Here we show a leaderboard of the state-of-the-art models evaluated on our CdSprites+ benchmark dataset. The experiments can be reproduced by running the configs specified in the Config column (those are linked to a corresponding subfoder in ./configs/reproduce_paper which contains the 5 seeds). For example, to reproduce the leaderboard results for CdSprites+ Level 1 and the MVAE model, run:
cd ~/multimodal-vae-comparison/multimodal_compare
./iterate_configs.sh "./configs/reproduce_paper/mvae/level1"
All experiments will be run with 5 seeds, the results here are reported as a mean over those seeds. Here is a legend for the leaderboard tables:
- Pos. - position of the model in the leaderboard
- Model - refers to the multimodal VAE model shortcut (e.g. MMVAE, MVAE).
- Obj. - objective function used for training (ELBO, IWAE, DREG)
- Accuracy (Text→Image) - provided only text on the input, we report accuracy of the reconstructed images.
We show two numbers:
- Strict - percentage of completely correct samples (out of 500 test samples)
- Feats - ratio of correct features per sample, i.e., 1.2 (0.1)/3 for Level 3 means that on average 1.2 +/- 0.1 features out of 3 are recognized correctly for each sample (for Level 1 same as Strict)
- Accuracy (Image→Text) - provided only images on the input, we report accuracy of the reconstructed text.
We show three numbers:
- Strict - percentage of completely correct samples (out of 250 test samples)
- Feats - ratio of correct words per sample (for Level 1 same as Strict)
- Letters - mean percentage of correct letters per sample
- Accuracy Joint - we sample N x 20 (N is the Latent Dim) random vectors from the latent space and reconstruct both text and image. We report two numbers:
- Strict - percentage of completely correct and matching samples (out of 500 test samples)
- Feats - ratio of correct features (matching for image and text) per sample (for Level 1 same as Strict)
- Weights - download the pretrained weights
- Config - config to reproduce the results
Please note that we are currently preparing weights compatible with the newly-added Pytorch Lightning framework. For evaluating the models using the weights provided below, please checkout the following revision: abd4071da1c034b6496f98e2ff379a92f0b92cde
In brackets we show standard deviations over the 5 seeds.
| Pos. | Model | Obj. | Accuracy (Txt→Img) [%] | Accuracy (Img→Txt) [%] | Joint Accuracy [%] | Weights | Config | ||||
| Strict | Feats | Strict | Feats | Letters | Strict | Feats | |||||
| 1. | MMVAE | ELBO | 47(14) | N/A | 64 (3) | N/A | 88 (2) | 17 (10) | N/A | Link | Link |
| 2. | MVAE | ELBO | 52 (3) | N/A | 63 (8) | N/A | 86 (2) | 5 (9) | N/A | Link | Link |
| 3. | MoPoE | ELBO | 33 (3) | N/A | 10 (17) | N/A | 26 (7) | 16 (27) | N/A | Link | Link |
| 4. | DMVAE | ELBO | 33 (4) | N/A | 4 (5) | N/A | 25 (2) | 4 (6) | N/A | Link | Link |
| Pos. | Model | Obj. | Accuracy (Txt→Img) [%] | Accuracy (Img→Txt) [%] | Joint Accuracy [%] | Weights | Config | ||||
| Strict | Feats | Strict | Feats | Letters | Strict | Feats | |||||
| 1. | MVAE | ELBO | 16 (1) | 0.8 (0.0)/2 | 55 (27) | 1.5 (0.3)/2 | 91 (6) | 1 (1) | 0.3 (0.3)/2 | Link | Link |
| 2. | MMVAE | ELBO | 18 (4) | 0.8 (0.1)/2 | 41 (20) | 1.4 (0.2)/2 | 85 (4) | 3 (3) | 0.6 (0.1)/2 | Link | Link |
| 3. | MoPoE | ELBO | 10 (3) | 0.8 (0.0)/2 | 8 (7) | 0.7 (0.1)/2 | 40 (4) | 1 (1) | 0.2 (0.1)/2 | Link | Link |
| 4. | DMVAE | ELBO | 15 (2) | 0.8 (0.0)/2 | 4 (1) | 0.4 (0.0)/2 | 30 (2) | 0 (0) | 0.2 (0.1)/2 | Link | Link |
| Pos. | Model | Obj. | Accuracy (Txt→Img) [%] | Accuracy (Img→Txt) [%] | Joint Accuracy [%] | Weights | Config | ||||
| Strict | Feats | Strict | Feats | Letters | Strict | Feats | |||||
| 1. | MVAE | ELBO | 8 (2) | 1.3 (0.0)/3 | 59 (4) | 2.5 (0.3)/3 | 93 (1) | 0 (0) | 0.5 (0.1)/3 | Link | Link |
| 2. | MMVAE | ELBO | 6 (2) | 1.2 (0.2)/3 | 2 (3) | 0.6 (0.2)/3 | 31 (5) | 0 (0) | 0.4 (0.1)/3 | Link | Link |
| 3. | MoPoE | ELBO | 7 (4) | 1.3 (0.1)/3 | 0 (0) | 0.7 (0.1)/3 | 32 (0) | 0 (0) | 1.1 (0.1)/3 | Link | Link |
| 4. | DMVAE | ELBO | 4 (0) | 1.4 (0.0)/3 | 0 (0) | 0.4 (0.1)/3 | 22 (2) | 1 (1) | 0.5 (0.1)/3 | Link | Link |
| Pos. | Model | Obj. | Accuracy (Txt→Img) [%] | Accuracy (Img→Txt) [%] | Joint Accuracy [%] | Weights | Config | ||||
| Strict | Feats | Strict | Feats | Letters | Strict | Feats | |||||
| 1. | MVAE | ELBO | 0 (0) | 1.8 (0.0)/4 | 0 (0) | 0.6 (0.0)/4 | 28 (3) | 0 (0) | 0.6 (0.0)/4 | Link | Link |
| 2. | MMVAE | ELBO | 3 (3) | 1.7 (0.4)/4 | 1 (2) | 0.7 (0.4)/4 | 27 (9) | 0 (0) | 0.5 (0.2)/4 | Link | Link |
| 3. | MoPoE | ELBO | 2 (1) | 1.4 (0.0)/4 | 0 (0) | 0.7 (0.1)/4 | 21 (3) | 0 (0) | 0.1 (0.2)/4 | Link | Link |
| 4. | DMVAE | ELBO | 1 (1) | 1.4 (0.0)/4 | 0 (0) | 0.5 (0.1)/4 | 18 (1) | 0 (0) | 0.5 (0.1)/4 | Link | Link |
| Pos. | Model | Obj. | Accuracy (Txt→Img) [%] | Accuracy (Img→Txt) [%] | Joint Accuracy [%] | Weights | Config | ||||
| Strict | Feats | Strict | Feats | Letters | Strict | Feats | |||||
| 1. | MVAE | ELBO | 0 (0) | 1.8 (0.0)/5 | 0 (0) | 0.6 (0.0)/5 | 27 (1) | 0 (0) | 0.2 (0.2)/5 | Link | Link |
| 2. | MMVAE | ELBO | 0 (0) | 1.8 (0.0)/5 | 0 (0) | 0.1 (0.1)/5 | 13 (2) | 0 (0) | 0.4 (0.1)/5 | Link | Link |
| 3. | MoPoE | ELBO | 0 (0) | 1.8 (0.0)/5 | 0 (0) | 0.7 (0.0)/5 | 17 (1) | 0 (0) | 1.0 (0.0)/5 | Link | Link |
| 4. | DMVAE | ELBO | 0 (0) | 1.8 (0.0)/5 | 0 (0) | 0.6 (0.1)/5 | 18 (2) | 0 (0) | 0.7 (0.1)/5 | Link | Link |
Please feel free to propose your own model and training config so that we can add the results in these tables.
By default, we also support training on VHN (or MNIST/SVHN only), Caltech-UCSD Birds 200 (CUB) dataset as used in the MMVAE paper, Sprites (as in this repository), CelebA, FashionMNIST and PolyMNIST. We provide the default training configs which you can adjust according to your needs (e.g. change the model, loss objective etc.).
We use the inbuilt torchvision.datasets function to download and process the dataset. Resampling of the data should happen automatically based on indices that will be downloaded within the script. You can thus run:
cd ~/multimodal-vae-comparison/multimodal_compare
mkdir ./data/mnist_svhn
python main.py --cfg configs/config_mnistsvhn.yml
We provide our preprocessed and cleaned version of the dataset (106 MB in total). To download and train, run:
cd ~/multimodal-vae-comparison/multimodal_compare
wget https://data.ciirc.cvut.cz/public/groups/incognite/CdSprites/cub.zip # download CUB dataset
unzip cub.zip -d ./data/
python main.py --cfg configs/config_cub.yml
You can download the sorted version (4.6 GB) with 3 modalities (image sequences, actions and attributes) and train:
cd ~/multimodal-vae-comparison/multimodal_compare
wget https://data.ciirc.cvut.cz/public/groups/incognite/CdSprites/sprites.zip # download Sprites dataset
unzip sprites.zip -d ./data/
python main.py --cfg configs/config_sprites.yml
cd ~/multimodal-vae-comparison/multimodal_compare
wget https://data.ciirc.cvut.cz/public/groups/incognite/CdSprites/celeba.zip # download CelebA dataset
unzip celeba.zip -d ./data/
python main.py --cfg configs/config_celeba.yml
For FashionMNIST, we use the torchvision.datasets class to handle the download automatically, you thus do not need to download anything. You can train directly by running:
cd ~/multimodal-vae-comparison/multimodal_compare
python main.py --cfg configs/config_fashionmnist.yml
cd ~/multimodal-vae-comparison/multimodal_compare
wget https://zenodo.org/record/4899160/files/PolyMNIST.zip?download=1 # download PolyMNIST dataset
unzip PolyMNIST.zip?download=1 -d ./data/
python main.py --cfg configs/config_polymnist.yml
How to train on your own dataset
The toolkit is designed so that it enables easy extension for new models, objectives, datasets or encoder/decoder networks.
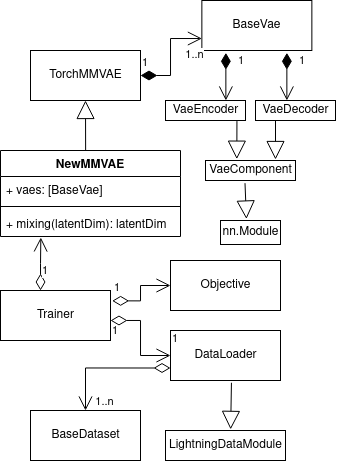
Here you can see the UML diagram of the framework. The toolkit uses the Pytorch Lightning framework which enables automatic separation of the data, models and the training process. A new model (see NewMMVAE in the diagram) can be added as a new class derived from TorchMMVAE. The model constructor will automatically create a BaseVAE class instance for each modality defined in the config - these BaseVAE classes will handle the modality-dependent operations such as encoding and decoding the data, sampling etc. The NewMMVAE class thus only requires the mixing method which defines how the individual posteriors should be mixed, although it is as well possible to change the whole forward pass if needed.
Step-by-step tutorial on how to add a new model
New encoder and decoder networks can be added in the corresponding scripts (encoders.py, decoders.py). For choosing these networks in the config, use only the part of the class name following after the underscore (e.g. CNN for the class Enc_CNN).
We provide a set of unit tests to check whether any newly-added implementations disrupt any of the existing functions. To run the unit test proceed as follows:
cd ~/multimodal-vae-comparison/
py.test .
The users of our toolkit and dataset are responsible for using the code and data in alignment with our ethical guidelines. These rules may be updated from time to time and are provided below.
- Clearly describe your experimental setup and model configurations, to ensure reproducibility, and share code and resources related to your experiments for others to verify and reproduce your results.
- Present your results, findings, and comparisons accurately and honestly, without manipulation or exaggeration.
- Avoid usage of the toolkit that would allow the malicious misuse of the generated content (such as manipulating real-world photographs, producing spam etc.)
- If you're working with sensitive or personal data, respect privacy and security guidelines. Obtain necessary permissions and anonymize data when required. Be cautious when using data that might reinforce biases or harm vulnerable groups.
- Ensure that you have the necessary permissions and licenses to use any code, datasets, or resources that you incorporate incorporated into your project.
- Properly attribute the toolkit and its components when you use them in your work.
This code is published under the CC BY-NC-SA 4.0 license.
If you use our toolkit or dataset in your work, please, give us an attribution using the following citation:
@misc{sejnova2023benchmarking,
title={Benchmarking Multimodal Variational Autoencoders: CdSprites+ Dataset and Toolkit},
author={Gabriela Sejnova and Michal Vavrecka and Karla Stepanova},
year={2023},
eprint={2209.03048},
archivePrefix={arXiv},
primaryClass={cs.LG}
}
The toolkit features models and functions from the official implementations of MVAE (paper), MMVAE (paper), MoPoE (paper) and DMVAE (paper),
For any additional questions, feel free to email sejnogab@fel.cvut.cz