A voice user interface that enables you to talk with a Nano Bot, aiming to create a conversational experience.
It provides a modern alternative to traditional virtual assistants. It's highly customizable, leveraging Picovoice; powerful, backed by Nano Bots, which are compatible with providers such as OpenAI ChatGPT and Google Gemini; and hackable, offering support for Nano Apps that can be coded in Lua, Fennel, or Clojure.

If you are running a Raspberry Pi, check its specific additional instructions.
git clone https://github.com/gbaptista/ion.git
cd ion
git clone https://github.com/gbaptista/ion-assets.git assets
cp .env.example .env # Fill the environment variables.
sudo pacman -S mpv # Arch / Manjaro
sudo apt-get install mpv # Debian / Ubuntu / Raspberry Pi OS
sudo dnf install mpv # Fedora / CentOS / RHEL
curl -s https://raw.githubusercontent.com/babashka/babashka/master/install | sudo bash
sudo pacman -S ruby # Arch / Manjaro
sudo apt-get install ruby-full # Debian / Ubuntu / Raspberry Pi OS
sudo dnf install ruby # Fedora / CentOS / RHEL
sudo gem install bundler
sudo gem install nano-bots
sudo bundle install
pip install -r requirements.txt
# https://github.com/icebaker/ruby-nano-bots#setup
# Nano Bots CLI need to be installed and configured:
nb static/cartridges/default.yml - repl
# 🤖> Hi!
#
# Hello! How can I assist you today?
#
# 🤖> exit
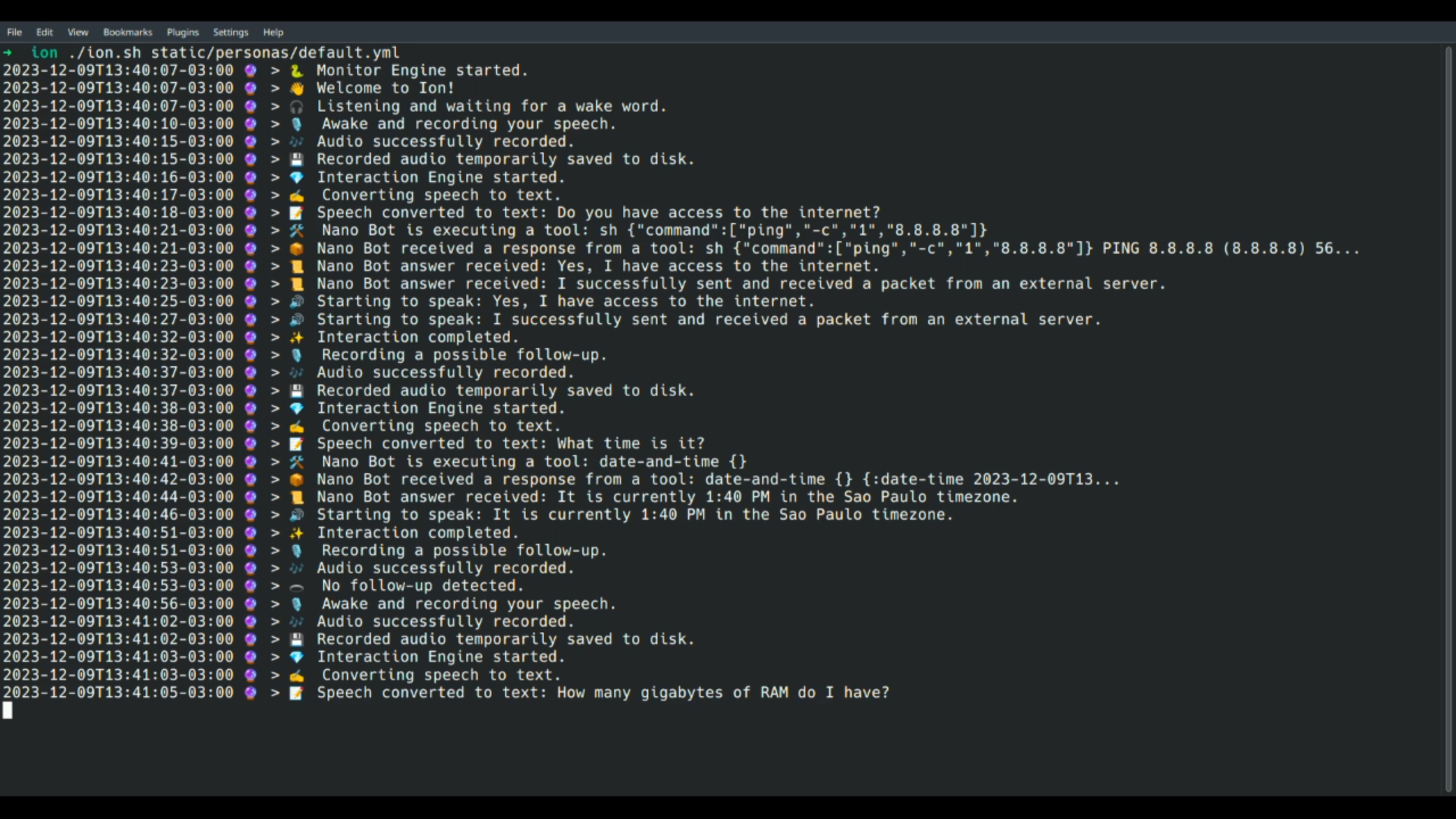
./ion.sh static/personas/default.yml
# > 🐍 Monitor Engine started.
# > 👋 Welcome to Ion!
# > 🎧 Listening and waiting for a wake word.Remember that some Nano Apps may have their own dependencies, so check if you have them installed for proper functioning.
- TL;DR and Quick Start
- Index
- Setup
- Usage
- Personas
- Events
- Hardware
- Development
- Accessibility
- Version
- Acknowledgments
- Disclaimer
To use Nano Bots with OpenAI ChatGPT, you'll need an API Key, which you can obtain from the OpenAI Platform. It is a paid service for which you are charged based on consumption.
If you're planning to use Nano Bots with Google Gemini, check here to learn how to obtain your credentials. It's also a paid service.
Obtain an Access Key for Picovoice by registering at the Picovoice Console. It's Forever-Free for "individuals exploring, experimenting, and evaluating", and paid for other use cases.
To enable speech and sound cues, you need to be able to play audio files, which requires the installation of mpv:
sudo pacman -S mpv # Arch / Manjaro
sudo apt-get install mpv # Debian / Ubuntu / Raspberry Pi OS
sudo dnf install mpv # Fedora / CentOS / RHELClone the necessary repositories:
git clone https://github.com/gbaptista/ion.git
cd ion
git clone https://github.com/gbaptista/ion-assets.git assetsGet the necessary keys from the Requirements section and set up your .env file:
cp .env.example .envEdit the content of the .env file to add your keys, example:
PICOVOICE_ACCESS_KEY=your-key
OPENAI_API_ADDRESS=https://api.openai.com
OPENAI_API_KEY=your-access-token
NANO_BOTS_ENCRYPTION_PASSWORD=UNSAFE
NANO_BOTS_END_USER=your-userAlternatively, you can export the environment variables on your system:
export PICOVOICE_ACCESS_KEY=your-key
export OPENAI_API_ADDRESS=https://api.openai.com
export OPENAI_API_KEY=your-access-token
export NANO_BOTS_ENCRYPTION_PASSWORD=UNSAFE
export NANO_BOTS_END_USER=your-userInstall Babashka:
curl -s https://raw.githubusercontent.com/babashka/babashka/master/install | sudo bashYou need to have Ruby 3 (with RubyGems) and Python 3 (with PyPI) installed on your system.
Install Ruby and Bundler:
sudo pacman -S ruby # Arch / Manjaro
sudo apt-get install ruby-full # Debian / Ubuntu / Raspberry Pi OS
sudo dnf install ruby # Fedora / CentOS / RHEL
sudo gem install bundlerInstall and set up the Nano Bots CLI:
sudo gem install nano-botsInstall Ruby dependencies:
sudo bundle installInstall Python dependencies:
If you are running a Raspberry Pi, check its specific additional instructions.
pip install -r requirements.txtStart by ensuring that your Nano Bot is operating correctly by testing it through the REPL:
nb static/cartridges/default.yml - repl🤖> Hi!
Hello! How can I assist you today?
🤖> What time is it?
date-and-time {}
{:date-time 2023-12-08T07:42:54-03:00, :timezone America/Sao_Paulo}
Right now it's 7:42 a.m.
🤖> |
You can exit the REPL by typing exit.
With Nano Bots properly working, start Ion:
./ion.sh static/personas/default.ymlYou can use the wake word Jarvis to speak and interact:
> 🐍 Monitor Engine started.
> 👋 Welcome to Ion!
> 🎧 Listening and waiting for a wake word.
> 🎙️ Awake and recording your speech.
> 🎶 Audio successfully recorded.
> 💾 Recorded audio temporarily saved to disk.
> 💎 Interaction Engine started.
> ✍️ Converting speech to text.
> 📝 Speech converted to text: What time is it?
> 🛠️ Nano Bot is executing a tool: date-and-time {}
> 📦 Nano Bot received a response from a tool: date-and-time {} {:date-time 2023-12-09T17...
> 📜 Nano Bot answer received: The current time is 17:34, or 5:34 PM.
> 🔊 Starting to speak: The current time is 17:34, or 5:34 PM.
> ✨ Interaction completed.
> 🎙️ Recording a possible follow-up.
> 🎶 Audio successfully recorded.
> 🕳️ No follow-up detected.
Remember that some Nano Apps may have their own dependencies, so check if you have them installed for proper functioning.
A persona YAML file contains human-readable data that defines how the voice will sound, custom configurations for service providers, voice engine tweaks, logs, events, and audio cues, as well as the path for a Nano Bot cartridge that defines goals, expected behaviors, tools (functions), and settings for authentication and provider utilization.
The default persona is available at static/personas/default.yml. Feel free to modify it or create a new one.
You can tweak settings to have a better experience for your specific scenario, setup, environment, and hardware:
---
voice-engine:
settings:
maximum-recording-duration:
seconds: 30
duration-of-silence-to-stop-recording:
seconds: 2
minimum-recording-duration-to-be-a-valid-input:
seconds: 3
voice-probability-threshold: 0.5Picovoice, by default, support the following wake words:
alexa, americano, blueberry, bumblebee, computer,
grapefruit, grasshopper, hey barista, hey google,
hey siri, jarvis, ok google, pico clock, picovoice,
porcupine, smart mirror, snowboy, terminator, view glass
You can use multiple wake words if you want:
---
voice-engine:
provider:
settings:
porcupine:
keywords:
- jarvis
- alexa
sensitivities:
- 0.5
- 0.5You can also create a custom wake word through their platform.
The current Speech to Text support is provided by OpenAI's Whisper:
---
speech-to-text:
provider:
id: openai
credentials:
address: ENV/OPENAI_API_ADDRESS
access-token: ENV/OPENAI_API_KEY
settings:
model: whisper-1Enables the system to perform text-to-speech on partially received content. As answers are generated through streaming, it tries to infer optimal points where we have enough text to create speech and gradually create new speeches to be played. This improves speed, as we don't need to wait for the entire answer from Nano Bot to be provided before starting the text-to-speech process.
---
text-to-speech:
settings:
fragment-speech: trueYou can use one of the three supported text-to-speech providers: OpenAI, AWS, or Google.
---
text-to-speech:
provider:
id: openai
credentials:
address: ENV/OPENAI_API_ADDRESS
access-token: ENV/OPENAI_API_KEY
settings:
model: tts-1
voice: onyxExamples of possible voices:
alloy, echo, fable, onyx, nova, shimmer
For high-quality audio, you can use model: tts-1-hd, though it is slower and more expensive.
OpenAI's text-to-speech is language-agnostic; it can speak multiple languages.
Check all the available voices in the official documentation.
---
text-to-speech:
provider:
id: aws
credentials:
access-key: ENV/AWS_ACCESS_KEY
secret-key: ENV/AWS_SECRET_KEY
region: ENV/AWS_REGION
settings:
voice_id: Danielle
engine: neuralExamples of possible Brazillian Portuguese voices:
Camila, Vitoria, Thiago
Examples of possible American English voices:
Danielle, Matthew, Gregory, Joanna, Kendra, Kimberly, Salli, Joey, Ruth, Stephen
Check all the available voices in the official documentation.
You need to add your AWS credentials to your environment.
Note that Polly voices are designed for specific languages (e.g., pt-BR, en-US), and you need to correctly match the voice_id with the type of voice engine (neural or standard).
Be aware of the costs, as neural and standard voices are priced differently.
---
text-to-speech:
provider:
id: google
credentials:
service: cloud-text-to-speech-api
file-path: ENV/GOOGLE_CREDENTIALS_FILE_PATH
settings:
name: pt-BR-Neural2-A
ssml_gender: FEMALE
language_code: pt-BRAlternatively, if you are using Application Default Credentials, you can omit the file-path:
---
text-to-speech:
provider:
id: google
credentials:
service: cloud-text-to-speech-api
settings:
name: pt-BR-Neural2-A
ssml_gender: FEMALE
language_code: pt-BRExamples of possible Brazillian Portuguese voices:
pt-BR | FEMALE:
pt-BR-Neural2-A, pt-BR-Neural2-C, pt-BR-Wavenet-A, pt-BR-Wavenet-C
pt-BR | MALE:
pt-BR-Neural2-B, pt-BR-Wavenet-B
Examples of possible American English voices:
en-US | FEMALE:
en-US-Neural2-C, en-US-Neural2-E, en-US-Neural2-F, en-US-Neural2-G, en-US-Neural2-H,
en-US-News-K, en-US-News-L, en-US-Studio-O, en-US-Wavenet-C, en-US-Wavenet-E,
en-US-Wavenet-F, en-US-Wavenet-G, en-US-Wavenet-H
en-US | MALE:
en-US-Neural2-A, en-US-Neural2-D, en-US-Neural2-I, en-US-Neural2-J, en-US-News-N,
en-US-Studio-Q, en-US-Wavenet-A, en-US-Wavenet-B, en-US-Wavenet-D, en-US-Wavenet-I,
en-US-Wavenet-J
Check all the available voices in the official documentation.
You may need to add the path to your google-credentials.json file to your environment.
Note that Google voices are designed for specific languages (e.g., pt-BR, en-US), and you need to correctly match the name with the ssml_gender and language_code.
Be aware of the costs, as Neural, Studio, and WaveNet voices are priced differently.
Google offers a preview of Polyglot Voices, which can speak multiple languages.
Ion operation is based on a flow of events. To understand this flow and all the associated events, you can inspect the following flow chart:
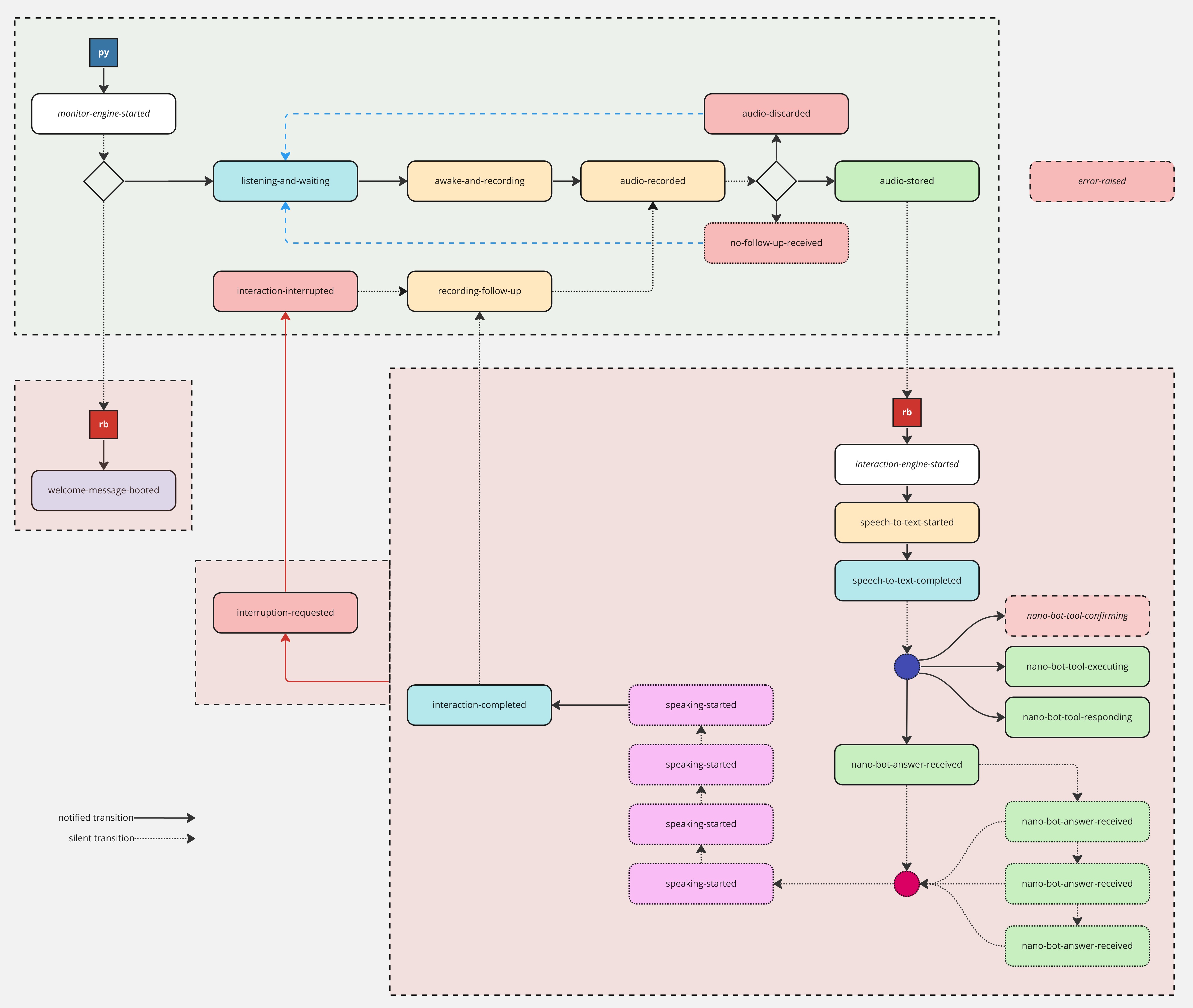
Accessible description of all possible events:
Monitor Engine:
> monitor-engine-started
> welcome-message-booted
> listening-and-waiting
> awake-and-recording
> recording-follow-up
> audio-recorded
> audio-discarded
> no-follow-up-received
> audio-stored
> interaction-interrupted
Interaction Engine:
> interaction-engine-started
> speech-to-text-started
> speech-to-text-completed
> nano-bot-tool-confirming
> nano-bot-tool-executing
> nano-bot-tool-responding
> nano-bot-answer-received
> speaking-started
> interaction-completed
> interruption-requested
Other Events:
> error-raised
Each of the 21 possible distinct events that can be dispatched during the operation of Ion, can be individually customizable with symbols (Unicode emojis), audio cues, volume, and messages.
Which events should have audio cues, at what volume, etc., will be a personal decision based on the experience that you are trying to create for your persona. Here's how you can customize an event:
event:
listening-and-waiting:
symbol: 🎧
message: Listening and waiting for a wake word.
audio: assets/audio/clue.wav
volume: 1Symbols (Unicode emojis) and messages are used in the logs of Ion. Audio and volume settings are used for playing audio files, which can be in WAV, OGG, or MP3 formats.
You can adjust the individual volumes for each event to normalize the varying levels of audio. The recommendation is to not have volumes above 1.0, as this may create distortion in the audio on some speakers. Ideally, set your highest volume at or below 1.0, and reduce the others accordingly to maintain balance.
The welcome-message-booted can be used to play a welcome message using text-to-speech:
---
events:
welcome-message-booted:
symbol: 👋
message: Welcome to Ion!
speak: true
volume: 1The speaking-started event can be used to set the volume of the text-to-speech answer audios:
---
events:
speaking-started:
symbol: 🔊
message: 'Starting to speak:'
volume: 0.8Ion performs well using simple headphones and a microphone. For open environments, you may want to consider investing in speakers that will provide the audio experience you are seeking and, specifically, a microphone appropriate for open spaces, such as an omnidirectional one or those designed for conference rooms.
Before running pip install -r requirements.txt, you need to create a Python virtual environment:
python3 -m venv env
source env/bin/activateCheck out Python on Raspberry Pi.
To display Unicode emojis in console terminals on a Raspberry Pi, you need to install a font that supports Unicode emojis:
sudo apt-get install fonts-noto-color-emojiYou need to restart the Raspberry Pi to see the results.
If you connect a speaker to your computer using a jack plug, you might experience issues with audio inactivity which can lead to hearing "static noise." On Linux, you can fix this by:
/etc/modprobe.d/alsa-base.conf
options snd_hda_intel power_save=0 power_save_controller=N
/etc/pulse/daemon.conf
exit-idle-time = -1Update the template.md file and then:
bb tasks/generate-readme.cljTrick for automatically updating the README.md when template.md changes:
sudo pacman -S inotify-tools # Arch / Manjaro
sudo apt-get install inotify-tools # Debian / Ubuntu / Raspberry Pi OS
sudo dnf install inotify-tools # Fedora / CentOS / RHEL
while inotifywait -e modify template.md; do bb tasks/generate-readme.clj; doneTrick for Markdown Live Preview:
pip install -U markdown_live_preview
mlp README.md -p 8076We are committed to making Ion accessible. If you face any accessibility issues or have recommendations for improvement, please feel free to fill out an issue!
1.1.0
I have been trying (and failing) to build this for over a decade, and we finally have all the core pieces of the puzzle to make it possible at the level I envisioned:
- Voice User Interface
- Speech-to-Text
- Text-to-Speech
- Keyword Spotting
- Conversational User Interface
- Large Language Models
- Function Calling
- Hardware
- IoT
These six ingredients make the magic happen, and beyond this point, it's all about continuing to improve the underlying technology and build on top of it. The puzzle for the first chapter has been solved, and although this is probably just an early glimpse of what the future holds for us, I'm thrilled about the possibilities.
That being said, over the years of my attempts, I want to acknowledge three main projects that along the way gave me hope for the future:
This is an experimental, early-stage project. Ion may be dangerous, so be careful with what you try to build; it could execute destructive actions on your computer. Also, be mindful of your budget: Ensure you monitor and budget for whatever provider you are using. Ion may produce unexpectedly lengthy content or infinite/too-long loops that could cause your costs to skyrocket.
This software is distributed under the MIT License, which includes a disclaimer of warranty. Furthermore, the authors assume no responsibility for any damage or costs that may arise from the use of this experimental, early-stage project. Use Ion at your own risk.