Check this repo out on Github if you aren't already: https://github.com/prasuchit/Policy-Iteration-using-MDP This repository implements the movement of a UAV in a Gridworld as a Markov Decision Process and performs policy iteration to find the best action in each state.
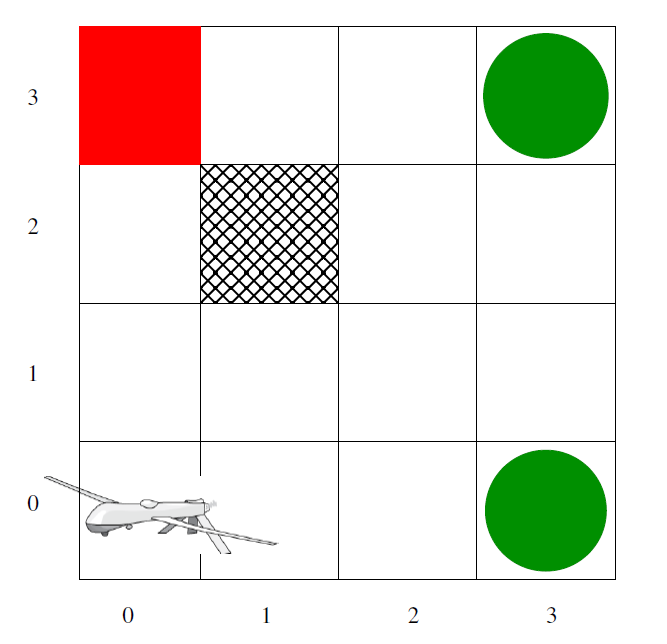
- There are 16 possible states in the grid numbered (0-15)
- There are 4 possible actions that the UAV can perform in each state: North, East, West, South.
- The reward for entering a green state, which is at 3,3 (index starting from 0) and at 3,0 is +1.
- The reward for entering a red state, which is at 0,3 is -1 and all the other states have a cost of -0.05.
- The cost of entering a blocked state(1,2) is -0.5.
- The transition probability in the intended direction upon performing an action is 0.85.
- The remaining 0.15 is divided equally among the two perpendicular directions of intended direction.
We begin with a random policy that we assume(A policy is a mapping between each state and the action to be performed in that state. We perform two steps to implement policy iteration:
- Policy Evaluation
- In this we find the value of all possible next states given the current state and action defined by the policy and we find the difference between the initially assumed value(we start with zero) and the value obtained after the Bellman update and compare it with a defined error value epsilon(we start with zero).
- If the difference of any state value(after Bellman update) from the initial value we had is greater than the error we already have, we update the error value.
- Finally we check if the error value we have among all our states is below a threshold and we quit the loop if this is true; else we run policy evaluation again.
- Policy Improvement - The only difference here is that in each state we iterate through all possible actions instead of sticking to the one action defined by the policy and check the max value produced. We update that action as the policy action and move on to the next state. - As long as our starting action (before the bellman update) and the final action obtained are different in even one state, we keep running policy improvement.
Then finally, before returning the policy, we do policy evaluation one more time to ensure the error is below threshold and then return the optimal policy.
- I used Visual Studio code with the C++ plugin enabled and MinGW and cygwin64 to implement the C++ program. The Transition matrix, reward matrix and number of states and actions are built into the code. However, we could load these from an external file in the future if need be.
- You could use any C++ compiler/IDE combination to run this as this code doesn't use any fancy libraries to implement the MDP.
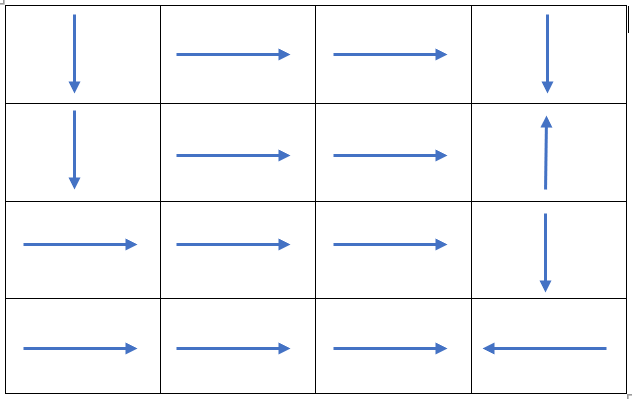
- With the actions mapping being {0, 1, 2, 3} corresponding to {'N','E','W','S'}; The output policy generated by the code is: 1112111331103113, which depicts the following policy: