![]()
![]()

Kagome is an open source Japanese morphological analyzer written in pure golang.
The dictionary/statistical models such as MeCab-IPADIC, UniDic (unidic-mecab) and so on, are able to be embedded in binaries.
Note
Improvements from v1
- Dictionaries are maintained in a separate repository, and only the dictionaries you need are embedded in the binary.
- Brushed up and added several APIs.
| dict | source | package |
|---|---|---|
| MeCab IPADIC | mecab-ipadic-2.7.0-20070801 | github.com/ikawaha/kagome-dict/ipa |
| UniDIC | unidic-mecab-2.1.2_src | github.com/ikawaha/kagome-dict/uni |
Note
IPADIC is MeCab's so-called "standard dictionary" and is characterized by its ability to split morphological units more intuitively than UniDIC. In contrast, UniDIC breaks phrases into smaller example sentence units to create metadata for full-text search. For more details, see the wiki.
-
Experimental Features
dict source package mecab-ipadic-NEologd mecab-ipadic-neologd github.com/ikawaha/kagome-ipa-neologd Korean MeCab mecab-ko-dic-2.1.1-20180720 github.com/ikawaha/kagome-dict-ko
Similar to Kuromoji, Kagome also supports segmentation modes that enable various segmentations.
- Normal: Regular segmentation
- Search: Use a heuristic to perform additional segmentation that is useful for search purposes
- Extended: Similar to search mode, but also unknown words with uni-grams
| Untokenized | Normal | Search | Extended |
|---|---|---|---|
| 関西国際空港 | 関西国際空港 | 関西 国際 空港 | 関西 国際 空港 |
| 日本経済新聞 | 日本経済新聞 | 日本 経済 新聞 | 日本 経済 新聞 |
| シニアソフトウェアエンジニア | シニアソフトウェアエンジニア | シニア ソフトウェア エンジニア | シニア ソフトウェア エンジニア |
| デジカメを買った | デジカメ を 買っ た | デジカメ を 買っ た | デ ジ カ メ を 買っ た |
package main
import (
"fmt"
"strings"
"github.com/ikawaha/kagome-dict/ipa"
"github.com/ikawaha/kagome/v2/tokenizer"
)
func main() {
t, err := tokenizer.New(ipa.Dict(), tokenizer.OmitBosEos())
if err != nil {
panic(err)
}
// wakati
fmt.Println("---wakati---")
seg := t.Wakati("すもももももももものうち")
fmt.Println(seg)
// tokenize
fmt.Println("---tokenize---")
tokens := t.Tokenize("すもももももももものうち")
for _, token := range tokens {
features := strings.Join(token.Features(), ",")
fmt.Printf("%s\t%v\n", token.Surface, features)
}
}output:
---wakati---
[すもも も もも も もも の うち]
---tokenize---
すもも 名詞,一般,*,*,*,*,すもも,スモモ,スモモ
も 助詞,係助詞,*,*,*,*,も,モ,モ
もも 名詞,一般,*,*,*,*,もも,モモ,モモ
も 助詞,係助詞,*,*,*,*,も,モ,モ
もも 名詞,一般,*,*,*,*,もも,モモ,モモ
の 助詞,連体化,*,*,*,*,の,ノ,ノ
うち 名詞,非自立,副詞可能,*,*,*,うち,ウチ,ウチ- For more examples, see the examples directory.

-
Go
go install github.com/ikawaha/kagome/v2@latest -
Homebrew
# macOS and Linux (for both AMD64 and Arm64) brew install ikawaha/kagome/kagome
-
Docker
- See the Docker section below
-
Manual Install
- For manual installation, download and extract the appropriate archived file for your OS and architecture from the releases page.
- Note that the extracted binary must be placed in an accessible directory with execution permission.
$ kagome -h
Japanese Morphological Analyzer -- github.com/ikawaha/kagome/v2
usage: kagome <command>
The commands are:
[tokenize] - command line tokenize (*default)
server - run tokenize server
lattice - lattice viewer
sentence - tiny sentence splitter
version - show version
tokenize [-file input_file] [-dict dic_file] [-userdict user_dic_file] [-sysdict (ipa|uni)] [-simple false] [-mode (normal|search|extended)] [-split] [-json]
-dict string
dict
-file string
input file
-json
outputs in JSON format
-mode string
tokenize mode (normal|search|extended) (default "normal")
-simple
display abbreviated dictionary contents
-split
use tiny sentence splitter
-sysdict string
system dict type (ipa|uni) (default "ipa")
-udict string
user dict% # interactive/REPL mode
% kagome
すもももももももものうち
すもも 名詞,一般,*,*,*,*,すもも,スモモ,スモモ
も 助詞,係助詞,*,*,*,*,も,モ,モ
もも 名詞,一般,*,*,*,*,もも,モモ,モモ
も 助詞,係助詞,*,*,*,*,も,モ,モ
もも 名詞,一般,*,*,*,*,もも,モモ,モモ
の 助詞,連体化,*,*,*,*,の,ノ,ノ
うち 名詞,非自立,副詞可能,*,*,*,うち,ウチ,ウチ
EOS% # piped standard input
echo "すもももももももものうち" | kagome
すもも 名詞,一般,*,*,*,*,すもも,スモモ,スモモ
も 助詞,係助詞,*,*,*,*,も,モ,モ
もも 名詞,一般,*,*,*,*,もも,モモ,モモ
も 助詞,係助詞,*,*,*,*,も,モ,モ
もも 名詞,一般,*,*,*,*,もも,モモ,モモ
の 助詞,連体化,*,*,*,*,の,ノ,ノ
うち 名詞,非自立,副詞可能,*,*,*,うち,ウチ,ウチ
EOS% # JSON output
% echo "猫" | kagome -json | jq .
[
{
"id": 286994,
"start": 0,
"end": 1,
"surface": "猫",
"class": "KNOWN",
"pos": [
"名詞",
"一般",
"*",
"*"
],
"base_form": "猫",
"reading": "ネコ",
"pronunciation": "ネコ",
"features": [
"名詞",
"一般",
"*",
"*",
"*",
"*",
"猫",
"ネコ",
"ネコ"
]
}
]echo "私ははにわよわわわんわん" | kagome -json | jq -r '.[].pronunciation'
ワタシ
ワ
ハニワ
ヨ
ワ
ワ
ワンワンStart a server and try to access the "/tokenize" endpoint.
% kagome server &
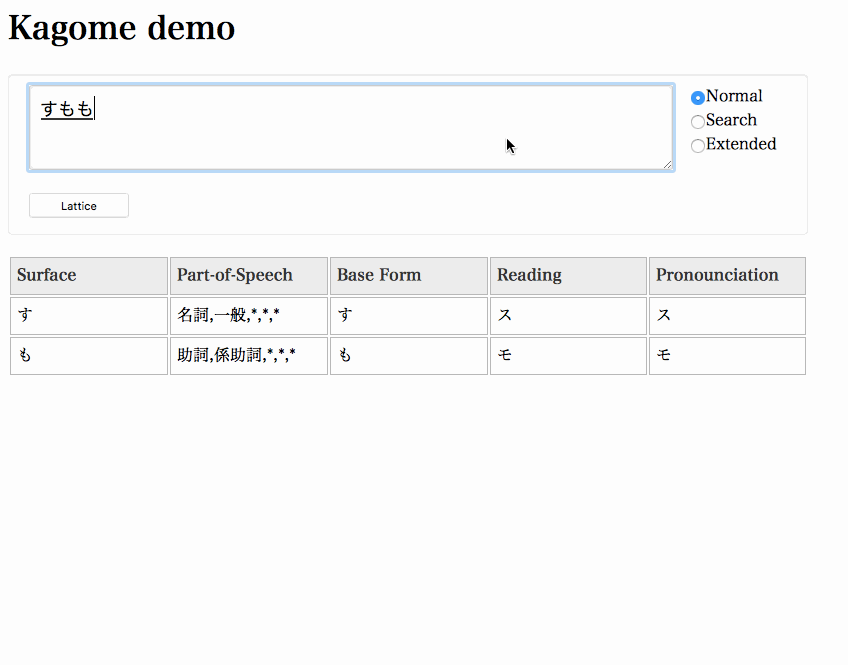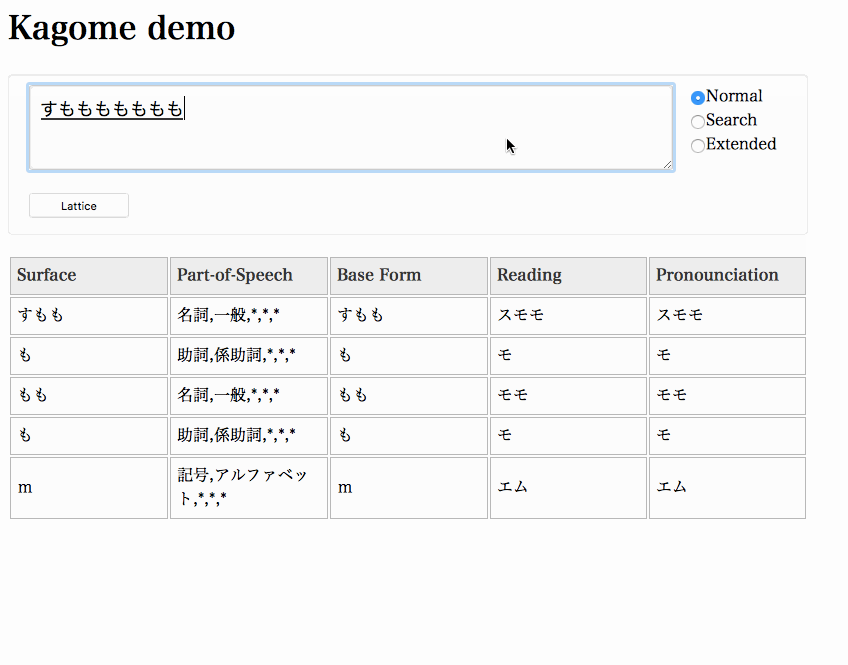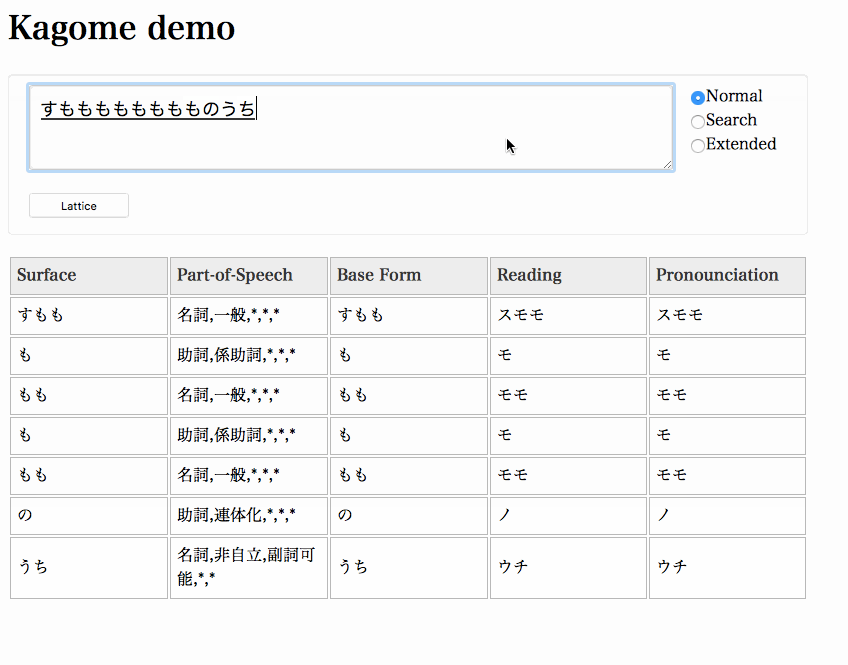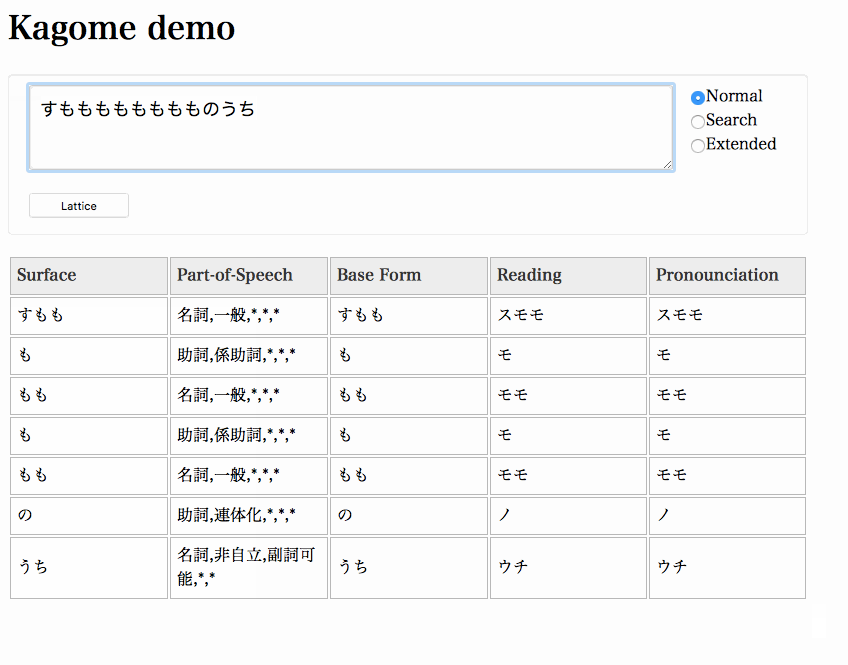
% curl -XPUT localhost:6060/tokenize -d'{"sentence":"すもももももももものうち", "mode":"normal"}' | jq .Start a server and access http://localhost:6060 in your browser.
% kagome server &Important
The demo web application uses graphviz to draw a lattice. You need graphviz to be installed on your system.
Tip
Kagome can be compiled to WebAssembly (wasm) and run locally in a web browser. For details, see the WebAssembly section.
- Wasm Demo: https://ikawaha.github.io/kagome/
A debug tool of tokenize process outputs a lattice in graphviz dot format.
% kagome lattice 私は鰻 | dot -Tpng -o lattice.png

# Compatible architectures: AMD64, Arm64, Arm32 (Arm v5, v6 and v7)
docker pull ikawaha/kagome:latest
# Alternatively, you can pull from GitHub Container Registry
docker pull ghcr.io/ikawaha/kagome:latest# Interactive/REPL mode
docker run --rm -it ikawaha/kagome:latest
# If pulling from GitHub Container Registry
docker run --rm -it ghcr.io/ikawaha/kagome:latest# Server mode (http://localhost:6060)
docker run --rm -p 6060:6060 ikawaha/kagome:latest server
# If pulling from GitHub Container Registry
docker run --rm -p 6060:6060 ghcr.io/ikawaha/kagome:latest serverKagome can be compiled to WebAssembly (wasm) and run in a web browser.
You can see how kagome wasm works in the demo site. The source code can be found in ./_examples/wasm.
- MIT