This repository contains the same agent interface for playing the Enduro game as the one you used in coursework 1, however the sensing capabilities of the agent have been extended. Instead of just sensing the environment grid, the agent can now sense the road and the others in pixel coordinates as well as its own speed. The main difference is in the sense function which now has the following prototype:
def sense(self, road, cars, speed, grid)
These new sensory signals will help you quickly construct more complex state spaces, compared to the ones based only on the environment grid, which you may need for the function approximation based agent.
The road grid is 2-dimensional array which contains [x, y] points in pixel coordinates corresponding to the corners of the road cells used to construct the environment gird. Those are the cooridnates used to draw the white grid on top of the road in the game frames. There are 11x10 cells in the environment grid and so there are 12x11 points stored in the road grid. The first dimension of the road grid corresponds to the horizontal lines while the second dimension correspondes to the intersection points along a horizontal line. Thus, if you would like to access the pixel cooridinates of the top left corner of the furhtest leftmost road cell you would have to access road[0][0].
The cars argument is a dictionary which contains two keys 'self' and 'others'. cars['self'] returns a rectangle as a tuple (x, y, w, h) which represents the agent location and size in the game frame. x, y are the top-left corner pixel coordinates of the rectangle and its size is w, h. cars['self'] is visualised as the green rectangle overlayed on the game frame. cars['others'] is a list of tuples which countains the same information for each opponent present. If there are no opponents on the road, then cars['others'] is an empty list. The information in cars['others'] is visualised as red rectangles around the opponent.
This is a single scalar in the range [-50, 50] which represents the speed of the agent relative to the opponents. Thus -50 means that the agent has just collided and 50 means that the agent is moving as fast as possible.
The grid argument is the same environment grid that you have already used during the first coursework.
The example agent uses 9 features:
- Positive relative speed
- Negative relative speed
- Potential collision
- Avoid opponent on the left
- Avoid opponent on the right
- Avoid opponent in front
- Accelerate when no potential collision
- Move to the center of the road from the left edge
- Move to the center of the road from the right edge
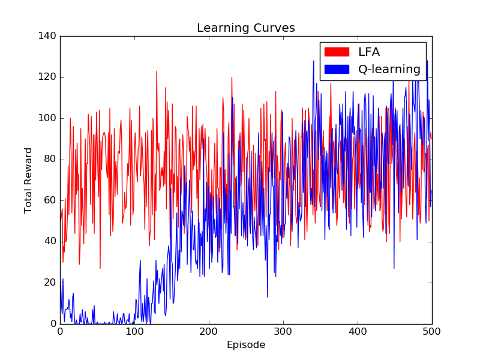
As you can see there are features which depend just on the state, just on the action and on both as well. If you run the agent you should obtain similar performance to the one bellow. The LFA agent performs much better than the Q-learning agent in the initial stages of learning. Eventlually, Q-learning achieves slightly better performance.
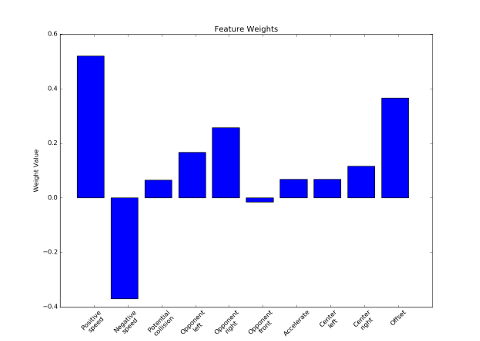
The most significant weights correspond to greater relative velocity, followed by avoiding opponents on the right and left. Interestingly, the least significant feature is avoiding opponents in front. The most likely reason is due to the fact that avoiding frontal agents is quite stochastic and often results in collisons.
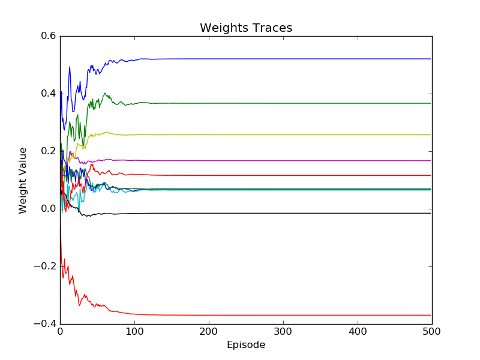
Finally, due to the fast convergence and noisy behaviour of the LFA agent it is a good idea to inspect the weight traces over learning. As you can see the agent clearly converges after 100 episodes.
You can inspect the results with:
python plot_log.py