hi ,tThank you for sharing. Now I have some problems and want to ask you. The code runs to this step, but I don’t know where the problem is. Can you explain it to me, thank youhanksyou
Opened this issue · 15 comments

You can see that my global step is always 0, and the loss is also 0
epoch loss should not be zero, please check the tensorflow version you are using
Please use tensorflow-gpu 1.15
Set "ImageLog": true, in config.json, start tensorboard to check if the images are loaded properly
Please check if your data is loaded properly
1:The first is why some slices are discarded when reading slices, as shown in the program 2:The second question is loss. When using mixed loss, why the parameter alpha only constrains one of the losses, and when alpha=1, it means whether this parameter is redundant Hope to hear from you, thank you
-
If you are specifying 2D segmentation cases, the occurence rate of empty label slice may affect training results. I have set a probability to discard part of the slices to gaurantee the training slices contains certain size of segmentation labels. E.g. A CT scan may only contain few pixels across few slices out of thousands of scanning images, the training will be easily dominated by zero labels as you hardly let the model access to pixels with desired regions.
-
The regularization only need to constrain on cross entropy loss as DICE loss is bounded in [0,1]. Alpha is to restrict the percentage of contribution during loss optimization. This factor is subjected to your dataset, setting alpha = 1 is an arbitary choice. To test regularization parameter, you may conduct trial to obtain testing score across different alpha values, e.g.:
This plot indicates best model performance with alpha = 0.01562, whereas a robust alogrithm/ dataset would have less disperse test scores:

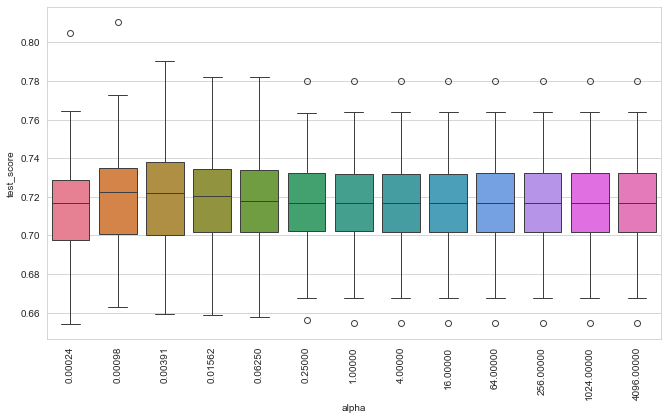
@liuzhiwei1997 You need to adjust alpha and weight to get optimal results. You may observe DICE and cross entropy loss in tensorboard to check if they are in samiliar order of magnitude. For class weight in weighted sorensen loss, it is advise to count 0 labeled segmentation pixels (background) to actual segmentation labels. Usually 0 to 1 label ratio can up to thousands to one.
For quick hyperparameter tuning you may check Guild AI