爬取多家笔趣阁网站(笑),使用MongoDB存储小说信息,建立倒排索引以便进行搜索,最后基于Django建立Web服务。实现搜索全网小说并可一键下载。
这是一个非常基础的搜索引擎,Django框架前端代码等均为完成课设速成,并无健壮性,亟待优化。
Actually This is only a naive search engine for my homework!!:joy:
- 利用开源的网页爬虫或者自己开发的网页爬虫,爬取一定数目的网页(✔)
- 对网页进行必要的去噪,预处理工作(✔)
- 采用Lucene等全文检索工具包对数据建立倒排索引,并能提供检索服务;(✔)
- 返回给用户的应该是一个经过相关性排序的结果列表(✔)
- 最好使用第三方中文分词接口(✔)
- 必要的预处理工作(✔)
- 中文:分词、停用词过滤。 英文:大小写转化(Case insensitive)、词干化(Stemming)、停用词过滤(✔)
- 结果高亮显示(×)(待更新)
- Scrapy
- Whoosh
- MongoDB
- Django
- Jieba
-
运行
BookSpider/Run.py或者在BookSpider路径下命令行运行指令Scrapy Crawl biquge,即可开始爬取笔趣阁小说信息并存入MongoDB。注意:为了缩短爬虫运行时间和使用更少的存储空间,这里分别建立了爬取小说信息爬虫
BookSpider和单本小说下载爬虫SingleBookSpider,仅在需要的情况下爬取特定小说内容进行下载。 -
需要数据库MongoDB,数据存储在
http://127.0.0.1:8000/,数据库名为NovelDataBase,数据表名为biquge。 -
运行
SearchService/build_index.py建立索引,运行SearchService/Search.py可以使用搜索功能。 -
在
SearchWeb路径下运行指令Python manage.py runserver。 打开浏览器127.0.0.1:8000/search即可。
- 搜索页面展示
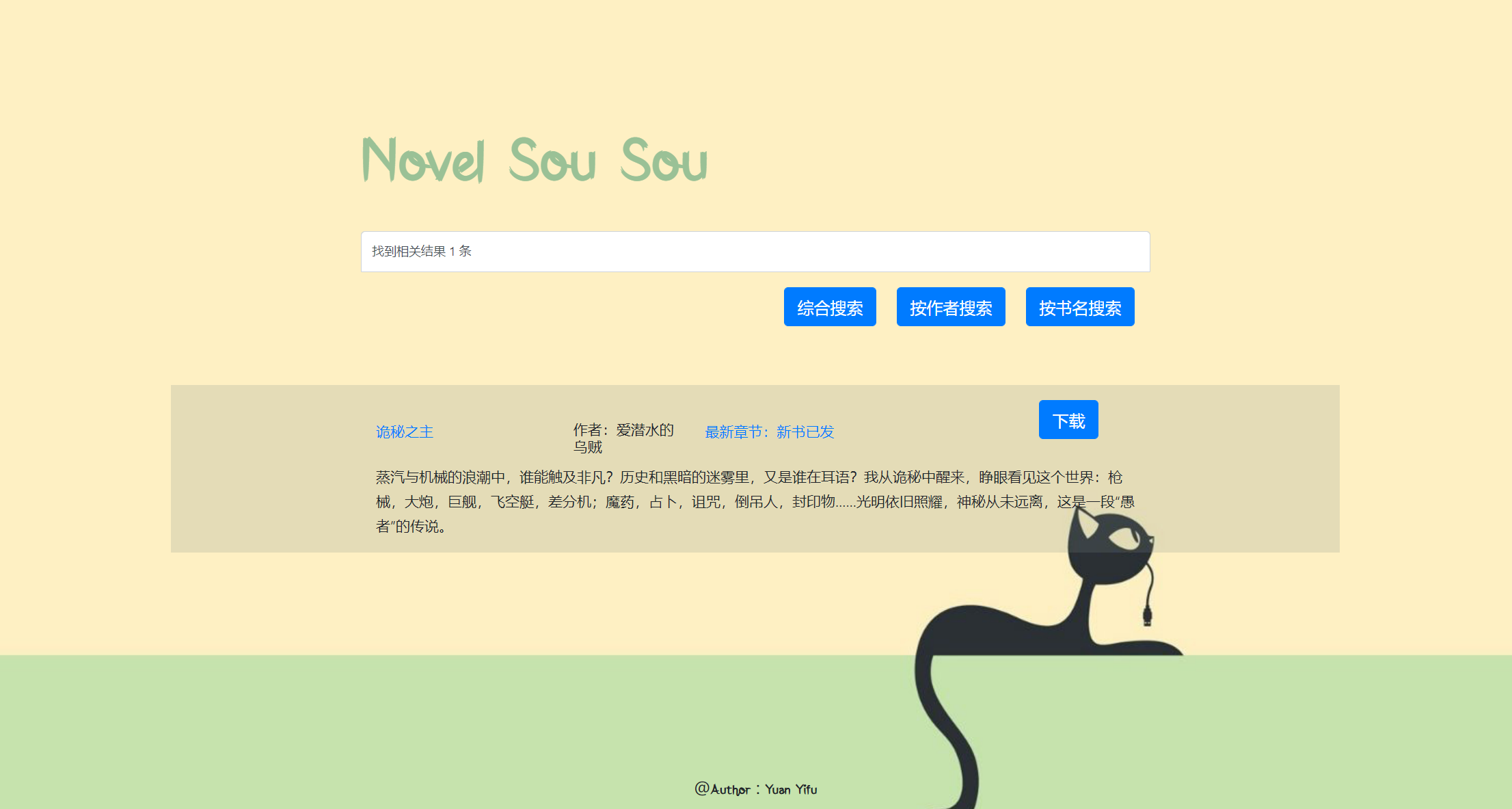
- 结果界面展示
-
爬取小说信息爬虫
BookSpider存储内容如下:class BookspiderItem(scrapy.Item): # define the fields for your item here like: # name = scrapy.Field() novel_name = scrapy.Field() # 小说名称 novel_url = scrapy.Field() # 小说链接 novel_author = scrapy.Field() # 小说作者 novel_introduction = scrapy.Field() # 小说简介 novel_update_last_time = scrapy.Field() # 最新章节更新时间 novel_update_last_url = scrapy.Field() # 最新章节链接 novel_update_last_name = scrapy.Field() # 最新章节名
爬取单本小说详细章节内容爬虫
SingleBookSpider存储内容如下:class SinglebookspiderItem(scrapy.Item): # define the fields for your item here like: # name = scrapy.Field() chapter_name = scrapy.Field() # 章节名 chapter_content = scrapy.Field() # 章节内容 chapter_index = scrapy.Field() # 章节索引
爬虫信息存储和单本小说爬取效果如下:
MongoDB
随机下载一本小说到本地
-
建立倒排索引使用了完全基于Python的Whoosh库。Whoosh纯由Python编写而成,是一个灵活的,方便的,轻量级的搜索引擎工具。为了处理小说章节内容,这里使用的分词器为Jieba库中的ChineseAnalyzer。建立索引内容如下,其中书名、作者、简介应用分词器:
Index Index name Item type 编号(自动生成) novelID ID 书名 novelName TEXT 作者 novelAuthor TEXT 链接 novelUrl ID 简介 novelIntroduction TEXT 更新时间 novelUpdateTime TEXT 更新链接 novelUpdateUrl ID 更新章节名 novelUpdateName TEXT 建立索引之后可以通过Whoosh中的Searcher对象对索引使用合适的方式检索,这里提供了三种方式:
- 按书名检索(NovelName)
- 按作者名检索(NovelAuthor)
- 综合检索(NovelName、NovelAuthor、NovelIntroduction)
索引解析后使用Whoosh自带的打分系统进行相关性排序
scores = sorting.ScoreFacet()
-
基于Django框架建立了网站的Web服务,即最终界面显示,前端界面使用了BootStrap4框架的CDN,其中核心页面显示在
Search.html(搜索引擎主页),Result.html(搜索结果显示页),以及格式化内容Search.css,其中Result.html继承Search.html,并使用block的方式动态更新显示内容。具体实现逻辑如下:点击按钮“按作者搜索”“按书名搜索”“综合搜索”的任何一个,即获取当前输入框内容,以
POST方式传递到绑定的search函数中进行搜索服务,并将搜索获得的结果使用block显示到新的result.html界面,完成一次搜索过程。点击对应条目的下载按钮即可运行爬虫,下载对应书籍到本地。下面是
Result.html{% extends "SearchNovel/search.html" %} {% block search %}找到相关结果 {{results_num}} 条{% endblock %} {% block content %} {% for key in results %} <div class="container"> <div class="row clearfix"> <div class="col-md-12 column"> <div class="row clearfix"> <div class="col-md-3 column"> <a href="{{key.novelUrl}}" class="package-name" style="font-size: 14px">{{key.novelName}}</a> </div> <div class="col-md-2 column"> <h1 style="font-size: 14px">作者:{{key.novelAuthor}}</h1> </div> <div class="col-md-5 column"> <a href="{{key.novelUpdateUrl}}" style="font-size: 14px">最新章节:{{key.novelUpdateName}}</a> </div> <div class="col-md-2 column"> {% csrf_token %} <button type="submit" class="btn btn-primary" name="{{key.novelUrl}}">下载</button> </div> </div> <div class="row clearfix"> <div class="col-md-12 column"> <h class="package-description" style="font-size: 14px">{{key.novelIntroduction}}</h> <br> </div> </div> </div> </div> </div> {% endfor %} {% endblock %} {% block download %}<h1 style="font-size: 20px">{{results_download}}</h1> {% endblock %}


- 爬取小说时会被多次重定向,导致下载速度过慢,或者使用多线程
- 修改前端的一些BUG