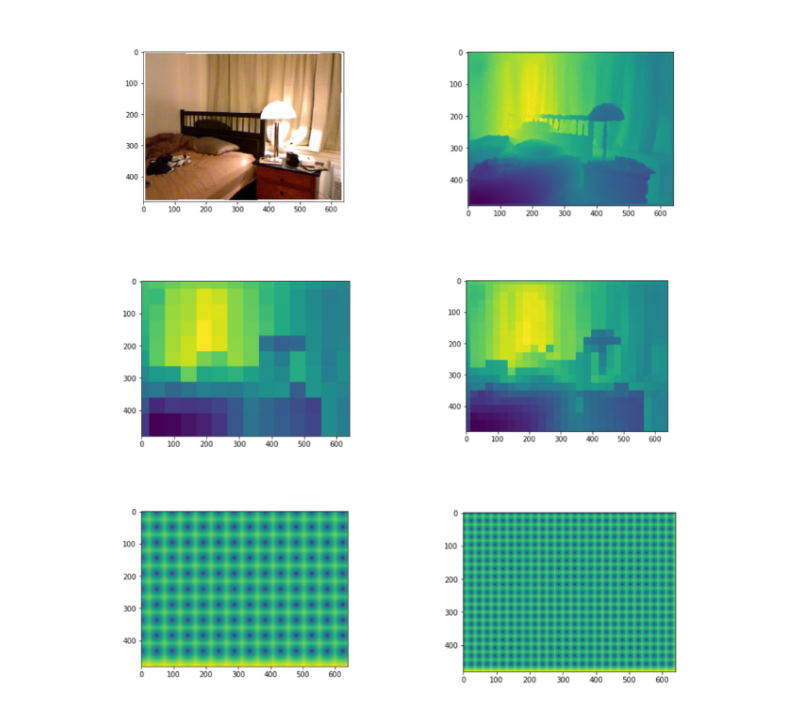
A a deep model that can accurately produce dense depth maps given an RGB image with known depth at a very sparse set of pixels.
Paper: https://arxiv.org/pdf/1804.02771v2.pdf
The train directory contains the training code to be run.
Monocular depth sensing has been a barrier in computer vision in recent years. This project is based on Estimating Depth from RGB and Sparse Sensing paper, where we create a network architecture that proposes an accurate way to estimate depth from monocular images from the NYU V2 indoor depth dataset. This model can use very sparse depth information (~ 1 in 1000 pixels) to predict full resolution depth information. It can simultaneously outperform all current cutting edge monocular depth classifiers for both indoor and outdoor scenes. If a sparsity of ~ 1 in 256 pixels is used, we can reduce the relative error to less than 1%, which is due to the use of the residual convolutional neural network structure in conjunction with the encoder-decoder model.
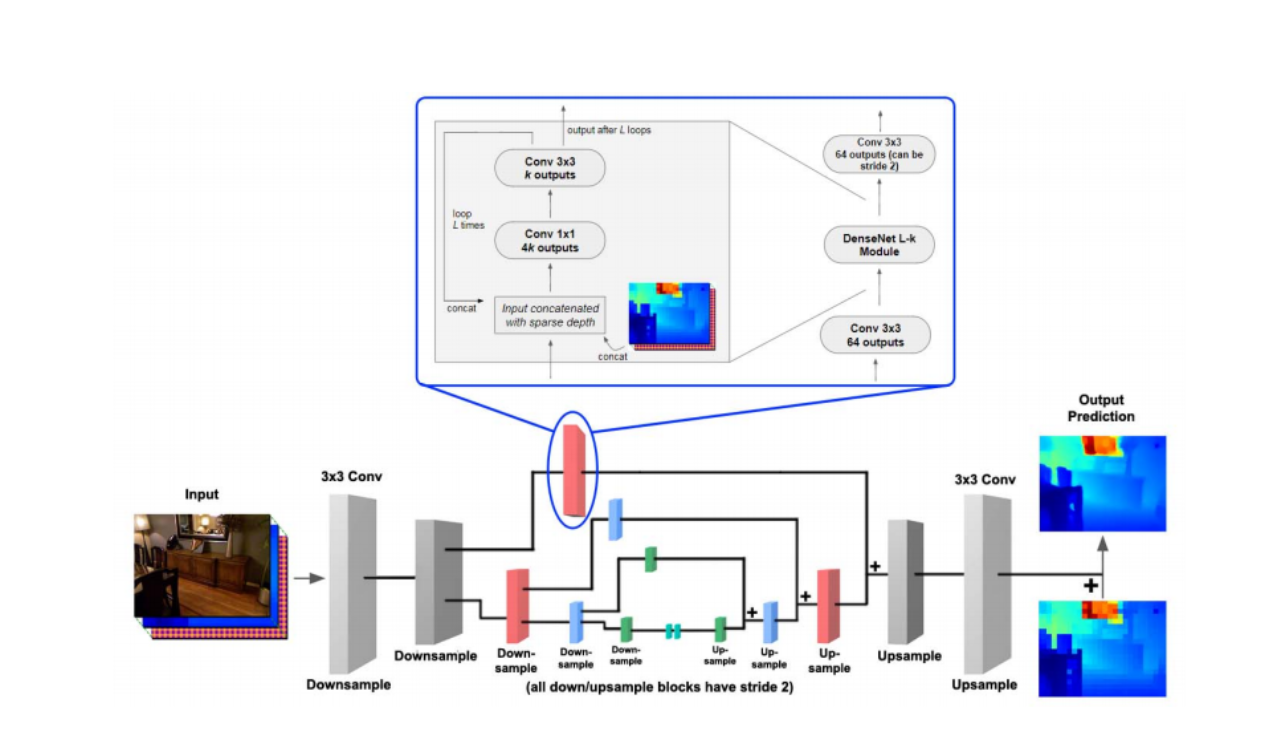
The experiments in this project indicate that it is probable to create accurate depth data using a low powered consumer-grade depth sensor (like the Kinect) to create high-resolution depth images with comparable accuracy to older laser mapping technologies whilst being highly cost-effective solution.
The Dataset used was the NYU Depth V2 Dataset using the provided 1449 labeled RGB and depth images.